에이전트 옵저버빌리티 - AI 에이전트의 '조용한 실패'를 잡는 법

AI 에이전트를 업무에 도입하는 조직이 늘고 있습니다. 그러나 운영을 맡은 입장에서는 다음과 같은 곤란한 상황을 마주할 수 있는데요. 에이전트가 이상하게 동작해도 모니터링 대시보드에 포착되지 않거나, 로그를 아무리 뒤져도 에이전트가 왜 그렇게 판단했는지 확인하기 어려운 게 그 예죠.
에이전트의 실패는 호출 하나가 아니라 여러 판단 경로에서 발생합니다. 이 경로를 기록해 '무엇을, 왜 했는지'를 재구성하고, 평가와 개선까지 잇는 기술이 있는데요. 바로 ‘에이전트 옵저버빌리티(agent observability)’입니다.
이 글에서는 에이전트 옵저버빌리티의 개념과 동작 방식, APM·LLM 옵저버빌리티와의 차이, 구현 도구를 살펴보고요. Langfuse와 Google Gemini로 PR 리뷰 에이전트의 활동을 직접 추적·평가하는 실습을 다룹니다. 아울러 에이전트 옵저버빌리티를 원활하게 운영하기 위해 유념할 사항도 살펴봅니다.
에이전트 옵저버빌리티란 무엇이고, 왜 중요할까?
에이전트 옵저버빌리티(agent observability)의 개념과 동작 방식을 알아보고, APM·LLM 옵저버빌리티와의 차이점과 구현 도구를 살펴본 뒤, 왜 지금 이것이 중요한지 짚어보겠습니다.
에이전트 옵저버빌리티란?
에이전트 옵저버빌리티는 에이전트가 작업을 수행하며 거친 모든 단계(추론, 도구 호출, 상태 변경, 메모리 읽기·쓰기)를 기록하고, '에이전트가 무엇을, 왜 했는지'를 나중에 그대로 재구성하도록 지원하는 기술입니다. 기록은 에이전트 코드에 옵저버빌리티 도구의 SDK를 심어 두면, 에이전트가 실행될 때마다 자동으로 남는데요. 이로써 에이전트 활동의 결과만 남기지 않고, 결과에 이르는 경로까지 추적해 기록하죠. 단, 에이전트 옵저버빌리티는 '활동 기록'으로만 끝나지 않고요. 이 내용을 평가하고, 실제 에이전트 개선으로 이어지도록 지원합니다.
구체적인 동작 방식은 다음과 같습니다.

- 에이전트 실행: 에이전트가 작업을 수행합니다.
- 트레이스 수집: 작업 실행의 각 단계가 하나의 트레이스(trace) 안에 기록됩니다. 트레이스는 에이전트 한 번의 실행 전체를 담은 기록 단위로, 그 안에 각 판단과 도구 호출이 단계별로 남습니다.
- 평가: 트레이스에 점수를 매겨 품질을 측정합니다. 점수 기준은 에이전트의 과업에 따라 정합니다. 예를 들어, PR 리뷰 에이전트라면 '치명적 버그를 놓치지 않았는가', '지적이 실제 코드에 근거하는가' 같은 항목이 기준이 되죠. 점수는 프로덕션에서 흐르는 트레이스에 실시간으로 매기거나(온라인 eval), 모아둔 데이터셋의 입력을 에이전트로 실행해 그 결과에 매기기도 합니다(오프라인 eval). 채점 방법에는 모델이 모델을 심사하는 LLM-as-judge, 사람이 직접 매기는 주석, 규칙으로 판정하는 코드 평가자(code evaluator)가 있습니다.
- 데이터셋 누적: 낮은 점수를 받은 실패를 평가 케이스로 수집합니다. 이렇게 하면 실제 운영에서 발생한 실패가 곧 테스트 케이스가 되죠. 운영 기간이 늘어날수록 평가 목록도 실전 사례로 풍부해집니다.
- 개선: 위 데이터셋에서 드러난 실패 원인에 맞춰 프롬프트·모델·도구 구성을 수정합니다.
- 실험·배포 게이트: 수정한 에이전트를 데이터셋으로 다시 실행해 수정 전과 점수를 비교하는 실험을 돌리고, 이를 배포하기 전 검사 기준으로 삼습니다. 수정한 에이전트가 같은 실수를 되풀이하면 배포하기 전 검사에서 회귀(regression)로 포착되죠. 이로써 실패가 사용자에게 다시 도달하기 전에 포착돼 문제를 개선할 수 있습니다. 검사를 통과한 에이전트는 다시 1번으로 돌아가 작업을 수행하며 전체 과정을 순환합니다.
APM·LLM 옵저버빌리티와 무엇이 다른가?
에이전트 옵저버빌리티는 기존의 APM(Application Performance Monitoring)이나 LLM 옵저버빌리티와 혼동하기 쉽습니다.
셋을 구분하는 핵심은 '무엇을 관측 단위로 보느냐'인데요. APM은 서비스와 요청을, LLM 옵저버빌리티는 개별 모델 호출을, 에이전트 옵저버빌리티는 여러 판단과 도구 호출이 이어지는 실행 전체를 하나의 관측 단위로 봅니다. 에이전트의 실패는 호출 하나만 봐선 알기 어려운데요. 이는 여러 단계를 거쳐 나타나기 때문에 실행 전체를 봐야 실패 원인을 정확히 파악할 수 있습니다.
APM, LLM 옵저버빌리티, 에이전트 옵저버빌리티의 차이점을 구체적으로 정리하면 다음과 같습니다.
| 구분 | APM | LLM 옵저버빌리티 | 에이전트 옵저버빌리티 |
|---|---|---|---|
| 관측 단위 | 서비스·요청 | 개별 모델 호출 | 다단계 실행(트레이스) 전체 |
| 보는 것 | 응답 코드·지연·처리량 | 프롬프트·응답·토큰·비용 | 추론 → 도구 호출 → 상태 전이 → 결과의 인과 사슬 |
| 답하는 질문 | "서비스가 살아 있나?" | "이 호출이 좋은 답을 냈나?" | "왜 그 결정을 했고, 어디서 어긋났나?" |
| 실패 발견 방식 | 200/500으로 성공·실패 | 호출 단위 품질 점검 | 단계 간 연쇄 실패·잘못된 도구·환각 추적 |
에이전트 옵저버빌리티는 어떤 도구로 구현하나?
