DORA 5대 지표로 보는 AI 시대 한국 엔터프라이즈 실행 가이드

아직도 DORA를 배포 빈도, 변경 리드타임, 변경 실패율, 서비스 복구 시간(MTTR) 네 가지 지표로 알고 계시나요? 이 4 Keys는 오랫동안 개발 성과의 표준 언어였는데요. 그러나 지금의 DORA는 그때와 달라졌습니다.
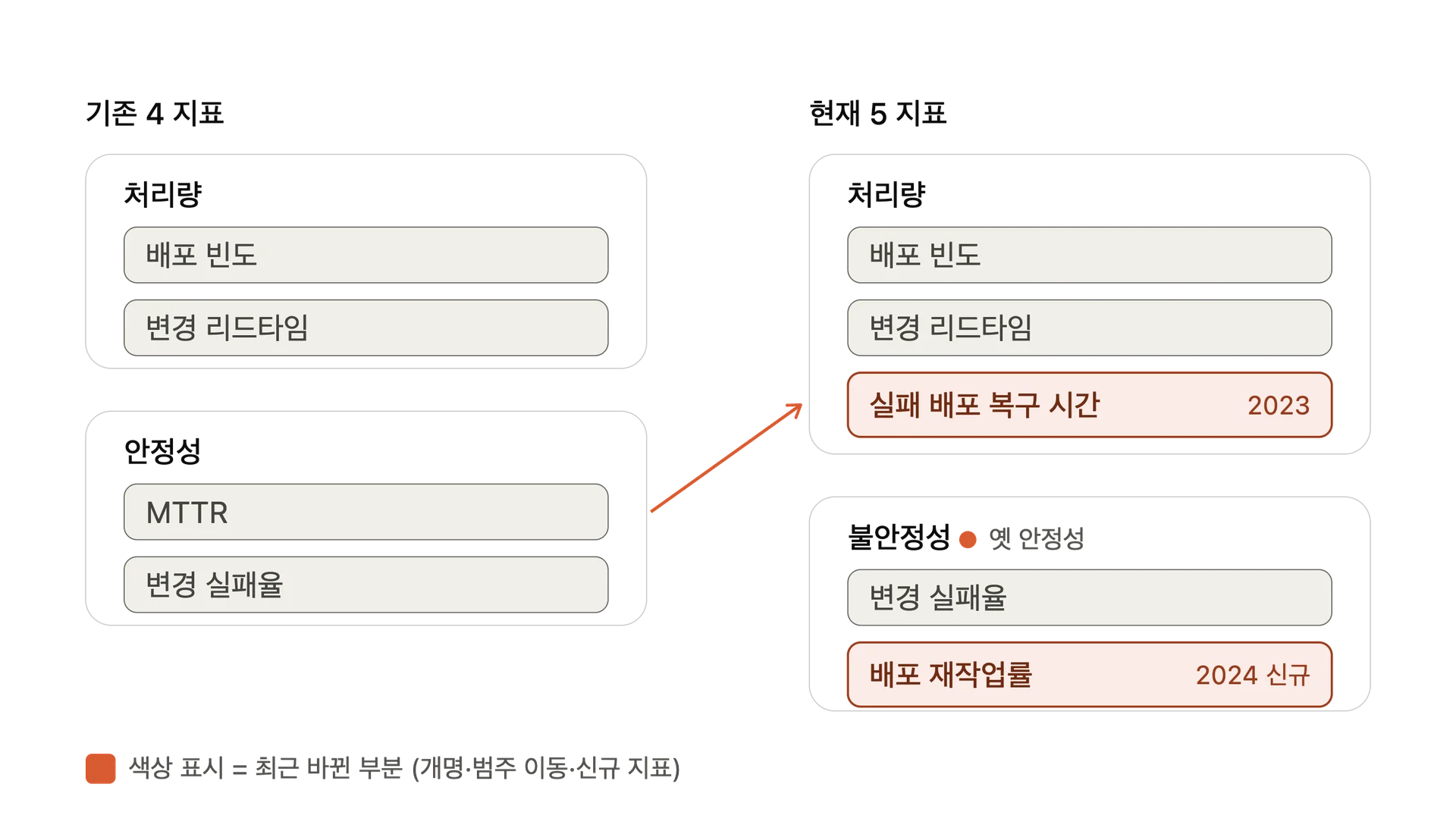
지표는 최근 몇 년에 걸쳐 재정의되고 확장됐는데요. 2023년 복구 시간 지표가 재정의됐고, 2024년 다섯 번째 지표인 '배포 재작업률'이 추가되며 범주까지 재편됐죠. 성과를 나누는 방식도 달라졌습니다. elite·high·medium·low라는 우열 등급은 사라지고, 팀을 7가지 유형으로 구분합니다. 바뀐 기준을 모른 채 옛 지표만 보고 있다면, 우리는 지금 잘못된 잣대로 팀의 개발 생산성과 DevOps 성숙도를 판단하고 있는 셈입니다.
