Vector + VRL로 완성하는 클라우드 네이티브 Observability 실전 가이드

안녕하세요. 인포그랩에서 DevOps 엔지니어로 일하는 Chris입니다. 요즘 Observability 분야에서는 단순 로그 수집을 넘어 실시간 데이터 변환, 멀티 플랫폼 라우팅, 비용 최적화가 화두로 떠오르고 있습니다.
클라우드 네이티브 환경에서 DevOps 엔지니어는 급증하는 로그와 메트릭 데이터를 효율적으로 처리해야 하는데요. 특히 Kubernetes 환경에서 수십 개의 마이크로서비스가 생성하는 대용량 로그와 메트릭 데이터를 Loki, Elasticsearch, Prometheus 등 오픈 소스 백엔드로 효율적으로 전송할 수 있어야 합니다.
기존에 많이 사용하는 Logstash나 Fluentd만으로는 이러한 요구사항을 충족하기 어렵습니다. 높은 메모리/CPU 사용량과 클라우드 네이티브 환경에서 성능 한계 때문입니다.
그러나 Vector를 사용하면 다릅니다. Vector는 Observability 데이터 파이프라인 도구인데요. 이는 Fluentd보다 성능이 우수하며, 메모리 효율성이 좋습니다. 따라서 성능 병목과 복잡한 데이터 변환 요구사항을 효과적으로 처리할 수 있고요. 방대한 로그와 메트릭 데이터도 효율적으로 관리할 수 있습니다.
이 글에서는 Vector의 개념과 특징, 사용 방법, Kubernetes 배포 방법을 실습 예제와 함께 살펴보겠습니다.
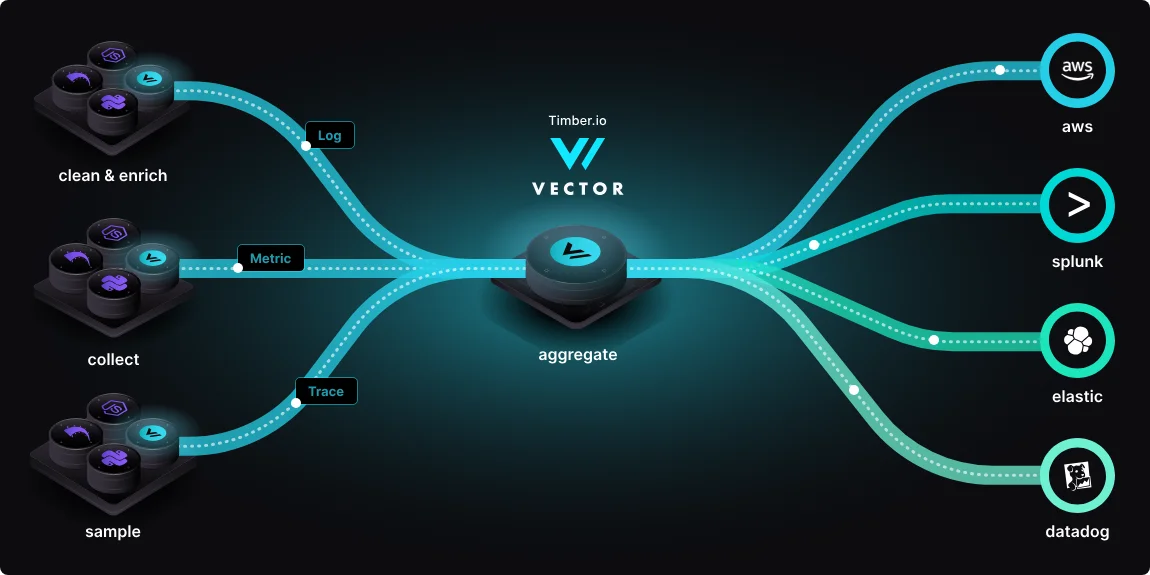
Vector란?