에이전트 옵저버빌리티를 구현하는 도구는 다양합니다. 각 도구는 트레이스 깊이, 에이전트·도구 호출 가시성, 평가 지원(채점·데이터셋·실험), 배포 유연성(클라우드·셀프호스트)이 저마다 다르죠.
그러나 핵심 구분 지점은 오픈 소스, 상용 도구 여부인데요. 데이터를 사내에 둬야 하거나 직접 운영하고 싶다면 셀프호스트할 수 있는 오픈 소스 도구(Langfuse, Arize Phoenix)가, 특정 프레임워크 생태계나 CI/CD 평가 파이프라인과 결합이 우선이라면 상용 도구(LangSmith, Braintrust)가 사용하기에 적합합니다.
현재 업계에서 많이 쓰이는 도구를 추리면 다음과 같습니다(2026년 6월 기준).
| 도구 | 유형 | 특징 |
|---|---|---|
| Langfuse | 오픈 소스 | OpenTelemetry 기반, 트레이싱·평가·데이터셋 올인원. 2026년 1월 ClickHouse가 인수 |
| Arize Phoenix | 오픈 소스 | OpenTelemetry 기반, 환각·정확도·관련성 등 내장 평가 지표 제공, RAG 평가 강점 |
| LangSmith | 상용 | LangChain·LangGraph 생태계와 깊숙이 결합 |
| Braintrust | 상용 | 넉넉한 무료 한도, 강한 CI/CD eval 게이팅 |
에이전트 옵저버빌리티는 왜 지금 중요한가?
에이전트 옵저버빌리티가 중요한 이유는 에이전트의 실패를 기존 모니터링 방식으로는 탐지하기도, 진단하기도, 방지하기도 어렵기 때문입니다. 에이전트는 스스로 다단계로 판단하고, 비결정적으로 움직이며, 시스템 장애 없이 그럴듯하게 틀린 출력을 내는데요. 이러한 특성은 다음 문제를 일으킵니다.
1. 실패가 보이지 않습니다 (탐지의 문제)
서버가 죽으면 알림이 울리지만, 에이전트는 멀쩡히 정상 응답(HTTP 200)을 반환하면서 조용히 잘못된 답을 내놓죠. 일반적인 모니터링 방식으로 보면 ‘아무 문제 없는’ 상태인데요. 잘못된 출력은 사용자가 신고할 때까지 발견되지 않고, 비용 증가, 품질 저하, 신뢰 하락이라는 결과를 낳습니다. 에이전트 옵저버빌리티는 트레이스에 점수를 매겨 품질을 지표로 만들어 응답 코드가 아니라 출력의 품질로 실패를 가시화합니다.
2. 실패해도 원인을 찾기 어렵습니다 (진단의 문제)
에이전트의 실패는 호출 하나로 드러나지 않습니다. 1단계의 잘못된 판단은 3단계의 엉뚱한 도구 호출로, 다시 5단계의 환각으로 확산되는데요. 최종 출력만 봐선 어느 단계에서 어긋났는지 알 수 없죠. 에이전트 옵저버빌리티는 실행 경로를 단계별로 재구성해 ‘어느 단계에서, 왜 어긋났는지’를 보여줍니다.
3. 같은 실패가 반복됩니다 (예방의 문제)
실패를 발견하고 수정해도, 기록이 없으면 다음 수정에서 같은 실수가 반복돼도 이를 알아챌 방법이 없죠. 그러나 에이전트 옵저버빌리티는 실패한 트레이스를 평가 케이스로 묶어 배포하기 전 검사 기준으로 삼는데요. 그 결과, 한 번 잡은 실패가 사용자에게 다시 도달하기 전에 이를 탐지하고 걸러낼 수 있습니다.
‘에이전트가 어느 단계에서 실패했는지’를 답할 수 없다면, 그 에이전트는 프로덕션 수준이 아니며 파일럿 단계라고 볼 수 있습니다. 에이전트 옵저버빌리티는 이 질문에 답하는 필요 조건입니다.
실습: Langfuse로 'PR 리뷰 에이전트' 활동을 추적하고 평가하기
이제 Langfuse로 에이전트 옵저버빌리티를 구현하는 방법을 실습하겠습니다. 에이전트의 활동이 Langfuse에 어떻게 기록되는지 살펴보고 점수를 매긴 다음, 실패에 대비한 데이터셋도 만들어 봅니다.
이 실습은 무료 키 두 개(Langfuse, Google Gemini)로 진행했습니다. 에이전트의 판단은 실제 LLM(gemini-2.5-flash)이 수행해 트레이스에는 모델의 추론 경로가 남습니다.
단, 여러분이 같은 코드를 실행해도 트레이스는 이 글의 화면과 다를 수 있는데요. 이는 에이전트가 비결정적으로 활동하기 때문입니다.
이 실습으로 관측하는 것
실습의 주인공은 도구를 직접 호출하며 PR을 리뷰하는 에이전트입니다. 이 에이전트는 작은 가짜 저장소(메모리 안에만 존재)를 받아 다음과 같이 움직입니다.
list_changed_files로 변경된 파일을 확인합니다.- 필요하다고 판단한 파일의
get_diff·read_file을 호출해 내용을 읽습니다. - 버그·보안·품질 이슈를 정리하고 심각도(LOW/MED/HIGH)를 붙여 리뷰를 마칩니다.
무엇을 부르고 언제 멈출지 정하는 이 판단·호출 과정은 트레이스에 단계별로 남고, 사람은 그것을 관측·평가합니다. 에이전트의 실패는 호출 하나가 아니라 여러 판단의 경로에서 일어나는데요. 이 실습은 바로 그 경로를 들여다 봅니다.
Step 1. Langfuse 계정과 API 키 발급하기
- cloud.langfuse.com에 가입합니다. 가입한 주소가 곧 리전이며, 스크립트의
LANGFUSE_BASE_URL에 그대로 사용합니다. - 새 Organization → Project를 생성합니다.
- 프로젝트 Settings → API Keys → Create new API keys로 들어갑니다.
- Public Key와 Secret Key를 복사합니다.
Step 2. Gemini API 키 발급하기
에이전트의 두뇌 역할을 하는 LLM 키입니다. Google AI Studio에서 무료로 발급받을 수 있습니다.
