AI 에이전트에 메모리를 더 많이 주면 더 똑똑해질까?

AI 에이전트는 CI/CD 파이프라인 리뷰를 곧잘 해냅니다. 이는 Job 순서 오류, 하드코딩된 값, 캐시 설정 누락과 같은 문제를 정확히 탐지하죠.
그러나 에이전트를 운영하다 보면 한 가지 비효율이 눈에 띕니다. LLM 기반 에이전트는 세션이 끝나면 이전 작업 이력이 모델 자체에서 사라집니다. 지난 세션에서 에이전트가 “이 파이프라인에는 Runner 태그가 빠졌다"고 결론을 내려도 오늘 새 세션에서는 그 판단을 처음부터 다시 추론합니다. 이미 결론이 난 추론 경로를 매 세션에서 재구성하면 토큰과 시간을 중복으로 소모합니다.
Claude Code를 사용한다면, Auto Memory가 대화에서 학습한 내용을 자동으로 기록해 다른 세션에서도 활용할 수 있습니다. 그러나 Auto Memory는 Claude가 세션에서 '유용하다'고 판단한 맥락을 선별해 기록합니다. “이 팀 파이프라인은 항상 Runner 태그를 빠뜨린다"와 같은 패턴이 반드시 기록된다는 보장은 없죠. 물론 Auto Memory에 맥락을 수동으로 추가할 수 있지만 번거롭습니다.
맥락 단절은 에이전트에 기억을 부여하면 해결할 수 있습니다. 현재 세션의 판단을 캐싱해 반복 추론을 줄이는 세션 캐시, 과거 추론 이력과 조직 지식을 저장해 세션과 프로젝트 사이를 잇는 외부 저장소가 대표적인 접근 방식이죠. 이 글에서는 Claude Code 에이전트에서 세션 캐시(claude-mem)와 외부 저장소(Vault KV·Milvus·Mem0)를 다양한 방식으로 조합한 메모리 계층 구성을 비교합니다. 약 2,650회 실험으로 토큰 사용량·응답 시간·정확도를 측정하면서 메모리 계층 구성이 에이전트의 응답 비용과 품질에 어떤 영향을 주는지 살펴보겠습니다.
실험 배경: 기억하지 못하는 에이전트
저는 이번 실험에 앞서 Claude Code에서 CI/CD 파이프라인 리뷰에 특화된 세 에이전트를 아래와 같이 운영했습니다.
- PipelineReviewer: 파이프라인 구조와 Job 의존성을 분석합니다. Runner 태그, 캐시 설정, 아티팩트 관리를 점검합니다.
- SecurityReviewer: 파이프라인 내 시크릿 하드코딩과 과도한 권한 설정을 탐지합니다.
- PerformanceReviewer: 파이프라인 실행 시간과 병렬화 기회를 분석합니다. 불필요한 Job을 확인하고, 최적화 가능한 캐시 전략을 제안합니다.
제가 마스킹 된 파이프라인 스니펫과 리뷰 지시를 에이전트 팀의 리드에게 전달하면, 리드가 세 에이전트에게 작업을 분배했습니다. 그러면 에이전트가 자기 역할에 따라 구조·보안·성능 관점에서 파이프라인을 점검했고, 그 결과물이 통합 리포트로 나왔습니다.
세 에이전트는 잘 작동했습니다. 그러나 저는 운영 과정에서 ‘에이전트가 실행될 때마다 매번 같은 정보를 다시 읽는 데 비용이 많이 들어간다’고 느꼈습니다. 저는 이 비용을 줄이기 위해 에이전트가 이전 작업을 ‘기억’하게 만들고 싶었습니다. 이를 위해 제가 에이전트의 메모리를 구성한 방식을 소개하겠습니다.
설계: Claude Code 기본 메모리에 두 계층을 더하다
앞서 설명했듯 저는 Claude Code에서 CI/CD 파이프라인 리뷰 에이전트를 운영했습니다. Claude Code는 기본 메모리 기능으로 ‘Auto Memory’를 제공합니다. Auto Memory는 Claude가 세션에서 '유용하다'고 판단한 맥락을 선별해 기록하고, 다음 세션에서 이를 다시 불러옵니다.
저는 이 기본 메모리만으로는 부족하다고 판단했습니다. Auto Memory는 세션 간 지식을 유지하지만, 선별적 기록이라 이전 세션에서 에이전트가 내린 판단이 다음 세션에서 그대로 복원된다는 보장이 없습니다. 예를 들어, “이 팀 파이프라인은 항상 Runner 태그를 빠뜨린다”와 같은 누적 리뷰 패턴은 Claude가 유용성을 인식해 기록하지 않으면 Auto Memory에 남지 않습니다. 필요하다면 사람이 직접 Auto Memory에 수동으로 입력해야 하죠.
또 Auto Memory는 로컬 파일 시스템에 저장됩니다. 따라서 조직 차원의 참고 지식을 원활하게 공유하는 데 한계가 있습니다. 저는 이 한계를 보완하기 위해 Claude Code의 기본 메모리에 두 개의 캐시 계층을 추가하기로 했습니다.