Vector는 Timber Technologies가 개발하고, 현재 Datadog에서 관리·유지보수하는 오픈 소스 Observability 데이터 파이프라인 도구입니다. 이 도구는 로그, 메트릭, 트레이스를 수집·변환·라우팅하는 통합 플랫폼이죠. Rust로 작성돼 메모리 안전성과 성능이 높은 게 특징이고요. 특히 Logstash나 Fluentd와 달리 단일 바이너리로 Agent와 Aggregator 역할을 모두 수행해 인프라 복잡성을 줄입니다.
아키텍처
Vector는 Sources → Transforms → Sinks의 3단계 파이프라인 구조로 동작합니다.
- 핵심 구성요소
- Sources(소스): 100개 이상의 데이터 입력 소스 지원(Kubernetes, Docker, Files, Metrics, Network 등)
- Transforms(변환): VRL(Vector Remap Language) 기반의 강력한 데이터 변환, 필터링, 집계, 라우팅
- Sinks(싱크): Loki, Prometheus, Elasticsearch, Kafka, S3 등 100개 이상의 출력 대상 지원
Vector의 Aggregator 모드를 활용하면 여러 Kubernetes 클러스터의 로그를 중앙에서 통합 처리할 수 있습니다. 이는 대규모 환경에서 운영 효율성을 크게 향상합니다.
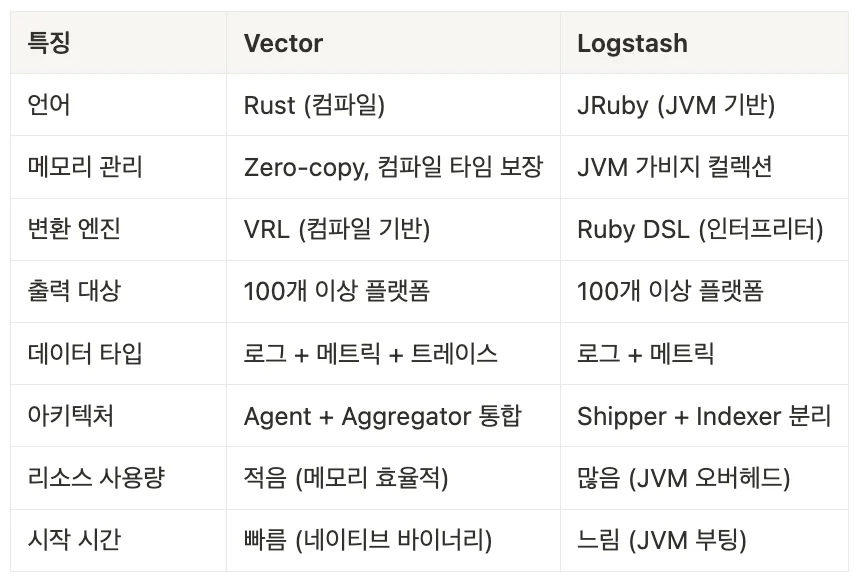
Vector vs Logstash 비교
Vector의 특징은 Logstash와 비교할 때 명확히 확인할 수 있습니다.
-
Vector vs Logstash 성능 벤치마크 (처리량 기준)
Vector는 다양한 처리 유형에서 Logstash보다 높은 속도를 보입니다.

VRL: Vector의 차별화 요소
Vector의 강력한 차별화 요소는 바로 VRL(Vector Remap Language)입니다. 이는 데이터 변환과 라우팅에 특화된 전용 언어인데요. Vector를 효과적으로 사용하려면 VRL을 익혀야 합니다.
VRL의 문법은 직관적이라 학습 부담이 크지 않습니다. 예를 들어, 간단한 필드 변환이나 라우팅 로직을 몇 줄의 코드로 구현할 수 있죠.
VRL 학습 투자는 Vector의 높은 성능과 리소스 효율성으로 충분히 보상받을 수 있습니다. 특히 클라우드 네이티브 환경에서는 ‘통합 데이터 관리’와 ‘멀티 백엔드 지원’이라는 Vector의 강력한 이점을 최대한 누릴 수 있습니다.
