LLM·하네스로 더 좋은 n8n 워크플로 생성하기
"Jira에서 검토 중인 이슈를 분석해서 Confluence에 일일 리포트로 발행하는 워크플로를 만들어줘."
LLM에 이런 식으로 n8n 워크플로 생성을 요청했다가 결과물이 기대와 달랐던 적 있으신가요? 저는 Claude Opus 모델에 별도의 도구나 정보 없이 위 요청을 그대로 넣어 세 번 테스트한 적이 있습니다. 테스트 결과, 다음 두 가지 문제가 나타났습니다.
- 모델이 SDK를 쓰지 않았습니다. 세 번의 테스트 모두 워크플로를 코드로 생성하는 n8n Workflow SDK 대신 raw JSON으로 출력했습니다. raw JSON 자체는 n8n에 그대로 불러올 수 있는 형식이지만, 모델이 SDK 기반 생성 방식을 활용하지 않았다는 신호입니다.
- 노드로 할 일을 코드로 처리합니다. Webhook 이미지 처리 시나리오에서는 데이터 변환에 Code 노드 6개, JavaScript 68줄을 썼고, Jira 이슈 분류 시나리오에서는 AI 응답을 파싱·병합하는 데 80여 줄짜리 Code 노드를 동원했습니다. 둘 다 n8n이 제공하는 노드로 처리할 수 있는 일인데도 코드로 대체하면, 워크플로의 가독성과 유지보수성이 낮아지고, 불필요한 코드와 오류 가능성도 함께 늘어날 수 있습니다.
두 문제가 발생한 원인은 바로 모델이 기본 학습 지식으로 갖고 있는 n8n 정보가 불완전한 데 있습니다. 모델은 n8n Workflow SDK처럼 최근 나온 도구와 관련해 별도 정보가 없으면 이를 안정적으로 활용하지 못할 수 있습니다. 아울러 n8n 노드의 이름은 알아도 정확한 파라미터 구조와 리소스 타입, 버전별 차이까지는 알기 어려울 수 있죠.
이번 세 번의 테스트에서 모델이 SDK 코드 대신 raw JSON으로 출력한 이유는 JSON이 n8n 워크플로의 기본 표현 형식이라 모델이 그쪽으로 기울었을 가능성이 있습니다. 노드로 할 일을 코드로 처리한 것도 파라미터 구조나 전용 노드를 정확히 몰라서 발생한 결과일 수 있죠. 두 문제는 모델의 성능 부족보다 기본 학습 지식의 한계에서 비롯된 결과로 볼 수 있습니다.
LLM에 정확한 정보와 도구를 제대로 쥐여 주면 결과는 어떻게 달라질까요? 저는 LLM의 작업 환경 전체를 설계하는 접근 방식인 '하네스(Harness)'를 직접 만들어 실험해 봤습니다. 이 글에서는 같은 모델과 같은 요청을 두고 하네스 수준만 바꿨을 때 모델이 생성한 n8n 워크플로 품질이 어떻게 달라지는지를 실험 데이터로 살펴보겠습니다.
하네스 엔지니어링이란

하네스 엔지니어링(Harness Engineering)은 AI 에이전트의 작업 환경 전체를 설계하는 일입니다. 모델에 무엇을 시킬지가 아니라, 모델이 어떤 도구와 정보를 손에 쥐고 어떤 제약과 피드백 안에서 움직이는지 — 그 환경 전체를 짜는 접근이죠.
이 작업 환경은 세 겹으로 이뤄져 있습니다. 맨 안쪽은 프롬프트 엔지니어링으로, "무엇을 해라"라는 지시를 다듬는 일입니다. 그 바깥은 컨텍스트 엔지니어링으로, 모델이 무엇을 보고 판단할지 — 어떤 정보와 정의(스펙), 이전 출력, 기억까지 창에 채울지 설계하죠. 가장 바깥은 하네스 엔지니어링으로, 여기에 도구와 검증, 제약 조건까지 더합니다. 프롬프트는 컨텍스트 안에, 컨텍스트는 하네스 안에 들어 있습니다.