세션 캐시 — claude-mem
제가 추가한 첫 번째 캐시 계층은 ‘세션 캐시’입니다. 세션 캐시는 에이전트가 현재 세션에서 내린 판단과 중간 결과를 별도 저장소에 기록해 뒀다가 다음 세션이 시작될 때 이를 다시 불러오는 계층입니다. Auto Memory가 Claude의 자율적 판단으로 맥락을 선별 기록하는 것과 달리, 세션 캐시는 에이전트의 도구 사용 결과와 중간 판단을 자동으로 캡처해 저장합니다. ‘유용성 판단’이라는 선별 과정을 거치지 않아 이전 세션의 판단이 다음 세션에 더 일관되게 전달된다는 점이 Auto Memory와 큰 차이입니다.
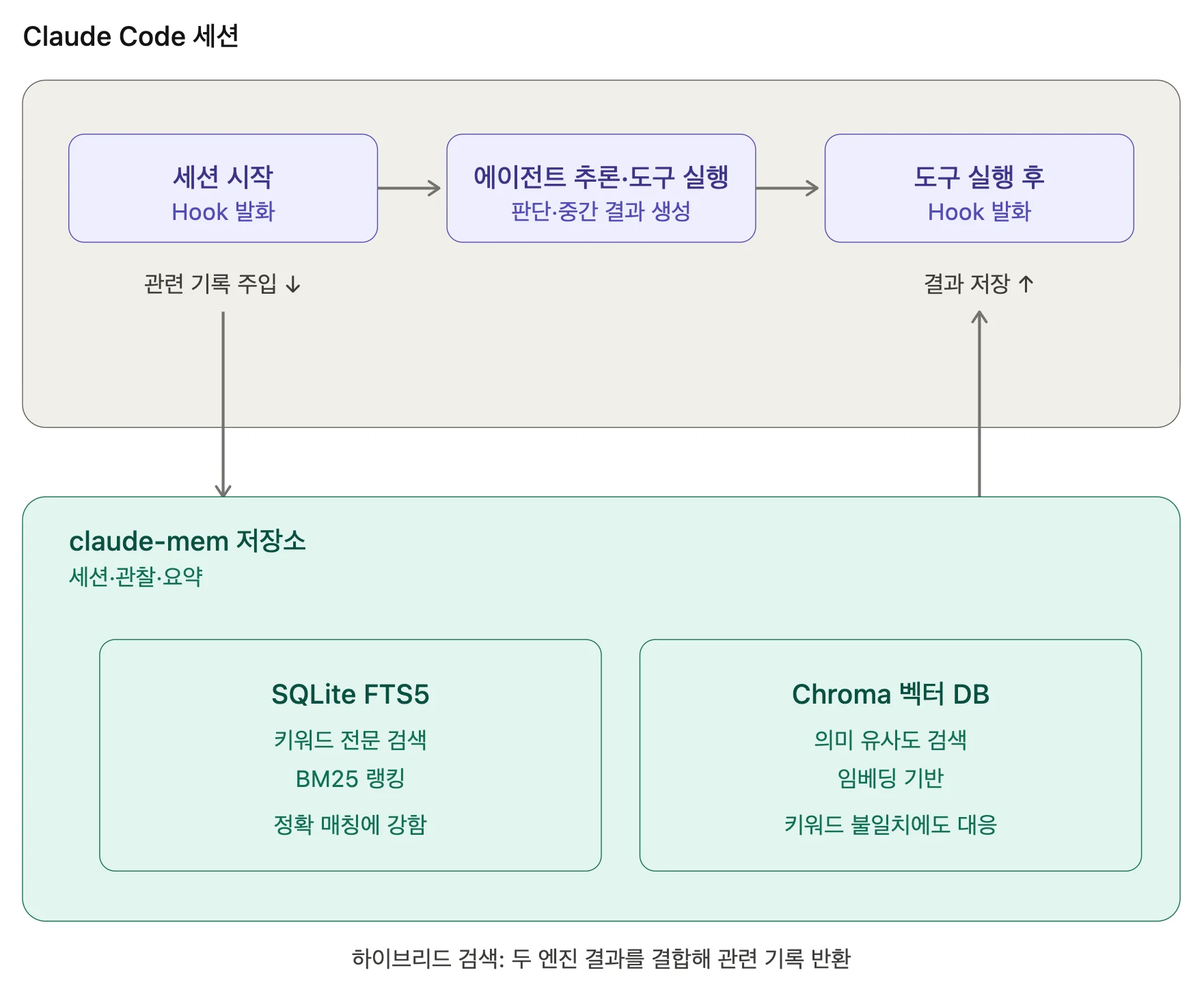
이 실험에서는 claude-mem을 세션 캐시로 사용했습니다. claude-mem은 SQLite에 세션·관찰·요약을 저장하고, SQLite의 FTS5(Full-Text Search 5) 엔진과 Chroma 벡터 DB를 결합한 하이브리드 방식으로 검색을 수행합니다. FTS5는 저장된 텍스트를 BM25 랭킹으로 인덱싱해 키워드 기반 전문 검색을 빠르게 수행하는 SQLite 확장이고, Chroma는 의미 유사도 기반 검색을 담당합니다. 두 방식을 함께 사용하기에 키워드가 정확히 일치하지 않을 때도 관련 기록을 찾을 수 있습니다.
claude-mem은 Claude Code의 Lifecycle Hooks로 과거 기록을 에이전트에 주입합니다. Lifecycle Hooks는 세션 시작·사용자 입력·도구 실행 후·세션 종료와 같은 특정 시점에 사용자가 지정한 스크립트를 자동 실행하는 Claude Code의 확장 기능입니다. claude-mem은 이 Hook에 자신의 스크립트를 등록해 세션이 시작될 때 저장소에서 관련 기록을 꺼내 프롬프트에 주입하고, 도구 실행 후에는 그 결과를 다시 저장합니다. 에이전트가 ‘기억하는 것처럼’ 보이는 동작은 바로 이 Hook 기반 주입과 저장의 반복에서 나옵니다.