- aistudio.google.com/apikey에 접속해 구글 계정으로 로그인합니다.
- API 키 만들기를 클릭합니다. 키를 담을 Google Cloud 프로젝트가 없다면 만들기 창에서 새 프로젝트를 만들어 선택합니다.
- 발급받은 키를 복사해 저장합니다.
Step 3. 실습 환경 준비하기
터미널에서 다음 명령을 한 줄씩 실행합니다(예시는 macOS·Linux 기준입니다).
# 1) 작업 폴더 만들기
mkdir agent-observability-demo && cd agent-observability-demo
# 2) 가상 환경 만들고 켜기
python3 -m venv venv
source venv/bin/activate
# 3) 필요한 패키지 설치
pip install langfuse google-genai
가상 환경이 켜지면 터미널 줄 맨 앞에 (venv)가 붙습니다.
Step 4. 에이전트 스크립트 붙여넣기
같은 폴더에 pr_review_agent.py 파일을 만들고 아래를 그대로 붙여 넣은 뒤, 맨 위 키 4줄만 본인 값으로 바꿉니다.
"""
PR 리뷰 에이전트 — 실제 LLM(Google Gemini, 무료 티어) 버전
============================================================
이 버전은 모델이 '실제로' 어떤 툴을 부를지 스스로 판단합니다.
따라서 트레이스에는 진짜 추론 과정이 남고, 그 판단을 정직하게 해석할 수 있습니다.
필요한 키:
- Langfuse 무료 키 (pk-lf-…, sk-lf-…)
- Gemini 무료 키 ← aistudio.google.com에서 카드 없이 발급
설치: pip install google-genai langfuse
"""
import os
import json
from google import genai
from google.genai import types
from langfuse import get_client
# ── 아래 4줄만 본인 값으로 채우세요 ──────────────────────────────
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-여기에_붙여넣기"
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-여기에_붙여넣기"
os.environ["LANGFUSE_BASE_URL"] = "https://cloud.langfuse.com" # 가입 리전 주소
GEMINI_API_KEY = "여기에_붙여넣기"
# ─────────────────────────────────────────────────────────────────
# 무료 티어 모델. 오류가 나면 "gemini-2.5-flash-lite"로 바꾸거나 공식 문서에서 최신 모델명을 확인하세요.
MODEL = "gemini-2.5-flash"
MAX_STEPS = 6 # 에이전트 루프 상한 (무한 루프 방지)
langfuse = get_client()
assert langfuse.auth_check(), "Langfuse 인증 실패 — 키와 리전(BASE_URL)을 확인하세요."
client = genai.Client(api_key=GEMINI_API_KEY)
# ── 에이전트가 조사할 '가짜 저장소' (메모리 안에만 존재) ──
CHANGED_FILES = ["billing.py", "README.md"]
REPO = {
"billing.py": (
"def total_price(items, discount):\n"
" subtotal = sum(i['price'] for i in items)\n"
" return subtotal / discount # discount=0이면 ZeroDivisionError\n"
),
"README.md": "# 결제 모듈\n사용법 문서를 업데이트했습니다.\n",
}
DIFFS = {
"billing.py": (
"+ def total_price(items, discount):\n"
"+ subtotal = sum(i['price'] for i in items)\n"
"+ return subtotal / discount # discount 검증 없음\n"
),
"README.md": "+ 사용법 문서를 업데이트했습니다.\n",
}
# ── 에이전트가 호출할 수 있는 툴 선언 ──
TOOLS = types.Tool(function_declarations=[
types.FunctionDeclaration(
name="list_changed_files",
description="이번 PR에서 변경된 파일 경로 목록을 반환한다.",
parameters_json_schema={"type": "object", "properties": {}},
),
types.FunctionDeclaration(
name="get_diff",
description="특정 파일의 변경 내용(diff)을 반환한다.",
parameters_json_schema={
"type": "object",
"properties": {"path": {"type": "string", "description": "파일 경로"}},
"required": ["path"],
},
),
types.FunctionDeclaration(
name="read_file",
description="특정 파일의 전체 내용을 반환한다.",
parameters_json_schema={
"type": "object",
"properties": {"path": {"type": "string", "description": "파일 경로"}},
"required": ["path"],
},
),
])
def run_tool(name, args):
"""툴을 실제로 실행한다. (결과 문자열, 오류 여부)를 돌려준다."""
try:
if name == "list_changed_files":
return json.dumps(CHANGED_FILES, ensure_ascii=False), False
if name == "get_diff":
path = args.get("path")
if path not in DIFFS:
return f"오류: '{path}'의 diff가 없습니다.", True
return DIFFS[path], False
if name == "read_file":
path = args.get("path")
if path not in REPO:
return f"오류: '{path}' 파일을 찾을 수 없습니다.", True
return REPO[path], False
return f"알 수 없는 툴: {name}", True
except Exception as e:
return f"툴 실행 오류: {e}", True
SYSTEM = (
"너는 시니어 코드 리뷰어 에이전트다. 주어진 툴로 PR을 직접 조사하라. "
"먼저 변경된 파일을 확인하고, 필요한 파일의 diff와 내용을 읽어 버그·보안·품질 이슈를 찾아라. "
"마지막에는 리뷰 코멘트를 요약하고, 맨 끝 줄에 심각도(LOW/MED/HIGH)를 표기하라."