이 변화가 형식적인 손질이었다면 굳이 따라갈 이유가 없겠죠. 그러나 새 지표와 새 분류는 하나의 현실을 겨냥합니다. 바로 AI로 개발 속도는 빨라졌지만 그 이면에 품질 비용이 쌓이고, 그 부작용이 팀마다 다르게 드러나는 현실이죠. 측정 기준이 바뀐 것은 신호일 뿐, 진짜 질문은 ‘그래서 무엇을 해야 하는가’로 모이고 있습니다.
이 글은 DORA 지표가 어떻게·왜 바뀌었는지(새 5대 지표와 7가지 팀 유형)를 짚고요. 한국 엔터프라이즈의 기술 조직이 준비해야 할 세 가지 과제, 우리 팀을 진단하고 로드맵을 그리는 도구를 제안하려 합니다.
DORA 지표, 무엇이 어떻게 바뀌었나: 5대 지표와 7가지 팀 유형
그동안 DORA는 배포 빈도, 변경 리드타임, 변경 실패율, 서비스 복구 시간(MTTR)과 같은 네 가지 지표로 알려져 왔습니다. 그러나 지금의 DORA는 다릅니다. 지표는 최근 몇 년에 걸쳐 재정의되고 확장됐는데요. 2023년 리포트에서 ‘복구 시간’ 지표가 재정의됐고, 2024년 리포트에서 다섯 번째 지표가 추가되며 범주가 재편돼 지금의 5 지표 모델이 자리 잡았습니다. 핵심은 기존 지표를 '교체'한 것이 아니라 '추가하고 재편'했다는 점입니다. 아울러 바뀐 것은 지표만이 아닙니다. 팀의 성과를 분류하는 방식까지 함께 달라졌습니다.
DORA 지표 모델: 4개에서 5개로
현재 DORA의 5대 지표는 처리량(Throughput)과 불안정성(Instability) 두 범주로 나뉩니다. 각 지표의 정의와 그동안의 변화는 다음과 같습니다.
| 범주 | 지표 | 개념 정의 | 비고 |
|---|---|---|---|
| 처리량 | 배포 빈도(Deployment Frequency) | 일정 기간 프로덕션에 성공적으로 배포한 횟수(또는 배포와 배포 사이의 간격) | |
| 처리량 | 변경 리드타임(Lead Time for Changes) | 코드가 버전 관리에 커밋된 시점부터 프로덕션에 배포되기까지 걸리는 시간 | |
| 처리량 | 실패 배포 복구 시간(Failed Deployment Recovery Time) | 실패해 즉각적인 조치가 필요한 배포로부터 복구하는 데 걸리는 시간 | 2023년 'MTTR(평균 복구 시간)'에서 개명·재정의(변경이 초래한 장애에 초점). 안정성→처리량 범주로 이동 |
| 불안정성 | 변경 실패율(Change Fail Rate) | 배포 후 즉각적인 조치(롤백·핫픽스 등)가 필요한 배포의 비율 | |
| 불안정성 | 배포 재작업률(Deployment Rework Rate) | 프로덕션에서 발생한 인시던트의 결과로 이뤄지는, 계획되지 않은 배포의 비율 | 2024년 신규 추가 |
DORA 지표 변화의 핵심은 그동안 처리량 지표만으로 드러나지 않던 '숨은 품질 비용'을 계측하는 것, 즉 다섯 번째 지표인 ‘배포 재작업률’ 추가입니다. 기존 '안정성(Stability)' 범주를 '불안정성(Instability)' 범주로 바꾼 것도, 관련 지표인 ‘변경 실패율’이나 ‘재작업률’이 시스템의 불안정성을 보여준다는 점에서 이러한 맥락의 연장선상에 있고요.
성과 분류도 바뀌었다: 4단계 등급에서 7가지 팀 유형으로
DORA 지표뿐만 아니라 성과를 분류하는 방식도 달라졌습니다. 과거 DORA는 팀을 elite·high·medium·low라는 성과 '등급'으로 분류했는데요. 그러나 2025년 리포트는 이 등급 사다리를 걷어내고, 팀을 7가지 유형(프로파일)으로 구분합니다. 단순 우열이 아니라 처리량·불안정성 지표에 팀 웰빙(번아웃·마찰 등)까지 더해 '어떤 종류의 팀인지' 구체적으로 그림을 그리는 거죠. '조화로운 고성과팀(harmonious high-achievers)'부터 '레거시 병목(legacy bottleneck)'에 갇힌 팀까지 스펙트럼이 다양합니다.