외부 저장소 — Vault KV / Milvus / Mem0
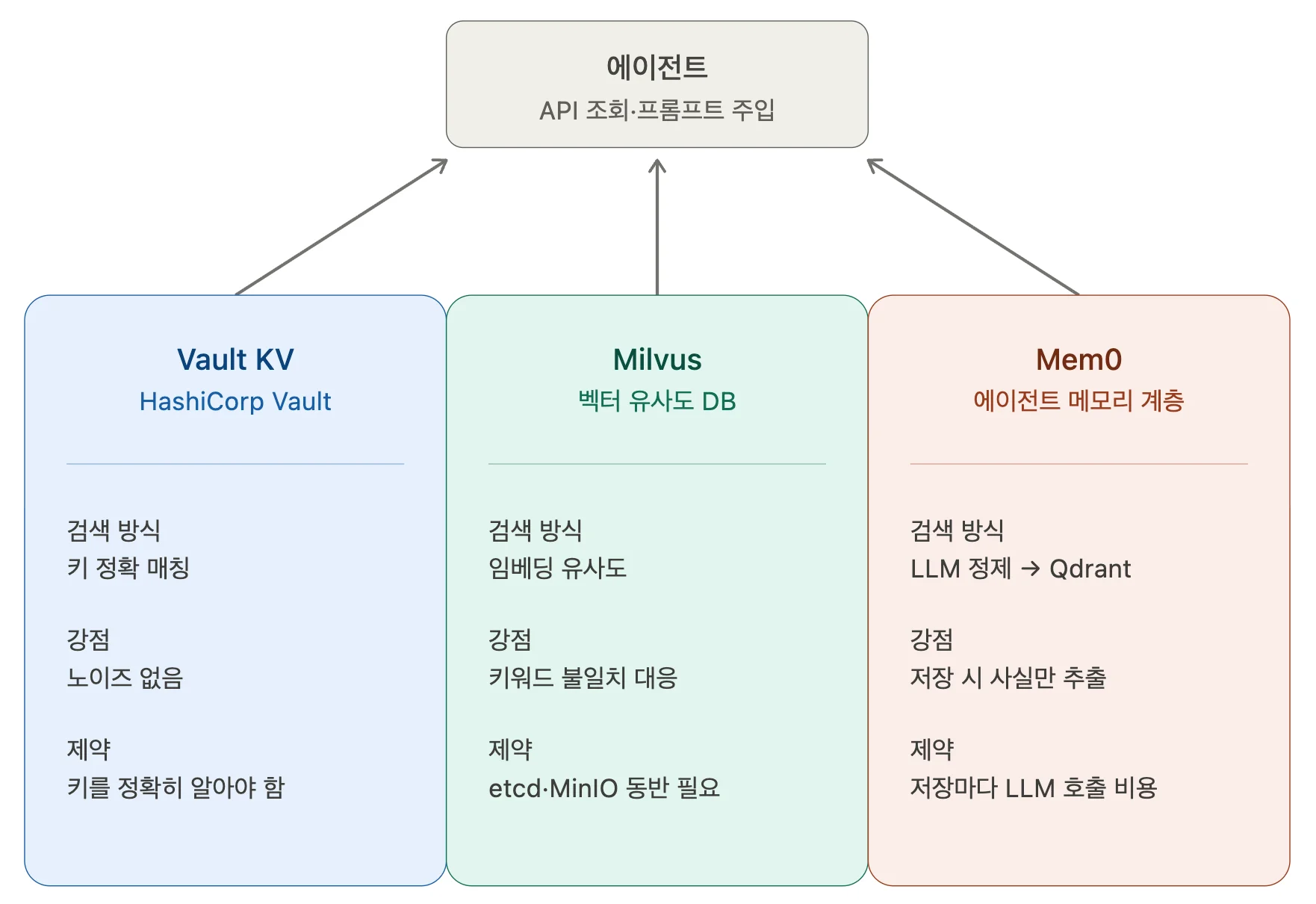
제가 추가한 두 번째 캐시 계층은 '외부 저장소'입니다. 외부 저장소는 에이전트의 과거 리뷰 이력과 조직 차원의 참고 지식을 에이전트 바깥의 전용 서비스에 저장하고, 필요할 때마다 API로 조회해 프롬프트에 주입하는 계층입니다. Auto Memory가 로컬 파일 시스템에 머무는 것과 달리 외부 저장소는 여러 세션과 프로젝트가 함께 참조할 수 있는 공유 지점을 만듭니다.
문제는 어떤 외부 저장소가 이 역할에 가장 적합한지 미리 알기 어렵다는 점이었습니다. 이에 저는 성격이 다른 세 가지 저장소를 모두 후보로 두고 함께 비교하기로 했습니다.
- Vault (HashiCorp Vault의 KV 저장소): Vault는 원래 시크릿 관리 도구이지만, 내부적으로 키-값(key-value) 데이터를 저장하고 조회하는 단순 저장 기능도 제공합니다. 이 실험에서는 시크릿 관리 기능은 사용하지 않고, 오직 이 KV 저장 기능만 활용해 메모리 저장소로 썼습니다. 키로 정확히 일치하는 값만 반환하는 방식이라 검색 결과에 불필요한 데이터가 섞이지 않습니다. 대신 키를 정확히 알아야 찾을 수 있다는 제약이 있습니다.