)
def run_pr_review_agent(pr_task):
# 부모: 에이전트 트레이스 (조사 활동 전체의 루트)
with langfuse.start_as_current_observation(
name="pr-review-agent", as_type="agent", input=pr_task
) as agent:
contents = [types.Content(role="user", parts=[types.Part(text=pr_task)])]
final_text = ""
for step in range(1, MAX_STEPS + 1):
# 한 번의 실제 LLM 판단(=generation): 다음에 어떤 툴을 부를지/끝낼지 모델이 정함
with langfuse.start_as_current_observation(
name=f"llm-step-{step}", as_type="generation", model=MODEL,
input=(pr_task if step == 1 else "이전 툴 결과를 보고 다음 판단"),
) as gen:
resp = client.models.generate_content(
model=MODEL,
contents=contents,
config=types.GenerateContentConfig(
system_instruction=SYSTEM,
tools=[TOOLS],
# 직접 루프를 돌며 각 단계를 트레이스에 남기기 위해 자동 호출은 끔
automatic_function_calling=types.AutomaticFunctionCallingConfig(disable=True),
),
)
fcs = resp.function_calls or []
text = resp.text or ""
um = resp.usage_metadata
gen.update(
output={"text": text, "tool_calls": [fc.name for fc in fcs]},
usage_details={
"input": getattr(um, "prompt_token_count", 0) or 0,
"output": getattr(um, "candidates_token_count", 0) or 0,
},
)
# 모델의 이번 턴(텍스트 또는 함수 호출)을 대화 기록에 추가
if resp.candidates:
contents.append(resp.candidates[0].content)
# 더 부를 툴이 없으면(=최종 답변) 루프 종료
if not fcs:
final_text = text
break
# 모델이 요청한 툴을 실행하고, 각 실행을 tool 스팬으로 기록
fr_parts = []
for fc in fcs:
args = dict(fc.args) if fc.args else {}
with langfuse.start_as_current_observation(
name=fc.name, as_type="tool", input=args
) as tool_span:
result, is_error = run_tool(fc.name, args)
tool_span.update(
output=result,
level="ERROR" if is_error else "DEFAULT",
)
fr_parts.append(
types.Part.from_function_response(name=fc.name, response={"result": result})
)
# 툴 결과를 모델에 회신
contents.append(types.Content(role="user", parts=fr_parts))
agent.update(output=final_text)
# (선택) 데모용 자동 점수: 'HIGH' 심각도를 잡았는지 휴리스틱 BOOLEAN 점수
agent.score_trace(
name="flagged_high_severity",
value=1 if "HIGH" in final_text.upper() else 0,
data_type="BOOLEAN",
comment="데모용 휴리스틱 점수 (실제로는 LLM-as-judge나 사람 평가로 대체)",
)
return final_text
if __name__ == "__main__":
task = "다음 PR을 리뷰해줘. 툴로 변경 파일을 직접 조사한 뒤 이슈를 정리해줘."
print(run_pr_review_agent(task))
langfuse.flush() # 짧게 실행되는 스크립트는 종료 전 flush 필수
print("\n완료 — Langfuse UI의 Traces 메뉴에서 에이전트의 조사 과정을 확인하세요.")
이 스크립트는 세 개의 도구(list_changed_files·get_diff·read_file)를 가진 에이전트가 ‘PR을 조사해 리뷰하라’고 지시받고, 판단 → 도구 호출 → 결과 확인 → 다음 판단의 루프를 도는 과정을 담았습니다. 매 단계에서 다음에 어떤 도구를 부를지, 언제 조사를 끝낼지는 Gemini가 스스로 정합니다. 각 판단은 generation으로, 각 도구 실행은 tool 스팬으로 트레이스에 기록됩니다. 실습에서는 바로 이 내용을 관측합니다.
Step 5. 에이전트를 실행하고 활동을 추적하기
다음 명령어로 에이전트를 실행합니다. 실제 모델이 판단하는 데는 10 ~ 30초 정도 걸립니다.
python3 pr_review_agent.py
터미널에 리뷰 결과가 나오면 Langfuse UI에서 Tracing을 클릭합니다. 방금 생성된 pr-review-agent 트레이스를 클릭하면 에이전트의 조사 과정이 트리로 펼쳐지는데요. 이 실습에서는 다음과 같은 트리가 나왔습니다.
pr-review-agent (agent) - 8.78초 · 1,421 토큰 · $0.000855
+- llm-step-1 (generation) <- 판단: 변경 파일 목록 확인 결정
+- list_changed_files (tool) <- ["billing.py", "README.md"]
+- llm-step-2 (generation) <- 판단: billing.py diff 조회 결정
+- get_diff (tool) <- billing.py diff 조회
+- llm-step-3 (generation) <- 판단: README.md diff 조회 결정
+- get_diff (tool) <- README.md diff 조회
+- llm-step-4 (generation) <- 최종 리뷰 작성 + 심각도 HIGH
이번 실행에서 에이전트는 변경 파일 목록을 확인하고(list_changed_files), billing.py와 README.md의 diff를 차례로 조회한 뒤(get_diff), 리뷰를 작성했습니다. read_file 도구는 한 번도 사용하지 않았는데요. diff만으로 충분하다고 스스로 판단한 것으로 해석됩니다.
트리에서 도구 스팬(get_diff)을 클릭하면 입력과 출력을 확인할 수 있습니다. 이번 실행에서는 get_diff가 돌려준 billing.py diff에 subtotal / discount 코드가 들어 있었고, 에이전트가 지적한 ZeroDivisionError가 이 코드와 일치했습니다.