등급 체계를 걷어낸 데는 이유가 있습니다. elite·low 같은 우열 등급은 겉으로 드러난 성과는 보여줘도 왜 그런 성과가 나오는지, 그 팀이 건강한지까지 설명하지 못합니다. 리포트는 같은 지표 점수라도 그 원인이 전혀 다를 수 있다는 점, 번아웃·마찰과 같은 웰빙 신호가 처리량·실패율이 무너지기 전에 먼저 악화를 알리는 선행 지표라는 점에 주목하는데요. 이에 성과·안정성에 웰빙·업무 환경까지 함께 보는, 더 인간 중심적인 진단으로 전환한 거죠.
일곱 유형과 각 유형의 특징, 개략적인 개선 방향은 다음과 같습니다. 비중은 리포트 클러스터 분석 기준 팀 분포이며, 성과 순위가 아닙니다.
| 유형 (비중) | 핵심 특징 | 개략적 개선 방향 |
|---|---|---|
| 조화로운 고성과팀(Harmonious High-Achievers · 20%) | 높은 성과·낮은 번아웃·안정적 시스템의 선순환. 최상위 유형 | 현 수준 유지, 교차팀 학습·거버넌스 확장 |
| 실용적 성과팀(Pragmatic Performers · 20%) | 속도와 안정성을 꾸준히 달성하나 팀 몰입도는 개선 여지 | AI발 코드 리뷰·조율 부담 관리 |
| 프로세스에 갇힌 팀(Constrained by Process · 17%) | 시스템은 안정적이나 비효율적 프로세스가 번아웃 유발 | 프로세스 마찰 감소 |
| 안정적·체계적 팀(Stable and Methodical · 15%) | 신중한 속도로 높은 품질을 지속 가능하게 유지 | 자동화로 속도 확보(품질 유지) |
| 레거시 병목(Legacy Bottleneck · 11%) | 불안정한 레거시에 발목 잡혀 반응적 대응에 급급 | 아키텍처 현대화·배포 파이프라인 안정화 우선 |
| 기반 취약 팀(Foundational Challenges · 10%) | 성과·환경·결과 전반에서 고전하는 생존 모드, 높은 번아웃·마찰 | 기반(플랫폼·프로세스·문화) 재정비, 번아웃 완화 |
| 고임팩트·저속도 팀(High Impact, Low Cadence · 7%) | 성과는 강하나 불안정성이 높고 속도가 느림, 부담이 큰 환경 | 자동화로 안정성·속도 개선 |
핵심은 유형마다 개선 방향의 우선순위가 다르다는 점입니다. 예를 들어, 승인·결재 절차에 발목 잡혀 못 움직이는 팀과 SI 기반 레거시·마이그레이션에 묶인 팀은 가장 먼저 취해야 할 조치가 차이 날 수밖에 없습니다.
왜 이 재편이 지금 중요한가
'배포 재작업률' 지표를 추가하고 범주 명칭을 '불안정성'으로 바꾼 것, 팀을 7가지 유형으로 다시 나눈 것은 단순한 형식 변경이 아닙니다. 둘 다 AI로 가속화된 개발의 부작용, 그 부작용이 팀마다 다르게 드러나는 현실을 정면으로 다루기 위한 장치로 볼 수 있죠.
엔지니어링 인텔리전스 분석 기업 Faros AI가 2026년 펴낸 리포트는 그 부작용을 데이터로 보여주는데요. 이 리포트는 약 2만2000명의 개발자와 4000개 이상 팀의 2년 치 텔레메트리를 바탕으로, 각 조직에서 AI 도입이 가장 낮았던 시기와 가장 높았던 시기를 비교했습니다. 그 결과, AI 도입이 가장 높았던 시기 개인(수준)의 처리량은 AI 도입이 가장 낮았던 시기보다 늘었지만 품질·안정성 신호는 크게 악화된 것으로 나타났습니다.
구체적인 변화는 이렇습니다. AI 도입이 가장 높았던 시기는 가장 낮았던 시기와 비교해
- Pull request(PR) 한 건당 인시던트 비율 +242.7%
- 개발자당 버그 +54%
- 리뷰 없이 merge되는 PR +31%
속도가 빨라질수록 개발 품질이 불안정해지는 양상을 보였죠.