- Milvus (벡터 유사도 검색 DB): Milvus는 텍스트나 코드를 벡터 임베딩으로 변환해 저장하고, 쿼리 역시 벡터로 변환해 유사도가 높은 기록을 찾아내는 전용 데이터베이스(DB)입니다. 키워드가 정확히 일치하지 않아도 의미가 가까운 과거 기록을 찾을 수 있습니다. 예를 들어, "Runner 태그 빠진 Job"이라는 쿼리로, 과거에 "빌드 단계에서 러너가 지정되지 않아 파이프라인이 대기했다"라고 기록된 이력을 찾아내는 식입니다. 대신 standalone 모드 기준으로 etcd(메타데이터 저장)와 MinIO(오브젝트 저장)를 함께 띄워야 동작하기에 운영 부담이 비교적 큽니다.
- Mem0 (AI 에이전트 메모리 계층): Mem0은 LLM 에이전트용 메모리 관리 계층입니다. 대화나 관찰 기록을 그대로 저장하지 않고, LLM을 한 번 더 호출해 핵심 사실만 추출한 뒤 Qdrant 벡터 DB에 저장합니다. Qdrant는 오픈 소스 벡터 DB로, Mem0의 기본 백엔드 역할을 합니다. 저장 단계에서 사실을 요약·정제해 노이즈가 적지만, 매번 LLM 호출이 발생해 저장 비용이 추가됩니다.
지금까지 설명한 두 계층과 Claude Code의 Auto Memory를 합치면, 이번 실험의 에이전트 메모리 계층 구조는 다음과 같이 정리됩니다. 위로 갈수록 접근이 빠르고 범위가 좁으며, 아래로 갈수록 지속성과 공유 범위가 커지는 구조입니다.
| 계층 | 구성 | 접근 특성 | 범위 |
|---|---|---|---|
| L1 세션 캐시 | claude-mem (SQLite FTS5 + Chroma) | Lifecycle Hooks 기반 주입·캡처, 키워드(BM25)와 벡터 유사도 하이브리드 검색 | 세션·프로젝트 (로컬) |
| L2 기본 메모리 | Auto Memory | 세션 시작 시 MEMORY.md 주입 + 토픽 파일 on-demand 로드, Claude의 자율 판단으로 선별 기록 | 프로젝트 (레포 단위, 로컬) |
| L3 외부 저장소 | Vault KV / Milvus / Mem0 | 전용 저장소 호출(키 일치·벡터 유사도·LLM 정제 검색), 영구 저장 | 세션·프로젝트 공유 |
실험 계획: 5개 시나리오
설계를 마친 뒤, 다음과 같이 5가지 실험 시나리오를 계획했습니다. 핵심은 에이전트 메모리의 각 계층 기여도를 분리해 측정하고, 실질적으로 효과적인 계층을 확인하는 것이었습니다.
| 시나리오 | 구성 | 검증 목표 |
|---|---|---|
| A | 메모리 계층 추가 없음 (베이스라인) | 기준선 확립 |
| B | L1 (claude-mem) 단독 | 세션 캐시 단독 효과 |
| C | L1 + Vault KV | 키 정확 매칭의 효과 |
| D | L1 + Milvus | 벡터 유사도 검색의 효과 |
| E | L1 + Mem0 | LLM 정제 메모리의 효과 |
모든 시나리오에서 Claude Code Auto Memory(L2)는 활성화된 상태이며, 시나리오 간 차이는 L1(세션 캐시)과 L3(외부 저장소) 구성에 한정합니다. 베이스라인(A)은 L1·L3를 추가하지 않은 Auto Memory 단독 상태를 의미합니다.
세션 캐시와 외부 저장소가 에이전트 메모리에 미치는 영향을 폭넓게 탐색하기 위해 실험 프롬프트는 GitLab CI/CD 리뷰에 한정하지 않고 범용 DevOps 질문(힙 덤프 분석, Kubernetes 디버깅, Zero Trust 아키텍처 등)으로 구성했습니다.
실험 설정
| 항목 | 값 |
|---|---|
| 모델 | Claude Sonnet 4.5 |
| Context Window | 200K 토큰 |
| 프롬프트 | 10개 (simple 3개, medium 4개, complex 3개) |
| 시나리오당 반복 | 5회 (파일럿) / 20회 (확장 실험) |
| 측정 항목 | 리뷰당 토큰, 응답 시간, 정확도 |
| 총 호출 수 | 약 2,650회 (3주, 3/19~4/3) |
총 호출 수 내역은 파일럿 실험 250회(5 시나리오 × 10 프롬프트 × 5회) + 확장 실험 2,400회(4 시나리오 × 30 프롬프트 × 20회)입니다.