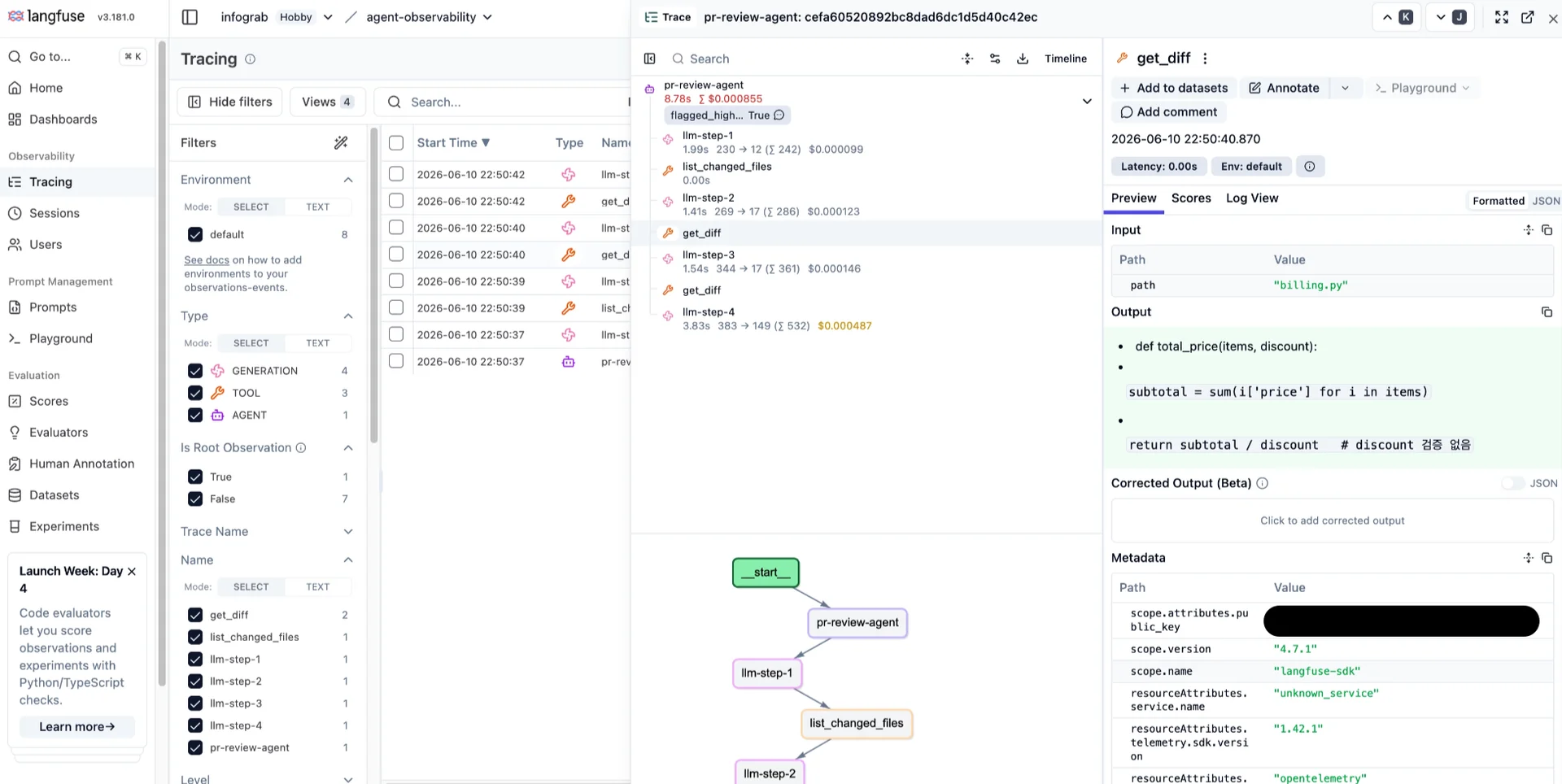
실습 과정에서는 무료 티어 한도에 걸려 중단된 실행도 있었는데요. 그 실패도 트레이스에서 확인할 수 있었습니다. 트리에는 llm-step-1과 list_changed_files까지 정상으로 기록되고, 두 번째 판단에 빨간 ERROR 배지가 붙어 있었는데요. 어디까지 정상이었고 어느 단계에서 멈췄는지를 한눈에 볼 수 있다는 점에서 에이전트 옵저버빌리티의 가치를 확인할 수 있습니다.
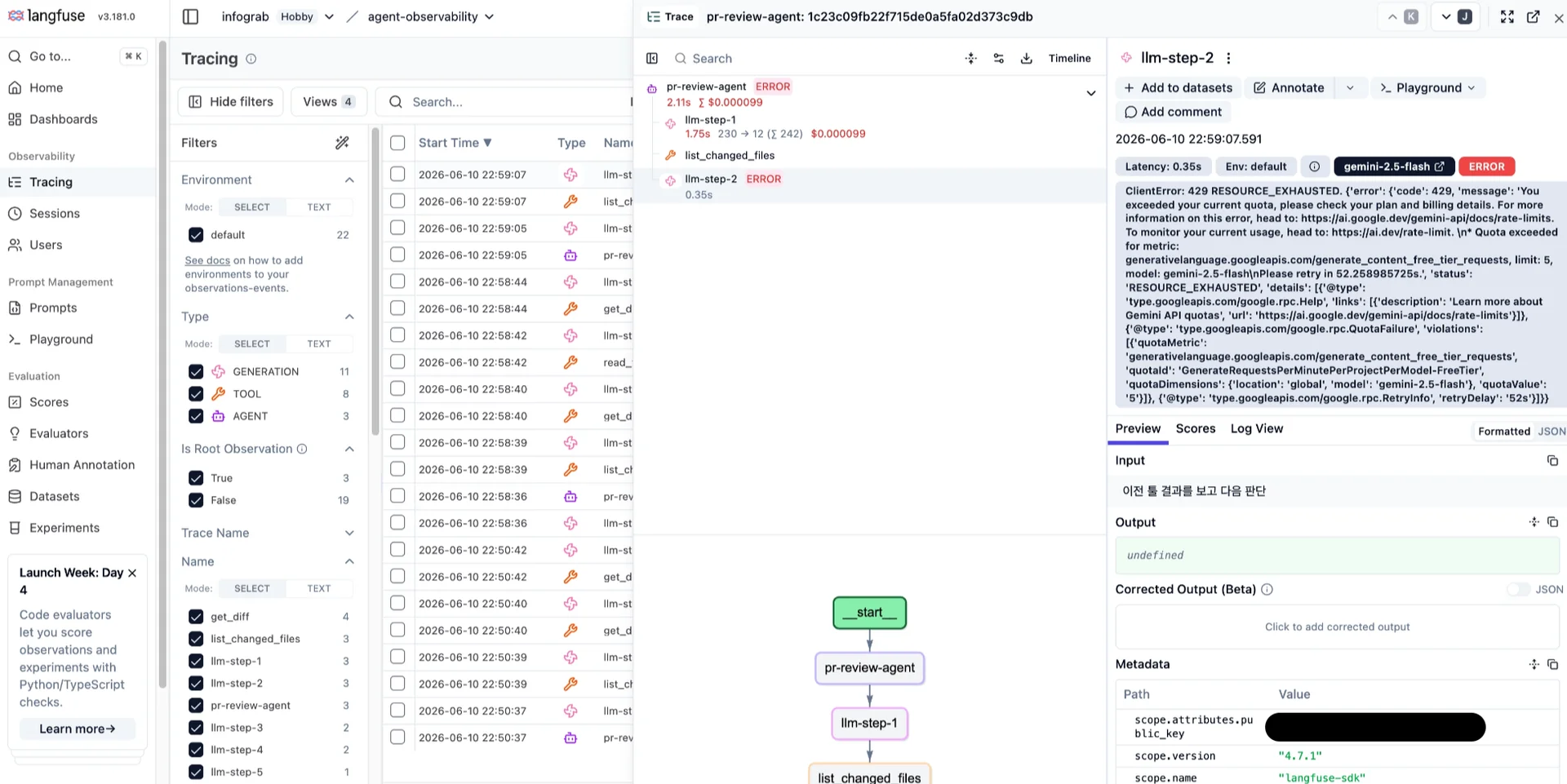
Step 6. 평가: 에이전트의 결과에 점수 매기기
이 실습에서는 코드 평가자·주석을 사용해 에이전트의 결과를 평가했습니다. 방법은 다음과 같습니다.