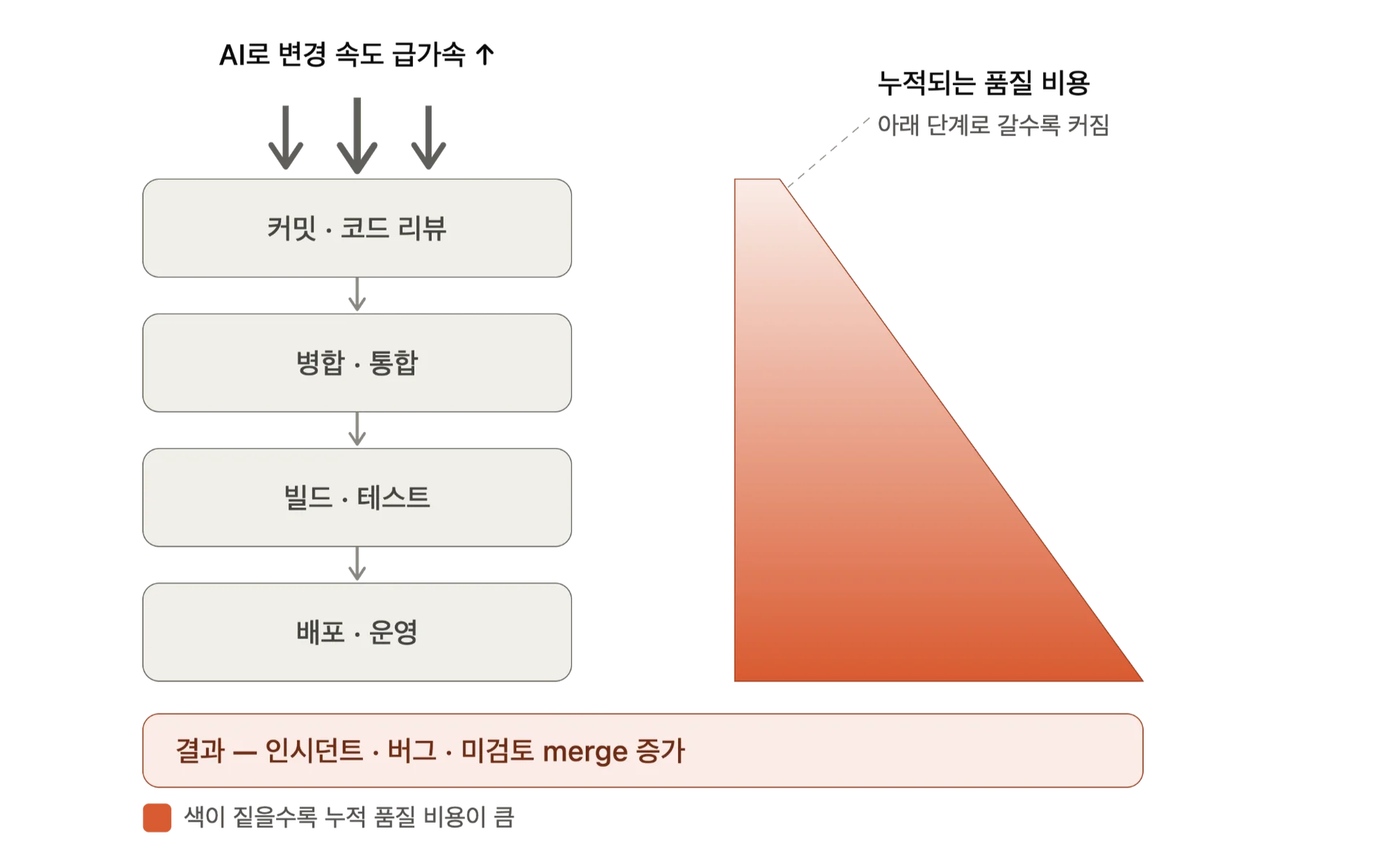
Faros는 이를 '가속 채찍효과(Acceleration Whiplash)'라고 정의했는데요. 이는 위에서 개발 속도는 빨라졌지만 아래 단계마다 품질 비용이 쌓인다는 의미입니다. 다만 이 데이터는 같은 팀을 시간순으로 추적한 종단 연구가 아니라 AI 도입 수준에 따른 단면 비교인데요. 인과 관계가 아니라 통계적으로 유의미한 상관관계라는 점을 고려해야 합니다.