정확도 측정 방식
이 글에서 정확도란 ‘키워드 재현율(keyword recall)’을 의미합니다. 각 프롬프트에 expected_keywords 배열을 미리 정의하고, 에이전트 응답에 해당 키워드가 포함된 비율을 점수로 환산합니다.
def score_accuracy(output: str, prompt_info: dict) -> float:
"""키워드 기반 간이 정확도 측정 (0.0 ~ 1.0)"""
if not output:
return 0.0
keywords = prompt_info.get("expected_keywords", [])
if not keywords:
return 0.5 # 키워드 없으면 중간값
output_lower = output.lower()
hits = sum(1 for kw in keywords if kw.lower() in output_lower)
return round(hits / len(keywords), 2)
난이도별 프롬프트 예시는 다음과 같습니다.
| 프롬프트 | 난이도 | 키워드 | 측정 의도 |
|---|---|---|---|
| S01 (버그 찾기) | simple | ZeroDivisionError, 빈 리스트, len(numbers) == 0 | 핵심 버그 식별 여부 |
| M01 (K8s 디버깅) | medium | CrashLoopBackOff, OOMKilled, 리소스 제한, 로그, describe | 진단 키워드 포함 여부 |
| C01 (AWS 설계) | complex | VPC, ALB, ECS, Fargate, RDS, terraform, module, autoscaling | 아키텍처 구성요소 포함 여부 |
이 방식은 recall 위주의 간이 지표로, 응답의 논리적 정확성이나 깊이는 반영하지 않습니다. 그럼에도 약 2,650회 규모에서 시나리오 간 상대 비교에는 유효하다고 판단했습니다.
실험 한계
- 통계적 유의성: 파일럿의 반복 5회는 통계적 유의성이 제한적입니다.
- 측정 방식: 키워드 매칭은 리뷰 품질의 모든 측면을 반영하지 않습니다.
- 캐시 재주입 효과: 세션 캐시의 이전 응답이 다음 프롬프트 입력에 재주입될 경우, 정확도 향상이 모델의 실질적 이해 개선인지 키워드 재노출 효과인지 구분하기 어렵습니다.
- 순서 효과: 시나리오 실행 순서(A→B→C→D→E)를 무작위화하지 않아 앞선 시나리오의 캐시가 후속 시나리오에 영향을 줄 가능성이 있습니다.
- 유즈케이스 일반화: 이 실험은 CI/CD 리뷰 에이전트의 성능이 아니라 ‘세션 캐시와 외부 저장소가 에이전트 메모리에 미치는 영향’에 대한 탐색적 근거로 해석하는 것이 적절합니다.
실험 결과: 직접 돌려보니
이제 본격적으로 시나리오별로 실험을 진행했습니다. 메모리 계층을 시나리오별로 다르게 구성한 상태에서 동일한 프롬프트 셋을 입력하고, 토큰 사용량·응답 시간·정확도를 측정했습니다.
파일럿 실험
먼저 베이스라인부터 세션 캐시, 외부 저장소 결합까지 다섯 시나리오를 실행했습니다. 결과를 한 표에 모으면 다음과 같습니다.
| 항목 | A (베이스라인) | B (L1 단독) | C (L1 + Vault KV) | D (L1 + Milvus) | E (L1 + Mem0) |
|---|---|---|---|---|---|
| 리뷰당 토큰 | 1,435 | 1,403 | 1,203 | 1,361 | 1,352 |
| 토큰 변화 | — | -2.2% | -16.2% | -5.2% | -5.8% |
| 응답 시간 | 28,386ms | 24,552ms | 22,319ms | 25,232ms | 24,878ms |
| 시간 변화 | — | -13.5% | -21.4% | -11.1% | -12.4% |
| 정확도 | 0.60 | 0.61 | 0.45 | 0.43 | 0.41 |
| 정확도 변화 | — | +1.7% | −25.0% | −28.3% | −31.7% |
실험 결과, 토큰·응답 시간 절감 효과와 정확도는 비례하지 않았습니다.
메모리 계층을 추가한 네 시나리오 모두(B, C, D, E) 메모리 계층을 추가하지 않은 베이스라인(A)보다 토큰 사용량과 응답 시간이 줄었습니다. 토큰 사용량과 응답 시간이 가장 큰 폭으로 줄어든 것은 C였습니다(토큰 절감 -16.2%, 시간 단축 -21.4%). ‘에이전트가 같은 추론을 반복하면서 토큰과 응답 시간을 중복으로 소모한다’는 이 글의 초반 문제의식은 메모리 계층 추가로 어느 정도 해결된다는 뜻입니다.
그러나 정확도는 별개였습니다. 베이스라인(A)의 정확도 0.60을 넘은 시나리오는 B 단 하나(0.61)뿐이고, 외부 저장소를 더한 C, D, E는 모두 0.45 이하로 떨어졌습니다. 에이전트에 메모리 계층 추가로 기억을 부여하면, 토큰 사용량과 응답 시간을 절감할 수 있지만 반드시 더 정확한 판단을 내리는 건 아니라는 점을 확인할 수 있었습니다.
확장 실험
위 파일럿 실험은 실전 실험의 방향을 잡기 위한 단계였습니다. 어떤 시나리오가 유망한지 가려냈으니 이어서 실험 규모를 키워 본격적인 검증을 진행했습니다.
확장 실험 설정
| 항목 | 값 |
|---|---|
| 시나리오 | 4개 (A, B, C, E) |
| 프롬프트 | 30개 |
| 시나리오당 반복 | 20회 |
| 확장 실험 총 호출 수 | 2,400회 |
| 통계 검정 | Welch's t-test, 모든 비교에서 p < 0.0001 |
시나리오 D(L1 + Milvus)는 확장 실험에서 제외했습니다. 실용성을 판단했을 때, Milvus는 etcd와 MinIO 의존성으로 장기 운영 비용이 높아 실험 대상에 포함하지 않았습니다.