복잡하게 할 필요 없이 그냥 ‘프롬프트를 더 잘 쓰면 되지 않나?’라고 생각할 수도 있습니다. 그러나 도입부에서 살펴본 문제 — 모델이 SDK를 쓰지 않고, 노드로 할 일을 코드로 우회하는 것 — 은 프롬프트만으로 해결할 일이 아닙니다. 모델에 정확한 노드 스펙이 부족하고, 생성물을 검증할 도구가 없으며, 전용 노드를 탐색하는 데 한계가 있어 생긴 일이죠. 정보와 도구, 검증 수단까지 갖춰 주는 바깥 환경 — 즉 하네스를 설계해야 풀 수 있는 문제입니다.
비유하면 이렇습니다. 레시피(프롬프트)를 아무리 정교하게 써도, 적절한 재료와 주방 도구가 없으면 요리를 만들 수 없습니다. 하네스는 레시피와 함께 재료, 도구, 맛을 확인할 피드백 장치까지 갖춰 요리를 목표한 대로 정확히 완성하는 데 도움을 줍니다.
그렇다면 n8n 워크플로를 생성할 때는 이 작업 환경을 구체적으로 어떻게 설계해야 할까요?
n8n 워크플로 생성 하네스를 구성하는 4가지 요소
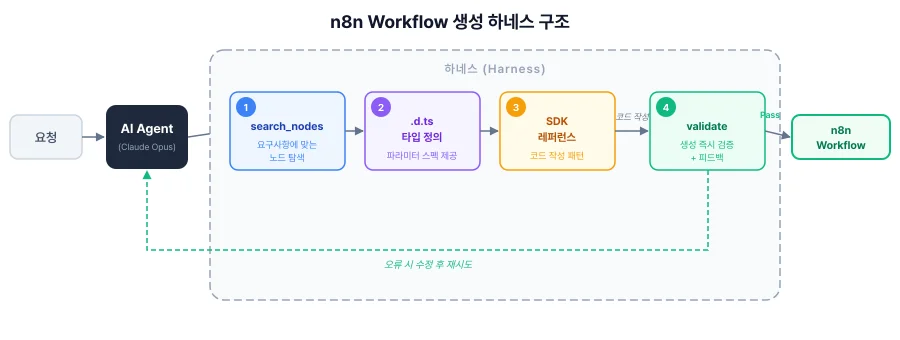
LLM으로 n8n 워크플로를 정확하게 생성하기 위해 저는 작업 환경 — 하네스를 위 다이어그램과 같이 설계했습니다. 이 구조를 기반으로 하네스 수준에 따라 모델이 생성한 워크플로 품질이 어떻게 달라지는지를 실험했습니다. 다음은 이 하네스를 이루는 4가지 핵심 구성 요소입니다.
-
노드 검색 도구 (search_nodes)
search_nodes는 요구사항에 맞는 노드를 탐색하는 도구입니다.
resource-operation-index를 통해 세부 리소스까지 발견할 수 있습니다. 이것이 없으면issueAttachment같은 세부 리소스를 인지하지 못한 채httpRequest로 우회합니다. -
노드 타입 정의 (.d.ts)
.d.ts는 각 노드의 파라미터 스펙을 담은 TypeScript 타입 정의입니다. 이것이 없으면 모델은 파라미터 이름을 추측해 존재하지 않는 옵션을 만들거나, 꼭 필요한 파라미터를 빠뜨립니다.
-
SDK 레퍼런스
SDK 레퍼런스는 n8n Workflow SDK의 코드 작성 패턴과 문법을 모은 레퍼런스입니다. 이것이 없으면 모델은 SDK의 존재를 인식하지 못한 채 raw JSON으로 출력합니다. 실제 실험에서 3건 모두 이 현상이 발생했습니다.