단순히 처리량만 보면, 우리는 'AI로 개발 속도가 빨라져 생산성이 높아졌다'는 착시에 빠지기 쉽습니다. 그러나 변경 실패율, 배포 재작업률과 같은 불안정성 지표를 함께 살펴보면 착시를 예방하고, 속도 이면에 누적되는 품질 비용을 확인할 수 있죠.
이런 부작용을 고려했을 때, '우리 팀의 모습이 구체적으로 어떠한가'라는 진단도 결정적으로 중요합니다. 자기 팀 유형을 자세하고 명확히 파악해야 가장 효과적인 개선책을 찾고, AI 투자가 엉뚱한 곳에 새는 문제도 막을 수 있죠. 예를 들어, 배포 파이프라인이 병목인 '레거시 병목' 팀에 AI 코딩 도구만 잔뜩 늘린다면 그 투자는 근본적인 문제 해결에 도움이 되지 않을 수 있는데요. 구체적인 유형 진단부터 시작하면 본질적인 처방전을 정확히 찾아 현장에 적용하고 문제를 개선할 수 있습니다.
한 가지 짚어둘 점이 있습니다. 새 지표도 결국 베이스라인일 뿐, AI가 만든 코드와 사람이 쓴 코드를 구분해 지표를 정밀하게 해석하거나 방향성을 제시하지는 못합니다. 지표든 팀 유형 진단이든 우리 조직의 현재 위치 정도를 보여줄 뿐이죠. DORA 지표는 꾸준히 보완되고 변화하고 있지만 지표 자체가 정확하고 완전한 그림과 다음 방향성을 올바로 제시한다고 맹신하지 말아야 합니다. 우리 조직에서 이 지표를 추적하되, 지표에 어떤 한계가 있는지 염두에 두고 이를 보완할 방안을 모색하는 노력이 필요합니다.
AI 시대 DORA 역량, 무엇부터 준비해야 하나
DORA는 AI 시대 개발 트렌드를 반영해 지표(측정 기준)도, 성과 분류(7가지 팀 유형)도 새로 짰습니다. 새 지표로 우리 팀의 문제를 인식했다면, 이제 그 문제를 해결하는 역량이 중요한데요. 그렇다면 한국 엔터프라이즈의 기술 조직은 새로운 DORA 지표와 성과 분류 방식을 토대로 개발 생산성을 높이고, AI 활용 ROI까지 끌어올리기 위해 무엇을 해야 할까요?
순서가 있습니다. 가장 먼저 지표를 정확히 측정하고 분석해야 하는데요. 배포 재작업률과 같은 새로운 지표를 추적하고, 우리 팀이 7가지 유형 중 어디에 가까운지 파악합니다. 그다음에는 액션 포인트를 추출해 실행해야 하죠.
DORA는 AI를 성과로 바꾸는 일곱 가지 조직 역량을 제시하는데요. 이 글은 이 중 핵심 내용을 실행 순서에 따라 세 묶음으로 재구성해 살펴보려 합니다.
1. 되돌릴 수 있게 만들어라: 강력한 버전관리와 작은 배치
AI가 만든 변경일수록 더 작게 쪼개고, 언제든 즉시 되돌릴 수 있는 경로를 갖춰야 합니다.
배치가 작으면 변경 하나하나가 이해·리뷰·테스트하기 쉽습니다. 또 긴 브랜치를 병합할 때 생기는 충돌과 대규모 통합 작업이 줄어들죠. 문제가 생겨도 어느 변경이 원인인지 빨리 특정되고, 되돌릴 범위도 작아 롤백이 빨라집니다. 이는 '불안정성'을 낮추는 직접적인 경로가 될 수 있죠.
AI로 코드 생성량이 늘면 빌드·테스트·리뷰 부담이 커지고요. 변경이 쌓일수록 복잡도와 위험이 함께 불어납니다. 따라서 AI로 코드량이 증가할수록 '작게 쪼개 자주 통합하고 빠르게 되돌리는' 안전망을 구축해야 위험을 방어하는 데 도움이 됩니다. 이 안전망 없이 코드량만 늘리면, 새 지표는 불안정성이 올랐다는 경보만 울릴 뿐 문제를 방지하는 데 실질적으로 기여하기 어렵습니다.
실행 방법은 세 가지입니다.
- 트렁크 기반 개발과 CI를 기본으로: 작은 변경을 자주 트렁크에 통합하고, 커밋마다 자동 테스트가 돌게 하세요. 테스트가 깨지면 즉시 고치고, 몇 분 안에 못 고치면 일단 되돌리는 것을 팀 규칙으로 두는 걸 권장합니다.