-
타입 안전성
VRL의 가장 큰 특징은 ‘컴파일 타임 타입 체크’입니다. 다음 예제에서 보듯 VRL은 명시적인 런타임 타입 변환과 검사로 데이터 처리 시 발생 가능한 오류를 미리 파악하고, 런타임 크래시를 방지해 안정적인 데이터 처리를 지원합니다.
yaml# 컴파일 타임 타입 체크로 런타임 에러 방지 .status_code = to_int!(.status) # 명시적 타입 변환, 변환에 실패하면 이벤트가 드롭되고 에러 로그가 기록됩니다. 컴파일 타임에 타입이 보장되어 런타임 크래시가 발생하지 않습니다. # JSON 파싱과 에러 처리 parsed, err = parse_json(.message) if err != null { .parse_error = err # 에러가 발생해도 프로그램이 중단되지 않고 처리를 계속합니다 .original_message = .message } else { . = merge!(., parsed) # JSON 파싱에 성공하면 원본 이벤트와 파싱된 데이터를 병합합니다 } -
VRL vs Logstash Ruby DSL 비교
VRL과 Logstash Ruby DSL에는 다음 차이점이 있습니다.
- 타입 안전성: VRL은 컴파일 타임 에러 체크, Logstash는 런타임 에러 가능성 있음
- 표현력: VRL이 더 간결하고 직관적인 문법 제공
- 성능: 네이티브 컴파일 vs JVM 인터프리터로 압도적인 성능 차이 보임
- 에러 처리: VRL은 명시적 에러 처리 지원, Logstash는 태그 기반 복잡한 처리 사용
- 디버깅: VRL은 명확한 에러 메시지 제공, Logstash는 디버깅이 어려움
-
VRL vs Logstash Ruby DSL 예제
같은 로직을 VRL과 Logstash Ruby DSL로 각각 구현한 예제를 살펴보겠습니다.
-
VRL 구현:
yaml# 더 간결하고 타입 안전한 처리 parsed, err = parse_json(.message) if err != null { .parse_error = err .original_message = .message } else { . = merge!(., parsed) } if exists(.level) { .level = to_string!(.level) .level = downcase(.level) } else { .level = "info" } # 복잡한 조건도 간단하게 표현 if .level == "debug" { abort # 이벤트 드롭 } -
Logstash Ruby DSL 구현:
rubyfilter { json { source => "message" } mutate { lowercase => [ "level" ] } if [level] == "debug" { drop { } } # 에러 처리가 복잡함 if "_jsonparsefailure" in [tags] { mutate { add_field => { "parse_error" => "JSON parsing failed" } } } }
-
Vector 활용 실습
이제 Vector를 실제 환경에서 사용하기 위해 이를 설치하고 설정하는 방법을 알아보겠습니다.
사전 요구사항
Vector는 Linux, macOS, Windows를 지원합니다. Kubernetes 환경에서는 Helm Chart로 손쉽게 배포할 수 있습니다.
설치
OS별로 다음 명령어를 사용해 Vector를 설치합니다.
-
macOS/Linux
shell# 스크립트 설치 (권장) $ curl --proto '=https' --tlsv1.2 -sSfL https://sh.vector.dev | bash # macOS - Homebrew $ brew tap vectordotdev/brew && brew install vector # Ubuntu/Debian $ bash -c "$(curl -L https://setup.vector.dev)" $ sudo apt-get install vector -
Windows
powershell# Chocolatey PS> choco install vector # 또는 직접 다운로드 PS> Invoke-WebRequest -Uri "https://github.com/vectordotdev/vector/releases/latest/download/vector-x86_64-pc-windows-msvc.zip" -OutFile vector.zip
VRL 변환, Loki 전송
지금부터 간단한 데모 로그를 생성하고, VRL 변환을 거쳐 Loki로 전송하는 과정을 실습하겠습니다. 이 실습은 실제 Apache 로그와 유사한 데이터로 Vector의 핵심 기능인 수집(Sources) → 변환(Transforms) → 전송(Sinks) 파이프라인을 직접 구현하며, VRL의 강력한 데이터 처리 능력을 체험하는 데 의미가 있습니다.