-
검증 도구 (validate)
validate는 생성된 워크플로의 유효성을 즉시 검사하는 도구입니다. 파라미터 누락, 타입 불일치, 연결 오류를 자동으로 탐지해 에이전트가 스스로 수정할 수 있게 합니다. 이것이 없으면 모델은 자신이 만든 워크플로의 오류를 스스로 발견하지 못한 채, 잘못된 결과물을 그대로 내놓습니다.
구체적인 예: 첨부파일 다운로드
하네스가 있는지 없는지에 따라 실제 출력이 어떻게 달라지는지, '첨부파일 다운로드'라는 하나의 요구를 예로 살펴보겠습니다.
하네스가 없을 때는 첨부파일을 받으려고 Jira REST API를 httpRequest로 직접 호출했습니다.
// 하네스 없음 — Jira REST API를 직접 호출하여 첨부파일 다운로드
{ type: "n8n-nodes-base.httpRequest",
method: "GET",
url: "={{ $json.attachments[0].content }}",
authentication: "predefinedCredentialType",
nodeCredentialType: "jiraSoftwareCloudApi" }
하네스가 있으면 search_nodes가 issueAttachment라는 세부 리소스를 발견하게 해주고, 모델은 httpRequest 우회 대신 네이티브 노드를 직접 사용했습니다. 아래는 이때 실제로 생성된 워크플로입니다.
// Plugin — Jira 네이티브 issueAttachment 사용
{ type: "n8n-nodes-base.jira",
resource: "issueAttachment",
operation: "getAll",
issueKey: "={{ $json.issueKey }}",
download: true }
이 차이가 전체 실험에서 얼마나 일관되게 나타나는지 다음 실험 결과에서 수치로 확인합니다.
하네스 수준에 따라 n8n 워크플로 품질은 어떻게 달라질까
앞에서 설계한 하네스를, 이번에는 하네스 수준을 변수로 두고 실험했습니다. 같은 모델과 같은 작업을 주고 하네스만 없음 → 중간 → 높음으로 바꿨을 때 생성된 워크플로의 품질이 어떻게 달라지는지를 살펴봤습니다. 먼저 실험 설계와 결과 수치를 정리하고, 하네스 수준이 높아질수록 무엇이 어떤 순서로 좋아지는지 알아보겠습니다.
실험 설계: 3개 시나리오 × 3개 하네스 수준
다음 세 가지 시나리오를 만들고, 각 시나리오에 세 가지 하네스 수준을 모두 적용해 총 9회 실험했습니다. 모델은 Claude Opus를 사용했습니다.
- Jira 일일 요약 — 특정 프로젝트의 그날 Jira 이슈를 모아 AI가 요약하고, Confluence 문서로 정리한 뒤 Slack으로 알립니다. (Jira → AI → Confluence → Slack)
- Jira 자동 분류 — 새로 등록된 Jira 이슈를 AI가 유형별로 분류하고, 결과를 Google Sheets에 기록한 뒤 Slack으로 알립니다. (JiraTrigger → AI → Sheets → Slack)
- Webhook 이미지 처리 — Webhook으로 전달된 이미지 URL 목록을 내려받아 엑셀 메타데이터와 대조·처리한 뒤 응답합니다. (Webhook → 다운로드 → 엑셀 → 응답)
세 가지 하네스 수준(실험 조건)은 다음과 같습니다.
| 조건 | 설명 | 하네스 수준 |
|---|---|---|
| Baseline | MCP 도구 없이 LLM 학습 지식만으로 생성 | 없음 |
| n8n MCP | n8n MCP 서버로 노드 정보를 조회 | 중간 |
| Plugin | .d.ts + SDK 레퍼런스 + search_nodes + validate | 높음 |
하네스 수준별 성능 비교
결과는 세 가지 핵심 지표로 평가했습니다.
- Validate 1회 통과율 — 생성된 코드가 한 번에 n8n에서 실행 가능한지 봅니다. 높을수록 손대지 않고 바로 운영할 수 있습니다.