- 기능 플래그로 '배포'와 '사용자 공개' 분리: 미완성 기능도 꺼 둔 채 안전하게 프로덕션에 올려 자동 테스트로 검증할 수 있고요. 문제가 생기면 코드를 되돌리는 대신 플래그만 꺼서 영향 범위를 즉시 차단할 수 있습니다.
- PR을 리뷰 가능한 크기로, 즉시 롤백 경로 상시화: PR을 '한 번에 리뷰할 수 있는 하나의 논리적 변경' 크기로 유지하세요. 원클릭 롤백이나 이전 배포로 복귀와 같은 즉시 롤백 경로를 배포 파이프라인에 상시 마련하는 것도 좋습니다.
2. AI에 우리 팀의 맥락을 주입하라: 건강한 데이터 생태계와 접근 가능한 내부 데이터
범용 모델의 일반적 답변을 넘어 AI가 우리 팀의 코드·문서·의사결정 기록에 안전하게 닿도록 구축해야 합니다.
AI 모델은 기본적으로 우리 팀 바깥의 일반 지식으로 답합니다. 여기에 내부 코드·문서·의사결정 기록을 연결하면, AI가 우리 팀의 컨벤션, 과거 결정과 그 이유, 시스템의 실제 구조와 같은 팀 고유의 컨텍스트를 기반으로 답하게 되죠. 그 결과 산출물은 우리 팀의 상황에 맞게 정확해지고, 코드 품질도 함께 좋아질 수 있습니다.
반대로 데이터가 흩어져 있거나 접근이 막혀 있으면, AI는 그럴듯하지만 우리 팀의 컨텍스트와 어긋나는 답을 내놓죠. 내부 데이터의 품질·접근성·통합은 AI가 조직 성과에 미치는 긍정적 영향을 크게 좌우합니다. 이 원칙을 한국 환경에 적용하면, 데이터 외부 반출 제약, 폐쇄망·에어갭 환경, 온프레미스 LLM 요구가 기본값인 조직일수록 '내부 컨텍스트를 얼마나 안전하게 연결하느냐'가 곧 AI 성패를 가르고요.
따라서 '무엇을, 어떻게 안전하게 연결할지'를 정교하게 설계하는 것이 중요합니다.
- AI가 닿아야 할 내부 지식 식별·정리: 소스 코드와 API 명세, 런북과 장애 대응 기록, 아키텍처 결정 기록과 리뷰 로그와 같은 내부 지식을 식별하고, 검색·참조가 가능한 형태(구조화된 저장소, 최신 상태로 유지되는 문서)로 정리하세요.
- AI가 참조하도록 연결: 이 데이터를 사내 지식 검색·RAG 등 방식으로 AI가 참조하도록 연결합니다. 이때 접근 권한·감사 로그·민감정보 마스킹을 처음부터 설계에 포함하세요.
- 거버넌스·보안 정책과 함께 설계: 특히 데이터 반출이 제약되는 환경이라면 어떤 데이터가 어디까지 나갈 수 있는지를 데이터 거버넌스·보안 정책과 함께 정해야 규제 환경에서도 지속 가능하게 이용할 수 있습니다.
3. 개인의 성과를 조직의 성과로 확장하라: 양질의 내부 플랫폼과 명확한 AI 방침
골든 패스와 셀프서비스 플랫폼 위에 AI를 얹고, 허용 도구와 사용 범위를 먼저 문서화해 공유해야 합니다.
AI는 개인 개발자의 코드 생산 속도를 높이지만, 그 코드는 리뷰·테스트·배포·통합이라는 공용 파이프라인을 통과해야 사용자에게 닿습니다. 이 단계가 표준화·자동화되지 않으면, 늘어난 개인 생산성은 병목에 걸려 흩어지고 불안정성만 키울 수 있죠.
양질의 내부 플랫폼은 표준 파이프라인, 셀프서비스 배포, 내장된 테스트·보안 통제와 같이 자동화된 안전한 '포장도로'를 제공하는데요. 이는 개인의 개발 속도 향상이 조직 전체의 성과로 안정적으로 이어지는 데 도움이 됩니다. 명확한 AI 방침까지 더해지면 효과는 더 커지죠. '무엇이 허용되는지'가 분명하면 팀이 안심하고 실험할 심리적 안전망이 확보되고요. 개인과 팀이 지키거나 넘어서는 안 될 선을 분명히 해 위험도 방지할 수 있습니다. 특히 규제 산업일수록 명확한 AI 사용 방침은 선결 조건이고요.
실행은 플랫폼과 방침 두 갈래입니다.