-
Vector가 설치된 상태에서 터미널을 열고, 아래 명령어로 Vector 버전을 확인합니다.
shell$ vector --version
-
간단한 설정 파일을 만들어 테스트를 진행합니다. 먼저 데모용 Volume으로 사용할 디렉터리를 생성합니다.
bash$ mkdir -p vector-test/vector-vl $ cd vector-test -
vector-test 디렉터리에 진입한 다음,
demo-vector.yaml파일을 생성합니다.yaml# demo-vector.yaml data_dir: "vector-vl" # ⚠️ 데모용: 프로덕션에서는 Persistent Volume 필수 sources: demo_logs: type: demo_logs format: json interval: 1.0 count: 5 transforms: parse_and_enrich: type: remap inputs: ["demo_logs"] source: | # JSON 메시지 파싱 parsed = parse_json!(.message) # HTTP 상태 코드 기반 로그 레벨 설정 status_code = to_int!(parsed.status) if status_code >= 500 { .level = "error" } else if status_code >= 400 { .level = "warn" } else { .level = "info" } # 파싱된 필드들 추가 .http_status = status_code .http_method = parsed.method .request_path = parsed.request .user_id = parsed."user-identifier" # 타임스탬프 추가 .timestamp = now() # 에러 감지 if .level == "error" { .alert_required = true .severity = "high" } else { .alert_required = false .severity = "low" } sinks: console_output: type: console inputs: ["parse_and_enrich"] encoding: codec: json -
설정 파일이 올바른지 검증합니다.
shell$ vector validate demo-vector.yaml # 실행 예상 결과 √ Loaded ["demo-vector.yaml"] √ Component configuration √ Health check "console_output" ------------------------------- Validated -
Vector를 실행해 데모 로그를 확인합니다.
shell$ vector --config demo-vector.yaml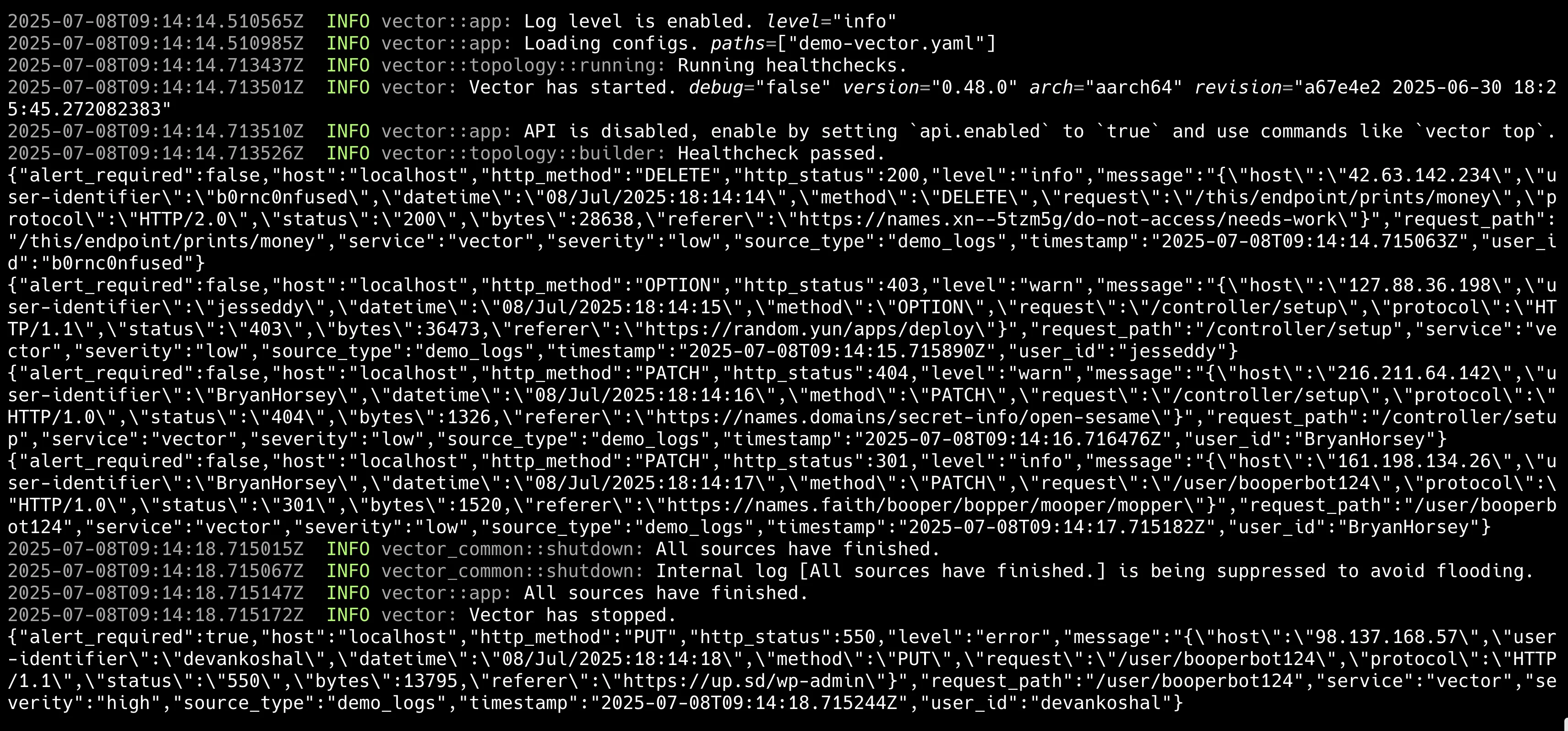
데모 실행 화면의 동작 과정은 다음과 같습니다.
demo_logs타입의 입력 소스가 1초마다 가짜 Apache 로그를 5개 생성합니다.parse_and_enrich으로 선언한 vector transforms이 동작합니다.- JSON Message 파싱
- HTTP Status Code별 레벨 부여
- 파싱된 필드 추가
- 파싱된 .level 필드에 따라 에러 알람 여부 마킹
console_output으로 JSON 형태 직렬화를 거쳐 출력됩니다.
프로덕션 환경 에러 처리
실무에서는 "변환에 실패하면 무슨 일이 일어나는가?"가 가장 중요한 고려사항입니다. VRL에서 ! 연산자를 사용하면 변환 실패 시 이벤트가 자동으로 드롭되는데요. 이는 데이터 손실로 이어질 수 있습니다.
이러한 문제를 방지하기 위해 프로덕션 환경에서 에러를 처리하는 방법을 실습하려 합니다. 실습 예제로 에러 처리 Dead Letter Queue 구성을 활용하겠습니다.
-
실제 프로덕션 환경의 로그와 동일한 형태의 로그 스트림을