결과
| 항목 | A (베이스라인) | B (L1 단독) | C (L1 + Vault KV) | E (L1 + Mem0) |
|---|---|---|---|---|
| 리뷰당 토큰 | 1,034 | 1,816 | 1,594 | 1,043 |
| 토큰 변화 | — | +75.6% | +54.2% | +0.9% |
| 응답 시간 | 22,044ms | 37,006ms | 33,946ms | 23,386ms |
| 시간 변화 | — | +67.9% | +54.0% | +6.1% |
| 정확도 | 0.413 | 0.736 | 0.467 | 0.324 |
| 정확도 변화 | — | +78.2% | +13.1% | -21.5% |
실험 결과, 파일럿 실험에서 관찰한 메모리 계층 추가에 따른 토큰·응답 시간 절감 효과가 이번에는 재현되지 않았습니다.
메모리 계층을 추가한 세 시나리오(B, C, E) 모두 베이스라인(A)보다 토큰을 더 많이 썼고, 응답 시간도 훨씬 더 길어졌습니다. 가장 큰 폭으로 늘어난 것은 B였습니다(토큰 변화 +75.6%, 시간 변화 +67.9%). 이는 호출 누적으로 이전 대화 맥락이 컨텍스트로 더 많이 주입된 영향으로 풀이됩니다.
정확도는 시나리오에 따라 크게 나뉘었습니다. B는 베이스라인(A, 0.413)보다 78.2% 향상한 반면(0.736), C는 13.1% 향상하는 데 그쳤습니다(0.467). 특히 E는 21.5% 하락해 베이스라인(A)보다도 낮았습니다(0.324). 즉, B처럼 세션 캐시만 단독으로 추가하면 에이전트의 정확도가 크게 높아지지만, 외부 저장소를 추가하면 정확도 향상이 제한적이거나 오히려 더 떨어졌습니다.
결과 분석: 왜 더 많은 메모리가 더 나쁜 결과를 만들었나
파일럿 실험과 확장 실험에서는 모두 동일한 패턴이 관찰됐습니다. 외부 저장소를 추가할수록 정확도가 떨어졌고, 확장 실험에서는 토큰·응답 시간 절감 효과마저 사라졌습니다. 저는 ‘Context Window’ 프레임으로 그 원인을 분석하고자 합니다.
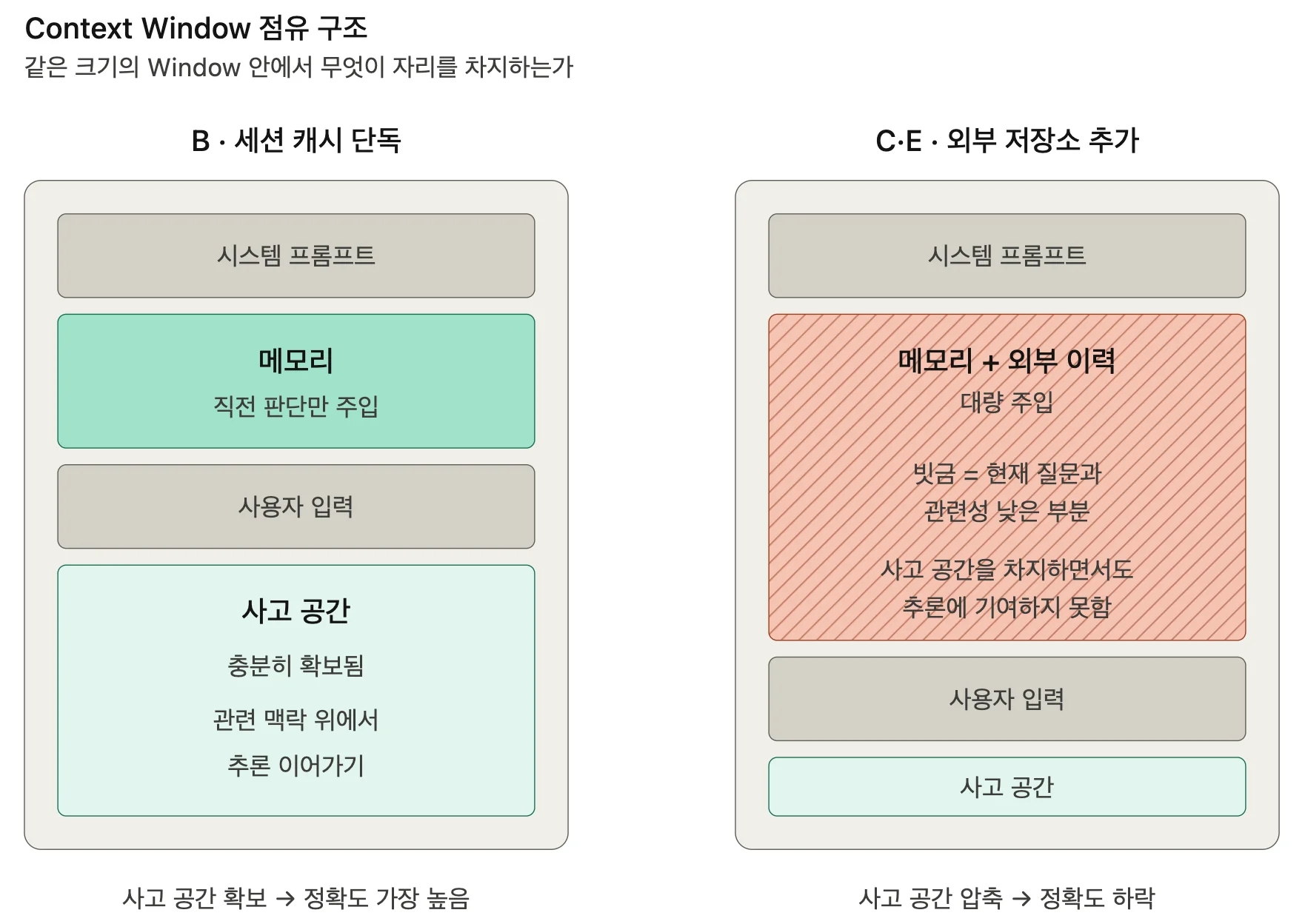
LLM의 Context Window는 하나의 추론 호출에서 처리할 수 있는 토큰의 총량입니다. 시스템 프롬프트, 메모리, 사용자 입력, 모델이 응답을 생성하기 위해 확보해야 하는 토큰 여유분(이하 '사고 공간')이 모두 이 안에서 경쟁합니다. Window에 주입되는 정보가 많아질수록 모델이 처리해야 할 정보 범위가 커지면서 중요한 부분에 집중도가 떨어지고, 추론 품질도 낮아집니다.