- 네이티브 노드 활용률(Svc/(Svc+Code)) — 서비스 통합에 n8n 내장 노드를 쓴 비율입니다. 높을수록 유지보수가 쉽고 비개발자도 편리하게 수정할 수 있습니다.
- Code 의존도 — 전체에서 JavaScript Code 노드가 차지하는 비율입니다. 높을수록 코드 유지보수 부담이 커집니다.
이와 함께 Placeholder 수(모델이 채우지 못해 남긴 미완성 값의 개수), 평균 소요 시간, 출력 형식도 함께 봤습니다.
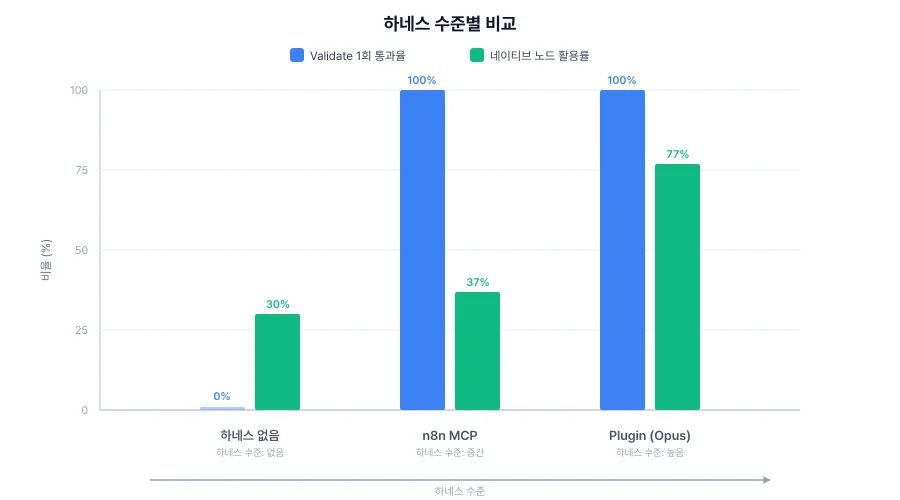
다음은 3개 시나리오 평균을 낸 하네스 수준별 성능 비교입니다
| 지표 | Baseline | n8n MCP | Plugin |
|---|---|---|---|
| Validate 1회 통과율 | 0% (N/A) | 100% | 100% |
| 네이티브 노드 활용률 | 0.30 | 0.37 | 0.77 |
| Code 의존도 | 0.31 | 0.20 | 0.15 |
| Placeholder 수 | 6 | 4 | 0 |
| 평균 소요 시간 | 1m 26s | 10m 02s | 11m 11s |
| 출력 형식 | raw JSON | SDK code | SDK code |
수치는 한 방향을 가리킵니다. 하네스 수준이 높아질수록 Validate 통과율은 0%에서 100%로, 네이티브 노드 활용률은 0.30 → 0.37 → 0.77로 오르고, Code 의존도는 0.31 → 0.20 → 0.15로, Placeholder는 6 → 4 → 0으로 떨어집니다.
참고로, 하네스가 없는 Baseline은 도구 호출 없이 즉시 생성해 출력 속도가 빠르지만, 출력 형식 자체가 raw JSON이라 validate를 적용하기 어려웠습니다.
결과 해석: 무엇이 어떤 순서로 좋아질까
-
출력 형식과 유효성 문제는 하네스 수준이 조금만 높아져도 해결됩니다.
Baseline은 세 시나리오 모두 raw JSON으로 출력해 validate를 적용할 수 없었습니다. 그러나 중간 수준인 n8n MCP부터 출력이 SDK code로 바뀌고 Validate 통과율도 100%가 됩니다. 앞서 설명했듯 SDK 레퍼런스가 보완하는 부분이 바로 이 출력 형식 문제인데, 적은 하네스로도 해결할 수 있습니다.
-
네이티브 노드 활용은 하네스 수준이 더 높아져야 증가합니다.