- 플랫폼: 골든 패스 위에 AI를 얹기: 개발자가 표준 파이프라인·환경·배포를 셀프서비스로 쓰는 '골든 패스'를 만들고 그 위에 AI 도구를 얹는 걸 권장합니다. 이때 테스트·보안·컴플라이언스 통제를 파이프라인에 내장해, 개발자가 매번 수동으로 챙기지 않아도 안전이 자동으로 보장되게 하는 것이 중요하죠.
- 방침: 허용 범위를 사전에 문서화·공유: 허용되는 AI 도구와 사용 범위(어떤 데이터를 넣어도 되는지, 어떤 작업에 어디까지 쓸 수 있는지)를 문서화해 먼저 공유하세요. 규칙이 사전에 분명하게 수립되면 현장이 위축되지 않고 AI로 안전하게, 적극적으로 실험할 수 있습니다.
우리 팀 DORA 유형 자가진단: 어디서부터 시작할까
아래 도구들은 지금까지 다룬 내용을 실무에 바로 적용할 수 있도록 이 글에서 구성한 자가진단 목록과 체크리스트입니다. DORA가 제공하는 공식 진단 양식은 아닌데요. 우리 팀의 현재 개발 상태를 가늠하고, 무엇부터 개선할지 계획을 수립하는 데 활용하시길 권장합니다.
도구 1: 우리 팀은 어느 유형인가 (자가진단)
아래 설명 중 우리 팀에 가장 가까운 유형을 고르고, 연결된 '먼저 살펴볼 곳'을 확인하세요.
| 우리 팀의 모습 | 가까운 유형 | 먼저 살펴볼 곳 |
|---|---|---|
| 무엇 하나 매끄럽지 않고, 압박이 크며, 전달이 느리다 | 기반 취약 팀 | 플랫폼으로 토대부터 재정비 |
| 똑똑한 사람들이 낡은 시스템에 갇혀 모든 게 너무 오래 걸린다 | 레거시 병목 | 안전망·플랫폼 |
| 무엇을 해야 할지 알지만, 승인·정책·회의가 추진력을 죽인다 | 프로세스에 갇힌 팀 | 우선순위·로드맵 + 방침으로 승인 간소화 |
| 결과물의 임팩트는 크지만, 전달이 느리고 때로 불안정하다 | 고임팩트·저속도 팀 | 우선순위·로드맵으로 병목 식별 후 작은 배치·자동화 확인 |
| 품질 우선이라 안정적이지만, 때로 제품 속도에 비해 너무 느리다 | 안정적·체계적 팀 | 작은 배치로 속도 확보 |
| 속도와 안정성은 탄탄하나, 팀 몰입도에 개선 여지가 있다 | 실용적 성과팀 | 데이터·플랫폼으로 고도화 |
| 낮은 스트레스, 높은 안정성, 빠른 전달, 훌륭한 문화 | 조화로운 고성과팀 | 현 수준 유지, 플랫폼·거버넌스로 확장 |
우선순위와 로드맵: 어떤 역량부터
DORA 리포트는 다음 실행 흐름을 제안합니다.
- 팀 유형 식별: 우리 팀이 어느 유형인지 진단합니다.
- 가치 흐름 매핑(VSM): 어디가 진짜 병목인지, 가치가 어디서 멈추는지 시각화합니다.
- 우선순위 워크숍: 진단과 병목을 근거로, 먼저 손댈 1~2개 역량을 정합니다.
- 로드맵 구축: 선택한 역량의 '첫 액션'부터 단계적으로 실행·측정합니다.
도구 2: 성숙도 자가 체크리스트
아래 항목에 솔직하게 답해 보세요. '아니오'가 많은 항목일수록 먼저 개선해야 할 영역입니다.
- 우리는 배포 재작업률과 불안정성 지표를 측정하고 있다.
- 처리량과 불안정성을 같은 대시보드에서 함께 본다.
- 우리 팀이 어느 유형인지 안다.
- AI가 만든 변경일수록 더 작은 배치로 다루고, 즉시 롤백 경로가 있다.
- AI가 우리 내부 코드·문서·결정 기록에 안전하게 접근할 수 있다.
- 허용 AI 도구와 사용 범위에 대한 명확한 방침이 문서화·공유돼 있다.
위 두 도구는 우리 팀의 현재 위치와 먼저 개선할 지점을 스스로 가늠하기 위한 출발점입니다. 실제 DORA 지표 데이터에 기반한 정밀한 유형 진단, 병목의 정량적 분석, 조직 맥락에 맞춘 역량 로드맵 설계가 필요하다면 GitLab·DevOps 도입과 엔지니어링 문화 개선을 지원해 온 인포그랩이 도와드릴 수 있습니다.