코드 평가자
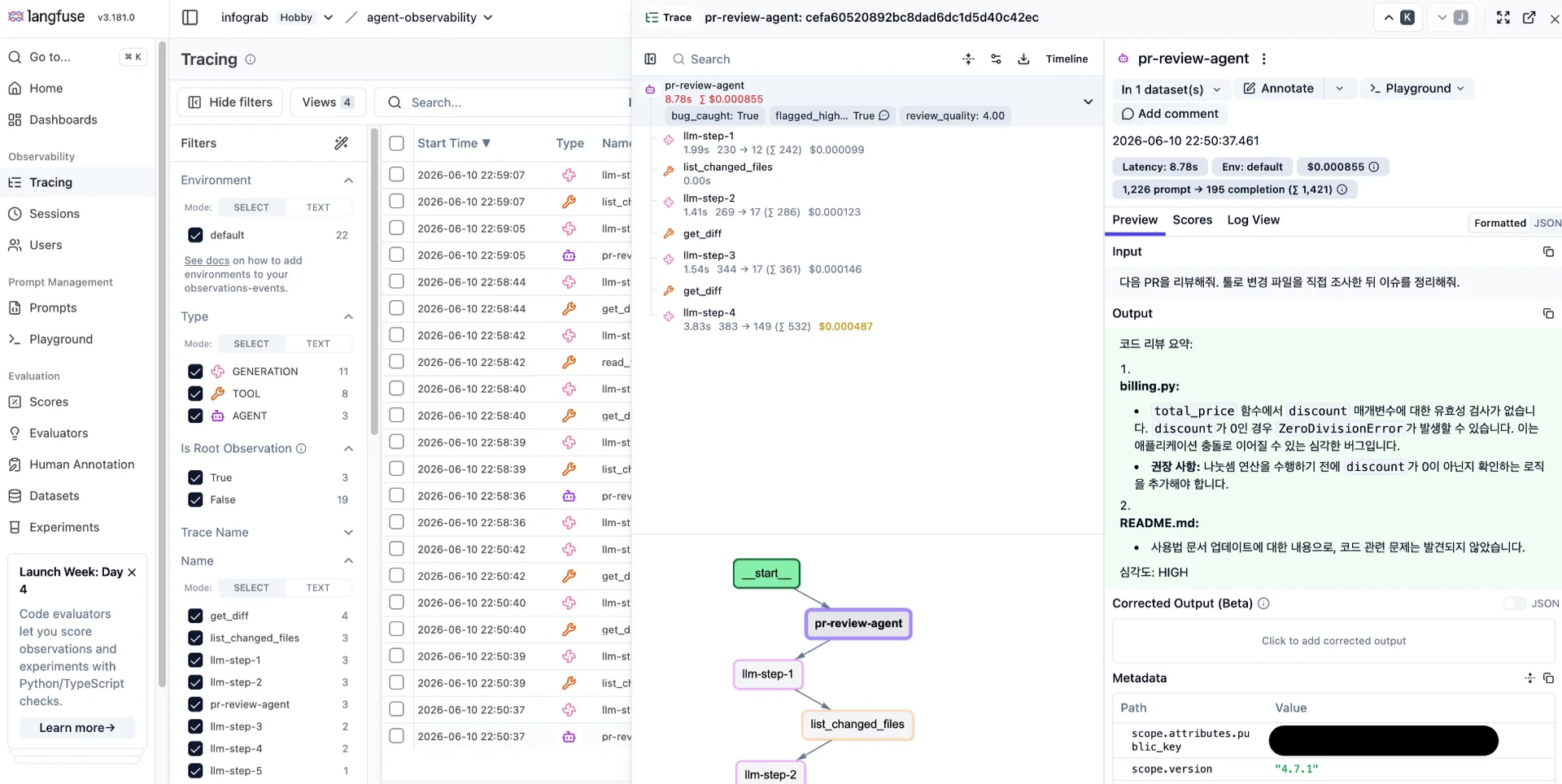
트레이스 상단에는 flagged_high_severity: True 점수가 이미 붙어 있습니다. 이는 스크립트 마지막의 score_trace()가 "최종 리뷰에 HIGH가 들어 있는가"를 규칙으로 판정해 자동으로 달린 점수, 즉 코드 평가자(code evaluator)입니다.
주석: 사람이 직접 점수 매기기
- 트레이스 화면에서 루트
pr-review-agent를 선택하고 Annotate를 누릅니다. - 점수 항목을 정의합니다(예:
bug_caught= Boolean,review_quality= 1~5). - 값을 매깁니다. 이것이 사람이 매기는 주석입니다.
이번 실습에서는 자동 점수 flagged_high_severity = True와 사람이 매긴 bug_caught = True, review_quality = 4, 총 세 개의 점수가 트레이스에 나란히 붙었습니다.