활용률은 Baseline 0.30에서 n8n MCP 0.37로 거의 제자리였다가 Plugin에서 0.77로 도약했습니다. 형식만 갖춘 중간 수준의 하네스로는 모델이 여전히 내장 노드 대신 코드로 우회했고, .d.ts의 파라미터 정보까지 더해진 Plugin에서 비로소 네이티브 노드를 제대로 썼습니다. 격차는 두 시나리오에서 뚜렷했습니다.
Webhook 이미지 처리 — Plugin은 Code 노드 0개로 끝냈지만, Baseline은 Code 노드 6개·JavaScript 68줄을 썼습니다. 입력 검증과 메타데이터 매핑을 모두 코드로 처리한 모습입니다.
javascript// 하네스 없음 — 입력검증 Code 노드 (6개 중 1개) const body = $input.first().json.body || $input.first().json; const imageUrls = body.imageUrls; if (!Array.isArray(imageUrls) || imageUrls.length === 0) { throw new Error('imageUrls는 비어있지 않은 배열이어야 합니다'); } return imageUrls.map((url, idx) => ({ json: { 이미지URL: url, 인덱스: idx, 메타데이터URL: body.metadataFileUrl } }));Baseline에서 나머지 5개 Code 노드도 메타데이터 맵 생성, 성공/실패 마킹, 결과 요약을 각각 JavaScript로 구현해, 사용한 총 15개 노드 중 6개가 Code 노드였습니다. 반면 Plugin은 같은 기능을 네이티브 노드만으로 구성했습니다.
javascriptPlugin — 네이티브 노드만으로 동일 기능 구현 (Code 0개, JS 0줄) Webhook(POST) → SplitOut(배열 분리) → HTTP Request(엑셀 다운로드) → ExtractFromFile(XLSX 파싱) → SplitInBatches(배치 처리) → [success] Set(status=success) → [loop] → [error] Set(status=fail) → [loop] → [done] ConvertToFile(XLSX) → RespondToWebhook(binary)Plugin에서 사용한 총 9개 노드에서 Code 노드는 하나도 없었습니다. 입력 분리는
SplitOut, 엑셀 파싱은ExtractFromFile, 상태 표시는Set, 결과 변환은ConvertToFile로 처리합니다.Jira 자동 분류 — Baseline은 AI 응답 파싱과 이슈 데이터 추출에 Code 노드 2개(86줄 + 39줄)를 동원했지만, Plugin은
outputParserStructured(구조화 출력 파서) 노드에 분류 스키마를 연결해 Code 노드 없이 네이티브 노드만으로 같은 일을 했습니다.주목할 점은, 하네스 수준이 높아지면서 모델이
ExtractFromFile·ConvertToFile·outputParserStructured같은 노드의 존재와 파라미터를 알게 돼 코드 대신 그 노드를 골랐다는 것입니다. 다만 이는 출력에서 끌어낸 추론이며, 모델이 노드를 알고도 다른 이유로 코드를 택했을 가능성까지 배제하지 않습니다. -
도구를 더하면 소요 시간은 비슷한데, 품질이 좋아집니다
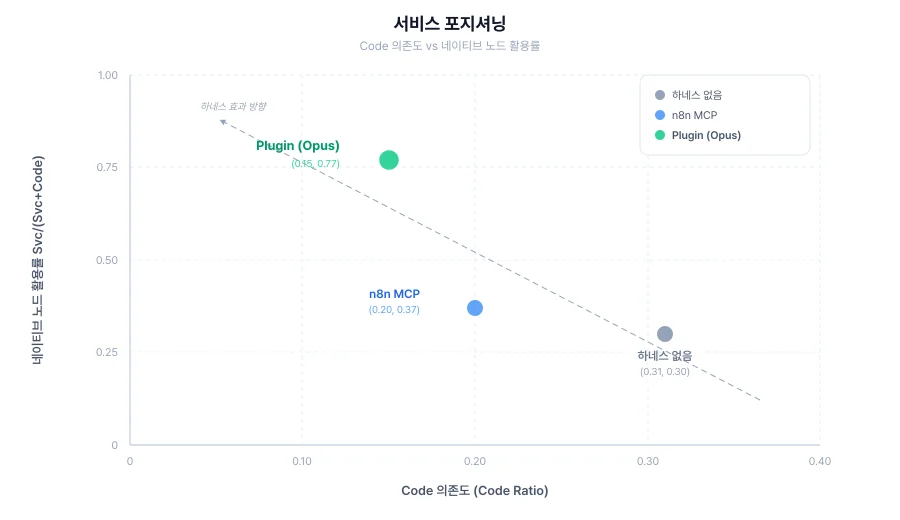
도구를 쓰는 두 조건(n8n MCP 10분 2초, Plugin 11분 11초)의 소요 시간은 큰 차이가 없습니다. 도구를 더해도 시간은 거의 같지만, 네이티브 노드 활용률은 n8n MCP 0.37에서 Plugin 0.77로 약 2배 증가합니다. 더 나은 결과의 비용은 '모델에게 무엇을 쥐여 주느냐'임을 확인할 수 있었습니다.