이것이 이번 실험 결과의 원인입니다. 외부 저장소 시나리오(C, E)는 Window에 과거 이력을 대량으로 밀어 넣어 사고 공간을 줄였습니다. 반면 세션 캐시 단독 시나리오(B)는 직전 대화의 판단 내용만 주입해 사고 공간을 크게 줄이지 않았습니다. 더 중요한 점은 주입되는 정보가 현재 질문과 직접 연결되는 맥락이라는 것입니다. 에이전트가 방금 처리한 판단을 다시 참조해 모델은 추론을 처음부터 재구성하지 않고 이미 도달한 결론 위에서 이어갈 수 있습니다.
외부 저장소가 가져오는 과거 이력은 벡터 유사도나 키 매칭으로 검색됩니다. 그러나 현재 질문과 관련성이 매번 보장되지 않아 사고 공간을 차지하면서도 추론에 기여하지 못할 때가 있습니다. 정리하면, B는 적절한 양의 관련 정보를 주입했기에 정확도가 가장 높았습니다. "많이 넣으면 무조건 좋다"는 가정이 성립하지 않는 이유입니다.
관련 연구에서도 유사한 현상이 보고됩니다. 컨텍스트 길이가 늘어날수록 LLM 성능이 비균일하게 저하되는 ‘Context Rot’(Chroma, 2025), 입력 중간부 정보의 활용도가 떨어지는 ‘Lost in the Middle’ 위치 편향(Liu et al., TACL 2024)이 대표적입니다. 이번 실험에서 관찰된 외부 저장소 시나리오의 정확도 하락도 동일한 메커니즘의 연장선에 있을 가능성이 있습니다.
맺음말
이 글은 ‘에이전트가 매 세션에서 같은 추론을 반복하면서 토큰과 시간을 중복으로 소모한다’는 문제의식에서 출발했습니다. 이를 해소하기 위해 세션 캐시(claude-mem)와 외부 저장소(Vault KV·Milvus·Mem0)를 다양하게 조합한 다섯 시나리오에 호출을 던져 메모리 계층 구성이 토큰 사용량·응답 시간·정확도에 어떤 영향을 주는지 확인했습니다.
결과는 처음의 기대와 달랐습니다. 파일럿 실험에서 확인된 토큰·응답 시간 절감 효과는 확장 실험에서 재현되지 않았고, 외부 저장소를 추가한 구성(C, E)은 베이스라인(A)보다 토큰을 더 썼습니다. 호출이 누적될수록 이전 대화 맥락이 컨텍스트로 더 많이 주입되는 구조 때문이었습니다. 비용 절감을 목적으로 메모리 계층을 도입하려 한다면, 이번 실험은 그 근거가 되지 못합니다.
대신 다른 발견이 있었습니다. 세션 캐시만 단독으로 추가한 구성(B)은 정확도를 78.2% 끌어올렸습니다. 외부 저장소를 더한 C와 E는 그 향상 폭에 미치지 못했고, 특히 E는 베이스라인(A)보다 정확도가 낮았습니다. 결과 분석에서 살펴봤듯, 외부 저장소가 끌어온 과거 이력이 사고 공간을 차지하면서도 현재 질문과 관련성을 매번 보장하지 못한 결과로 풀이됩니다. 메모리 계층의 가치는 '많이 넣을수록'이 아니라 '관련성 있는 정보를 적절한 양만큼 넣을수록' 올라간다는 것이 이번 실험의 핵심 관찰입니다.
그러나 이 결과를 그대로 일반화하기에는 한계가 분명합니다. 정확도를 ‘키워드 재현율’로 측정한 만큼 B의 정확도 향상이 모델의 실질적 이해 개선인지 아니면 캐시에 누적된 이전 응답이 다음 프롬프트에 재주입되며 일어난 키워드 재노출 효과인지는 이번 실험만으로 결론을 내리기가 어렵습니다. 또한 ‘단일 에이전트 호출 반복’이라는 단순 구조로 진행했기에 여러 에이전트가 공유 메모리를 사용하는 환경에서 같은 패턴이 나타날지는 확인하지 못했습니다. 이 두 물음은 다음 실험의 출발점으로 남겨둡니다.