Step 7. 실패를 평가 케이스로 승격하기
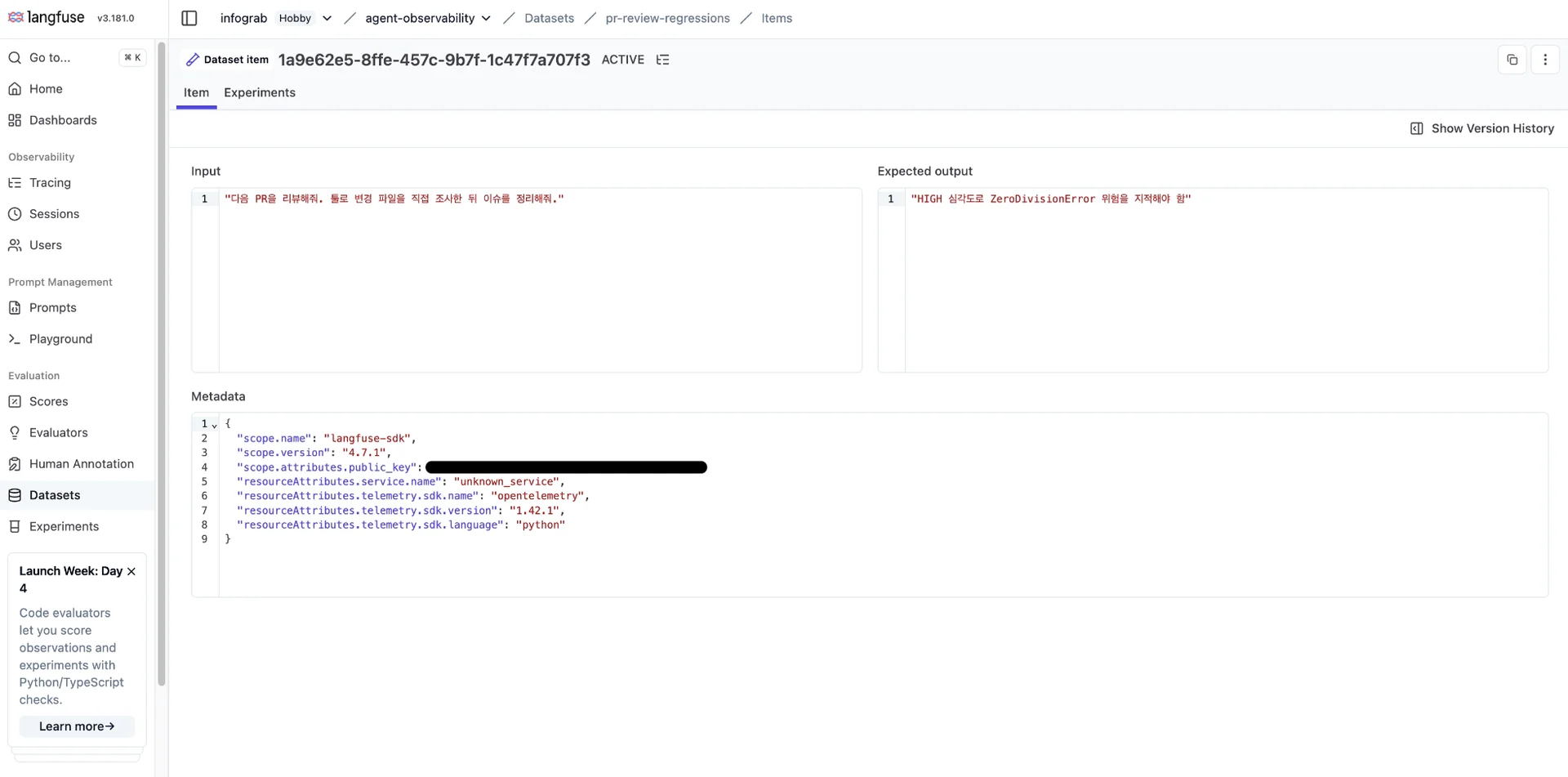
- 트레이스 화면에서 Add to datasets를 누릅니다.
- 새 데이터셋(예:
pr-review-regressions)을 만들고, 이 트레이스를 항목으로 추가합니다. - 입력과 함께 Expected output란에 기대 결과(
"HIGH 심각도로 ZeroDivisionError 위험을 지적해야 함")를 적어둡니다. 이는 회귀 테스트의 기준이 됩니다.
이후 프롬프트·모델·도구 구성을 수정할 때 이 데이터셋으로 Experiment를 돌리면 수정 전과 점수를 비교할 수 있고, 이 검사를 CI/CD 배포 게이트로 걸 수 있습니다. 앞서 설명한 에이전트 옵저버빌리티의 동작 흐름인 '에이전트 실행 → 트레이스 수집 → 평가 → 데이터셋 누적 → 개선 → 실험·배포 게이트'가 이렇게 연결됩니다.
에이전트 옵저버빌리티 운영 시 유의사항
에이전트 옵저버빌리티를 원활하게 운영하기 위해 유의해야 할 사항을 살펴보겠습니다.
자동 평가 점수는 1차 필터로 활용한다
자동 평가는 편리하지만, 이 또한 하나의 모델 판단이라 정답으로 100% 신뢰하기는 어렵습니다. LLM-as-judge는 표현만 그럴듯한 답에 후한 점수를 줄 가능성도 있고요. 따라서 자동 점수는 정답이 아닌 1차 필터로 활용하고, 일부 결과는 사람이 함께 검토해 채점 기준을 보정하는 편이 안전합니다.
평가 대상의 중요도에 따라 사용 모델을 차등화한다
모든 트레이스를 채점하는 전수 평가를 진행하면 옵저버빌리티 비용이 급증합니다. 프로덕션 트래픽에 비례해 심사용 LLM 호출이 늘어나기 때문인데요. 시작할 때는 일부 트레이스만 채점해 추세를 보고, 본격적으로 광범위하게 트레이스를 채점할 때는 저비용 모델을 쓰는 게 비용 관리에 효과적일 수 있습니다. 회귀 검사처럼 정확도가 중요한 구간에만 높은 가격의 고성능 모델로 채점하면 핵심 평가의 정확성을 담보할 수 있고요.
민감정보 정책은 관측을 진행하기 전에 수립한다
트레이스에는 코드, 프롬프트, 사용자 입력과 같은 민감정보가 그대로 흘러들어갈 수 있습니다. 관측을 진행하기 전에 다음 세 가지 계획을 먼저 수립하는 걸 권장합니다. 민감 필드를 가리는 마스킹 방식, 트레이스 보존 기간, 데이터가 저장되는 곳이 그 내용인데요. 사내 규정상 외부 클라우드에 데이터를 둘 수 없다면, 셀프호스트가 가능한 도구를 활용하는 게 좋습니다.
벤더 종속은 OpenTelemetry 표준 계측으로 줄인다
옵저버빌리티 운영을 특정 벤더에 의존하면 전환 비용과 로드맵 리스크가 따라올 수 있습니다. 인수합병과 같은 벤더의 지배구조 변화가 서비스, 기능에 영향을 줄 가능성이 있죠. OpenTelemetry 표준 위에서 계측하면 이러한 변동 위험을 비교적 줄일 수 있는데요. 도구를 바꿔도 트레이스, 스팬과 같은 핵심 구조와 계측 코드 대부분을 재사용할 수 있기 때문입니다.