하네스를 실무에 적용하는 두 가지 방법
실험 결과로는 Plugin처럼 타입 정보까지 갖춘 높은 수준의 하네스가 가장 좋은 출력을 냅니다. 다만 그러려면 하네스를 직접 구축해야 합니다. 실무 적용 방법은 두 갈래로 나뉩니다. 바로 시작하려면 n8n 공식 MCP 서버가 가장 접근성이 높고, 내장 노드를 충분히 활용한 최고 품질이 필요하면 자체 하네스를 설계하는 것이 답입니다.
빠르게 시작하기: n8n 공식 MCP 서버
접근성이 가장 높은 경로는 n8n 공식 MCP 서버입니다. Claude Code, Cursor 등 MCP를 지원하는 AI 코딩 도구에서 연결해 쓸 수 있습니다.
이 서버는 적어도 실행되는(validate 1회 통과) SDK 코드를 보장하고, 하네스를 직접 짤 필요가 없어 진입 장벽이 낮습니다. 다만 실험에서 봤듯 네이티브 노드 활용은 제한적이어서 내장 노드를 충분히 살린 최적 워크플로까지 보장하기 어려울 수 있습니다.
MCP 서버는 대체로 다음과 같은 흐름으로 워크플로를 생성합니다.
- SDK 레퍼런스 파악 — 코드 작성 패턴과 문법을 먼저 익힙니다.
- 노드 검색 — 필요한 서비스 노드와 유틸리티 노드를 탐색합니다.
- 파라미터 타입 조회 — 사용할 노드의 정확한 파라미터 타입을 가져옵니다.
- 검증 — 생성한 코드를 검사하고, 오류가 있으면 수정합니다.
- 워크플로 생성 — 검증된 코드로 워크플로를 생성합니다.
더 나은 품질: 자체 하네스 설계
내장 노드를 충분히 활용한 더 높은 품질이 필요하면 자체 하네스를 설계합니다. 가장 중요한 원칙은 타입 정의의 정확성입니다. 실험에서 .d.ts의 파라미터 정보까지 더한 Plugin에서야 네이티브 노드 활용률이 0.37에서 0.77로 도약했기 때문입니다. 타입 정보가 없으면 SDK 코드는 나와도 모델이 내장 노드를 제대로 쓰지 못하고 코드로 우회합니다.
그다음으로 중요한 것은 검증 피드백 루프입니다. 에이전트가 생성한 결과를 즉시 확인하고 수정할 수 있어야 품질이 높아집니다.
맺음말
이 실험이 보여주는 것은 단순합니다. 에이전트의 출력 품질을 가르는 것은 ‘더 좋은 프롬프트’가 아니라 ‘더 좋은 하네스’입니다. 동일한 모델(Claude Opus)이 동일한 요청을 받아도, 하네스가 없으면 Code 노드 6개와 JavaScript 68줄로 우회하고, 하네스가 있으면 Code 노드 0개로 네이티브 노드만 써서 완성합니다. 프롬프트는 한 글자도 바뀌지 않았습니다. 바뀐 것은 도구와 컨텍스트, 즉 하네스입니다.