참고 자료
- "How Claude remembers your project", Anthropic, https://code.claude.com/docs/en/memory
- "Hooks reference", Anthropic, https://code.claude.com/docs/en/hooks
- "Orchestrate teams of Claude Code sessions", Anthropic, https://code.claude.com/docs/en/agent-teams
- claude-mem GitHub 리포지터리, https://github.com/thedotmack/claude-mem
- "Hook Lifecycle", Claude-Mem Docs, https://docs.claude-mem.ai/architecture/hooks
- "Search Architecture", Claude-Mem Docs, https://docs.claude-mem.ai/architecture/search-architecture
- "Database Architecture", Claude-Mem Docs, https://docs.claude-mem.ai/architecture/database
- "KV Secrets Engine", HashiCorp Vault Docs, https://developer.hashicorp.com/vault/docs/secrets/kv
- "Milvus Architecture Overview", Milvus Documentation, https://milvus.io/docs/architecture_overview.md
- "Run Milvus with Docker Compose (Linux)", Milvus Documentation, https://milvus.io/docs/install_standalone-docker-compose.md
- mem0 GitHub 리포지터리, https://github.com/mem0ai/mem0
- "Qdrant", mem0 Documentation, https://docs.mem0.ai/components/vectordbs/dbs/qdrant
- Taranjeet Singh, "How to make your clients more context-aware with OpenMemory MCP", Mem0 Blog, 2025-05-13, https://mem0.ai/blog/how-to-make-your-clients-more-context-aware-with-openmemory-mcp
- Qdrant Documentation, https://qdrant.tech/documentation/
- "SQLite FTS5 Extension", SQLite Documentation, https://www.sqlite.org/fts5.html
- Nelson F. Liu·Kevin Lin·John Hewitt·Ashwin Paranjape·Michele Bevilacqua·Fabio Petroni·Percy Liang, "Lost in the Middle: How Language Models Use Long Contexts", arXiv, 2023, https://arxiv.org/abs/2307.03172
- Yue Yu·Wei Ping·Zihan Liu·Boxin Wang·Jiaxuan You·Chao Zhang·Mohammad Shoeybi·Bryan Catanzaro, "RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs", arXiv, 2024, https://arxiv.org/abs/2407.0248
- Kelly Hong·Anton Troynikov·Jeff Huber, "Context Rot: How Increasing Input Tokens Impacts LLM Performance", Chroma Research, 2025-07-14, https://research.trychroma.com/context-rot
- "Welch's t-test", Wikipedia, https://en.wikipedia.org/wiki/Welch%27s_t-test
- Patrick Lewis·Ethan Perez·Aleksandra Piktus·Fabio Petroni·Vladimir Karpukhin·Naman Goyal·Heinrich Küttler·Mike Lewis·Wen-tau Yih·Tim Rocktäschel·Sebastian Riedel·Douwe Kiela, "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks", arXiv, 2021, https://arxiv.org/abs/2005.11401
- "Using profiles with Compose", Docker Documentation, https://docs.docker.com/compose/how-tos/profiles/
우리 회사에 딱 맞는 DevSecOps 관행과 프레임워크를 찾고 계시나요? DevOps 전문가, 인포그랩과 하세요!
관련 태그

Daven
DevOps Engineer
InfoGrab에서 DevOps(FDE) 엔지니어로 재직중이며, DevOps 전환(프로세스·도구·운영체계 개선)을 메인 업무로 수행하고 있으며, 가장 큰 강점으로 삼고 있습니다. GitLab 인스턴스 운영과 CI/CD 파이프라인 개선, 고객사 이슈 대응을 주로 담당하고, Runner·Upgrade·권한/관리자 작업 등 GitLab 운영 전반을 다룹니다. 또한 n8n·MCP 기반 자동화를 활용해 반복 업무를 줄이고, 문서·워크플로·운영 표준을 재사용 가능한 형태로 정리해 팀 생산성을 높이는 데 관심이 많습니다.
이 저자의 글 모두 보기 →이 글이 도움이 되셨나요?
인포그랩 전문가가 맞춤 상담을 도와드립니다.
관련 글

비엔지니어의 Claude Code 활용 ROI 측정 - 4가지 베이스라인 지표
이 글은 AI 코딩 도구의 ROI를 측정하는 4가지 핵심 지표를 응용해 비엔지니어의 Claude Code 활용 ROI 베이스라인을 측정하는 방법을 다뤘습니다. 오픈 소스 CLI 도구인 ccusage와 Claude Code 자체 기능을 각각 활용해 사용자별 토큰 소비량, 세션·요청당 비용, 작업 유형별 도구 호출 분포, 세션당 메시지 수 베이스라인을 측정했습니다.

Claude Code Routines로 DevOps PR 리뷰·의존성 점검 자동화하기
Routines는 Claude Code가 정해진 시점이나 이벤트에 따라 Anthropic 클라우드에서 자동으로 작업을 시작하고 결과를 전달하는 기능입니다. 추론이 필요한 반복 작업을 사람 개입 없이 자동으로 처리합니다. 이 글은 Routines의 개념과 동작 방식, n8n과 차이점을 다뤘습니다. 또 DevOps 워크플로용 3가지 실습으로 Routines의 실무 활용법과 운영 시 유의 사항을 살펴봤습니다.

Claude Code Checkpoints로 잘못된 작업 되돌리기
Claude Code의 Checkpoints 기능은 사용자가 프롬프트를 입력할 때마다 관련 작업이 시작되기 전의 파일 상태와 그때까지 대화 내용을 기록으로 남깁니다. 이 기록을 바탕으로 이전 시점의 작업 상태를 복원할 수 있습니다. 이 글은 Checkpoints의 동작 방식, 사용법 실습, 효과적인 Checkpoints 활용법을 다뤘습니다.