실패를 테스트용 평가 데이터셋으로 활용한다
에이전트를 운영하다 보면 모델 업데이트, 프롬프트·도구 수정, 사용자 입력의 변화가 계속 생기는데요. 이런 변화는 이전에 바로잡았던 실패를 언제든지 다시 불러올 수 있습니다. 실패가 평가 케이스로 남아 있지 않으면 이 재발을 자동으로 발견할 장치가 없게 되고, 문제는 사용자 신고가 있어야 드러날 수 있는데요. 따라서 주목할 실패는 평가 데이터셋으로 승격해 두고, 트레이스와 품질 드리프트(평가 점수가 시간이 지나며 점차 떨어지거나 변하는 현상)를 주기적으로 점검하는 걸 권장합니다.
맺음말
지금까지 에이전트 옵저버빌리티의 개념과 동작 방식을 알아보고, Langfuse와 Google Gemini로 PR 리뷰 에이전트를 추적·평가하는 실습을 진행했습니다. 이 글의 요점은 다음과 같은데요.
- 에이전트 옵저버빌리티는 에이전트가 거친 모든 단계를 기록해 '무엇을, 왜 했는지'를 재구성하는 기술입니다. APM이 서비스·요청을, LLM 옵저버빌리티가 개별 모델 호출을 보는 것과 달리, 에이전트 옵저버빌리티는 여러 판단과 도구 호출이 이어지는 실행 전체를 하나의 관측 단위로 보죠.
- 에이전트 옵저버빌리티는 기록으로 끝나지 않습니다. 에이전트 실행 → 트레이스 수집 → 평가 → 데이터셋 누적 → 개선 → 실험·배포 게이트로 이어지는 루프를 돌고, 실제 운영에서 발생한 실패를 테스트 케이스로 바꿔 같은 실수가 배포하기 전에 회귀로 포착되게 합니다.
- 실습에서는 이 루프의 핵심을 직접 확인했습니다. 트레이스는 에이전트의 판단·도구 호출 경로를 단계별 트리로 보여줬고요. 무료 티어 한도로 중단된 실행도 어느 단계에서 멈췄는지가 단계 단위로 기록됐습니다. 여기에 코드 평가자와 주석으로 점수를 매기고, 트레이스를 회귀 데이터셋으로 승격했습니다.
- 운영할 때는 다음 사항을 유의해야 합니다. 자동 평가 점수는 정답이 아닌 1차 필터로 다루고요. 민감정보 정책(마스킹·보존 기간·저장 위치)은 관측을 진행하기 전에 수립합니다. 벤더 종속은 OpenTelemetry 표준 계측으로 줄이고, 실패를 평가 데이터셋으로 꾸준히 승격하는 습관이 중요합니다.
에이전트 관측의 다음 과제는 통제입니다
거버넌스 없는 AI 도입은 비용 폭주와 보안 사고로 이어질 수 있습니다. 인포그랩은 권한·감사까지 함께 설계해 안전한 에이전트 운영 체계 도입을 지원합니다.
참고 자료
- "Agent observability: The complete guide for 2026", Braintrust, 2026-05-06, https://www.braintrust.dev/articles/agent-observability-complete-guide-2026
- "AI Agent Observability: Tracing, Testing, and Improving Agents", LangChain, https://www.langchain.com/resources/agent-observability
- "Agent Observability: Building Transparency into AI Systems", Salesforce, https://www.salesforce.com/agentforce/observability/agent-observability/
- "AI Observability for LLMs and Agents", MLflow, https://mlflow.org/ai-observability
- OpenTelemetry GenAI Semantic Conventions 공식 문서, https://opentelemetry.io/docs/specs/semconv/gen-ai/
- Langfuse 공식 문서, https://langfuse.com/docs
- Ryadh Dahimene·Marc Klingen·Max Deichmann·Clemens Rawert, "ClickHouse welcomes Langfuse: The future of open-source LLM observability", ClickHouse, 2026-01-16, https://clickhouse.com/blog/clickhouse-acquires-langfuse-open-source-llm-observability
- Arize Phoenix 공식 문서, https://arize.com/docs/phoenix
- LangSmith 공식 페이지, https://www.langchain.com/langsmith
- Braintrust 공식 문서, https://www.braintrust.dev/docs
- Gemini API Rate Limits 공식 문서, Google AI for Developers, https://ai.google.dev/gemini-api/docs/rate-limits
- Lianmin Zheng et al., "Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena", arXiv, 2023, https://arxiv.org/abs/2306.05685
- Dylan Reber, "84% of enterprises plan to boost AI agent investments in 2026", Zapier, 2025-12-15, https://zapier.com/blog/ai-agents-survey/

이 글이 도움이 되셨나요?
인포그랩 전문가가 맞춤 상담을 도와드립니다.
관련 글

DevOps 데이터, 자연어 한 줄로 즉시 보고하는 법
개발팀 성과를 경영진 보고로 정리하는 데 며칠씩 걸리시나요? 2024년 이후 BI에서 DevOps로 확장된 생성형 AI 데이터 분석, 그리고 GitLab Data Analyst Agent와 인포그랩 Mantis가 이를 자연어 한 줄로 바꾸는 방식을 살펴봅니다.

엔터프라이즈 AI 에이전트 성능 평가 가이드
AI 에이전트는 프롬프트, RAG, MCP, 도구 호출, 다단계 추론 등을 결합해 자율적으로 동작합니다. 따라서 성능을 정확히 측정하려면 이러한 특성을 고려한 전용 평가 방법이 필요합니다. 이 글은 에이전트 성능 평가 시 고려 사항, LLM-as-a-Judge 평가 방식, 도구 호출·사용 능력 평가 방법, NEXA 적용 사례와 결과를 다뤘습니다.

AI 에이전트는 보안 취약점 관리를 어떻게 자동화할까?
이 글은 AI 에이전트를 중심으로 보안 취약점 관리 자동화 기술 동향을 다뤘습니다. Claude Code는 자동 보안 리뷰 기능으로 보안 문제 검사와 수정을 지원합니다. Opus Security는 멀티 에이전트 기반 자율형 취약점 관리 플랫폼으로 취약점 분석과 시정 조치를 자동화합니다. Cycode는 AI 악용 가능성 분석으로 고위험 취약점을 신속하게 확인합니다. DeepSource는 완전 자율 에이전트 방식으로 리포지터리를 모니터링하고, 의사결정을 내리며, 적절한 조치를 취합니다.