하네스가 품질을 가르는 이유는 세 가지로 모입니다. 타입 정의가 정확한 스펙을 주고, 검증 도구가 피드백 루프를 만들며, 탐색 도구가 선택지를 넓힙니다. 모델은 이 세 가지가 갖춰질 때 비로소 도메인의 관례대로 코드를 짭니다. 프롬프트만 다듬어서는 닿지 못하던 지점입니다.
그런데 여기까지 오면 의문이 하나 생깁니다. 하네스만 잘 깔면 n8n은 굳이 공부할 필요가 없지 않을까? 답은 반대입니다. 이 세 가지는 저절로 채워지지 않습니다. .d.ts를 읽혀야 한다는 판단, AI 응답 파싱을 Code가 아니라 구조화 출력 파서(outputParserStructured)에 맡겨야 한다는 판단, Code 노드로 뒤덮인 결과를 보고 "실행되긴 해도 좋은 워크플로는 아니다"라고 평가하는 눈 — 모두 n8n과 도구, 도메인, 요구사항의 본질에 대한 이해에서 나왔습니다. 에이전트는 알려주지 않으면 outputParserStructured를 떠올려 쓰지 못합니다. 판을 까는 사람이 n8n을 제대로 알고 먼저 알려줘야 합니다. 하네스는 그 지식을 코드로 굳힌 결정체입니다.
이 원리는 n8n에만 머물지 않습니다. 타입 정의·검증·탐색이 갖춰진 도메인이라면 — Terraform, Kubernetes, CI/CD 파이프라인처럼 — 에이전트로 도메인 특화 코드를 생성하는 어디서나 같은 패턴을 기대할 수 있습니다. 각 도메인의 스키마가 스펙을 주고, 검증 도구가 피드백을 주고, 레지스트리나 API 탐색이 선택지를 넓힙니다. 채울 재료는 도메인마다 달라도, 스펙·피드백·선택지라는 골격은 같습니다. 그 골격을 채우는 것은 언제나 도메인을 아는 사람입니다.
따라서 공부의 대상은 ‘노드를 수동으로 잇는 법’에서 ‘에이전트가 잘 잇도록 판을 까는 법’으로 옮겨갈 뿐, 사라지지 않습니다. n8n을 잘 알수록, AI로 더 좋은 n8n 워크플로를 만들 수 있습니다.
AI로 n8n 워크플로 생성, 실험은 됐고 실무가 남았습니다
하네스 수준에 따라 워크플로 품질이 갈립니다. 인포그랩은 타입 정의·검증·탐색을 갖춘 자체 하네스 설계부터 n8n 운영 내재화까지 함께 설계합니다.