맺음말
지금까지 DORA의 새 5대 지표와 7가지 팀 유형이 무엇을·왜 바꿨는지 짚고, 한국 엔터프라이즈의 기술 조직이 준비할 세 가지 준비 과제, 자가진단 도구를 살펴봤습니다. 요점은 다음과 같은데요.
- 측정 기준이 바뀌었습니다. DORA는 '복구 시간'을 재정의하고 '배포 재작업률'을 더해 5대 지표로 확장했으며, 우열 등급을 걷어내고 팀을 7가지 유형으로 나눴습니다. 처리량만 보면 'AI로 빨라졌다'는 착시에 빠지지만, 불안정성 지표를 함께 보면 속도 이면에 쌓이는 품질 비용이 드러납니다.
- 새 지표는 문제를 보여줄 뿐, 문제를 해결하는 것은 역량입니다. AI는 증폭기라 강한 시스템은 더 강해지고 약한 시스템은 더 빨리 깨집니다. 따라서 우리 팀이 7가지 유형 중 어디인지 진단하는 일이 출발점이 되죠. 진단 없이 코딩 도구만 늘리면 투자는 엉뚱한 곳으로 샙니다.
- 대처 방안은 세 가지로 좁혀집니다. 첫째, 작은 배치와 강력한 버전관리로 되돌릴 수 있게 만드세요. 둘째, 내부 데이터를 안전하게 연결해 AI에 우리 팀의 맥락을 주입하세요. 셋째, 양질의 내부 플랫폼과 명확한 AI 방침으로 개인의 성과를 조직의 성과로 확장하세요. 데이터 반출 제약과 폐쇄망이 기본값인 한국 엔터프라이즈에서는 '안전한 연결'이 특히 성패를 가릅니다.
- 측정과 진단은 도구가 아니라 시스템의 문제입니다. 자가진단으로 현재 위치와 먼저 개선할 지점을 가늠하되, 실제 지표 데이터에 기반한 정밀 진단과 로드맵 설정은 그다음 단계입니다. 측정 기준이 바뀐 지금은 우리 조직의 개발 생산성과 DevOps 성숙도를 다시 진단하고 로드맵을 그릴 적기입니다.
배포 속도만 보면 쌓인 품질 비용이 보이지 않습니다
처리량이 좋아져도 불안정성 지표를 함께 보지 않으면, 빨라진 만큼 어디에 부담이 쌓였는지 놓치게 됩니다. 인포그랩이 처리량과 불안정성을 한 대시보드에서 측정하고, 팀 유형까지 진단하도록 돕습니다.
참고 자료
- Kevin M. Storer, Derek DeBellis, "Introducing DORA's inaugural AI Capabilities Model: 7 keys to succeeding in AI-assisted software development", Google Cloud Blog, 2025-09-23, https://cloud.google.com/blog/products/ai-machine-learning/introducing-doras-inaugural-ai-capabilities-model
- "DORA AI Capabilities Model report", DORA (Google Cloud), 2025, https://dora.dev/ai/capabilities-model/report/
- Nathen Harvey, Allison Park, "From adoption to impact: Putting the DORA AI Capabilities Model to work", Google Cloud Blog, 2025-12-10, https://cloud.google.com/blog/products/ai-machine-learning/from-adoption-to-impact-putting-the-dora-ai-capabilities-model-to-work
- "2025 DORA State of AI-assisted Software Development report", Google Cloud, 2025, https://cloud.google.com/resources/content/2025-dora-ai-assisted-software-development-report
- Nathen Harvey, "DORA’s software delivery performance metrics", DORA, 2026-01-05, https://dora.dev/guides/dora-metrics-four-keys/
- "Working in small batches", DORA DevOps Capabilities, https://dora.dev/capabilities/working-in-small-batches/
- "Trunk-based development", DORA DevOps Capabilities, https://dora.dev/capabilities/trunk-based-development/
- Andrew Davis, Rob Edwards, "How to use value stream mapping to improve software delivery", DORA Guides, https://dora.dev/guides/value-stream-management/
- "DevOps Capabilities catalog", DORA, https://dora.dev/capabilities/
- Faros AI, "AI Engineering Report 2026: The Acceleration Whiplash", 2026-03, https://pages.faros.ai/hubfs/AI_Engineering_Report_2026_The_Acceleration_Whiplash_Faros.pdf

이 글이 도움이 되셨나요?
인포그랩 전문가가 맞춤 상담을 도와드립니다.