참고 자료
- "Effective harnesses for long-running agents", Anthropic, 2025-11-26, https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
- Prithvi Rajasekaran, "Harness design for long-running application development", Anthropic, 2026-03-24, https://www.anthropic.com/engineering/harness-design-long-running-apps
- "Effective context engineering for AI agents", Anthropic, 2025-09-29, https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
- Anthropic 프롬프트 엔지니어링 공식 문서, https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/overview
- Avi Chawla, "The Anatomy of an Agent Harness", Daily Dose of Data Science, 2026-04-07, https://blog.dailydoseofds.com/p/the-anatomy-of-an-agent-harness
- "What is an agent harness?", Parallel, https://parallel.ai/articles/what-is-an-agent-harness
- n8n Workflow SDK(@n8n/workflow-sdk) 공식 패키지, npm, https://www.npmjs.com/package/@n8n/workflow-sdk
- Ophir Prusak, "Build and Update Workflows with n8n's MCP Server", n8n, 2026-04-29, https://blog.n8n.io/n8n-mcp-server/
- n8n MCP server tools reference 공식 문서, n8n Docs, https://docs.n8n.io/advanced-ai/mcp/mcp_tools_reference/
- n8n MCP 서버 설정·사용 공식 문서, n8n Docs, https://docs.n8n.io/advanced-ai/mcp/accessing-n8n-mcp-server/
- n8n-mcp 오픈소스 프로젝트, czlonkowski(Romuald Czlonkowski), GitHub, https://github.com/czlonkowski/n8n-mcp
- n8n-mcp 공식 문서, https://www.n8n-mcp.com/docs
- Structured Output Parser node 공식 문서, n8n Docs, https://docs.n8n.io/integrations/builtin/cluster-nodes/sub-nodes/n8n-nodes-langchain.outputparserstructured/
- Extract From File node 공식 문서, n8n Docs, https://docs.n8n.io/integrations/builtin/core-nodes/n8n-nodes-base.extractfromfile/
Miles
Workflow Automation Engineer
InfoGrab의 Workflow Automation Engineer로서, n8n 기반 업무 자동화와 LLM·에이전트 시스템을 설계부터 운영까지 직접 구축합니다. 2019년부터 이어온 백엔드 개발 경험을 바탕으로, 단순 워크플로 구성을 넘어 Claude Code·MCP 기반 멀티 에이전트 오케스트레이션 환경을 직접 설계·구현합니다. 파일 기반 메모리, 키워드·시맨틱 검색, 에이전트 간 작업 분배를 재사용 가능한 인프라로 체계화하고, 반복되는 운영 문제는 Skill·훅·CLI 도구로 추상화해 팀 전체가 쓸 수 있는 형태로 표준화합니다. AI 파이프라인을 막연히 붙이지 않고 토큰 비용·지연·정확도를 직접 측정하며, 모델 티어링과 프롬프트 구조를 A/B로 검증해 비용과 품질의 최적점을 찾는 데 강점이 있습니다. 추측이 아니라 로그와 데이터로 원인을 규명해 가장 효율적인 해결책을 설계하고, 만든 것을 도구화해 팀 생산성으로 환원하는 방식으로 일합니다.
이 저자의 글 모두 보기 →이 글이 도움이 되셨나요?
인포그랩 전문가가 맞춤 상담을 도와드립니다.
관련 글

n8n 기반 DevOps·AI 콘텐츠 자동 수집·요약 실전 가이드
백엔드 엔지니어 Andy는 n8n으로 기술 콘텐츠 자동 수집·요약 시스템을 구축했습니다. 이 시스템은 주 3회 40여 개의 채널을 자동으로 모니터링하고, DevOps·AI·자동화 콘텐츠를 선별해 한국어로 요약합니다. 이 글은 콘텐츠 자동 수집·요약 시스템의 아키텍처와 핵심 구현 방법, 개발 과정에서 마주한 문제점과 해결 방안을 다뤘습니다.

n8n과 GitLab으로 개발팀 스탠드업 자동화하기
n8n, GitLab API, OpenAI, Slack을 연동하면 개발팀 스탠드업 자동화 시스템을 구축할 수 있습니다. GitLab에서 전날 작업 내용을 수집하고, 데일리 스탠드업 보고서를 생성해 Slack에 공유하는 과정을 모두 자동화할 수 있죠. 이 글은 스탠드업 자동화 워크플로와 관련 기술 스택, 설계 원칙, 결과를 다뤘습니다.

인포그랩의 n8n 기반 Notion PDF 자동화 후기
백엔드 엔지니어 Andy는 n8n을 사용해 Notion 문서를 PDF로 자동 변환하는 워크플로를 구축했습니다. 그 결과, 반복적인 문서 작업을 자동화해 업무 생산성을 높이고, 문서 품질도 향상했습니다. 이 글은 n8n 자동화 워크플로 구축 과정과 Pandoc 실행용 커뮤니티 노드 개발 과정, 표 레이아웃 조정, PDF 표지와 메타 데이터 삽입 등 전처리 자동화 과정을 다뤘습니다.