/tmp/vector-test-logs.txt에 저장합니다.plain{"level": "info", "message": "Normal JSON log", "timestamp": "2025-07-08T10:30:00Z"} Plain text log without JSON structure - this should work fine {"level": "error", "message": "Database connection failed", "status": 500} { "broken": "json without closing brace ERROR: Critical system failure in module XYZ {"level": "warn", "status": "NOT_A_NUMBER", "message": "Invalid status code"} This is just a plain text message {"valid": "json", "with": {"nested": "structure"}, "status": 200} <corrupted log entry with special chars: ñáéíóú> {"level": "debug", "message": "Debug info", "extra_field": null} -
dlq-demo-random.yaml파일로 구성 파일을 생성합니다.yaml# dlq-demo-random.yaml data_dir: "vector-vl" # ⚠️ 데모용: 프로덕션에서는 Persistent Volume 필수 sources: # 정상적인 JSON 로그 demo_logs: type: demo_logs format: json interval: 1.0 count: 20 # 파일에서 다양한 형태의 로그 읽기 mixed_logs: type: file include: ["/tmp/vector-test-logs.txt"] read_from: "beginning" transforms: # 랜덤 로그 생성기 (타입 안전) generate_random_logs: type: remap inputs: ["demo_logs"] source: | # 원본 demo_logs 처리 parsed = parse_json!(.message) .original_log = .message .log_type = "demo" .route_target = "normal" . = merge!(., parsed) # HTTP 상태 처리 .http_status = to_int!(parsed.status) if .http_status >= 500 { .level = "error" } else if .http_status >= 400 { .level = "warn" } else { .level = "info" } # 랜덤하게 일부 로그를 손상시키기 random_val = random_int(1, 10) if random_val == 1 { # JSON 구조 파괴 .message = "{ invalid json structure without closing brace" .log_type = "corrupted_json" } else if random_val == 2 { # 상태 코드를 문자열로 변경 (타입 안전하게) message_str = to_string!(.message) parsed_copy = parse_json!(message_str) parsed_copy.status = "INVALID_STATUS" .message = encode_json(parsed_copy) .log_type = "invalid_status" } else if random_val == 3 { # 완전히 다른 형태의 로그 .message = "Plain text log message without JSON structure at " + to_string(now()) .log_type = "plain_text" } # 파일 로그 처리 (타입 안전) create_problematic_logs: type: remap inputs: ["mixed_logs"] source: | .original_message = .message .log_type = "external" .timestamp = now() # 메시지를 문자열로 안전하게 변환 message_str = to_string(.message) ?? "" # 안전한 문자열 검사 if contains(message_str, "ERROR") { .level = "error" .route_target = "normal" } else if contains(message_str, "{") { # JSON처럼 보이는 경우 .route_target = "normal" } else { # 일반 텍스트는 정상 처리하되 특별 표시 .level = "info" .route_target = "normal" .is_plain_text = true } # 통합 파싱 로직 (타입 안전) safe_parsing: type: remap inputs: ["generate_random_logs", "create_problematic_logs"] source: | # 이미 route_target이 설정된 경우 그대로 사용 if !exists(.route_target) { .route_target = "normal" } # 메시지를 안전하게 문자열로 변환 message_str = to_string(.message) ?? "" # JSON 파싱 시도 if contains(message_str, "{") { parsed, parse_err = parse_json(message_str) if parse_err != null { # 파싱 실패 시 DLQ로 라우팅 .route_target = "dlq" .parse_error = to_string(parse_err) .error_type = "json_parse_failure" .failure_reason = "Cannot parse JSON: " + to_string(parse_err) } else if !is_object(parsed) { # 파싱은 성공했지만 객체가 아닌 경우 .route_target = "dlq" .parse_error = "Parsed result is not an object" .error_type = "invalid_json_structure" .failure_reason = "JSON parsed but result is not an object" } else { # 정상 파싱된 경우 추가 검증 if exists(parsed.status) { status_result, status_err = to_int(parsed.status) if status_err != null { # 상태 코드 변환 실패 .route_target = "dlq" .parse_error = "Invalid status code: " + to_string!(parsed.status) .error_type = "status_code_invalid" .failure_reason = "Status code is not a valid integer" } else { # 모든 검증 통과 . = merge!(., parsed) .http_status = status_result .validation_passed = true } } else { # status 필드가 없는 경우도 처리 . = merge!(., parsed) .missing_status = true } } } else { # JSON이 아닌 로그는 그대로 처리 .is_plain_text = true .validation_passed = true } # 타임스탬프 설정 if !exists(.timestamp) { .timestamp = now() } route_by_target: type: route inputs: ["safe_parsing"] route: dlq_events: '.route_target == "dlq"' normal_events: '.route_target == "normal"' sinks: # 정상 로그 출력 normal_logs: type: console inputs: ["route_by_target.normal_events"] encoding: codec: json json: pretty: true # DLQ 파일 저장 dlq_storage: type: file inputs: ["route_by_target.dlq_events"] path: "/tmp/vector-dlq-%Y-%m-%d-%H.log" encoding: codec: json json: pretty: true -
설정 파일이 올바른지 검증합니다.
shell$ vector validate dlq-demo-random.yaml # 실행 예상 결과 Loaded with warnings ["dlq-demo-random.yaml"] --------------------------------------------- ~ Transform "route_by_target._unmatched" has no consumers √ Component configuration √ Health check "dlq_storage" √ Health check "dlq_monitor" √ Health check "normal_logs" --------------------------------------------------------- Validated -
Vector를 실행해 데모 로그를 확인합니다.
shell$ vector --config dlq-demo-random.yaml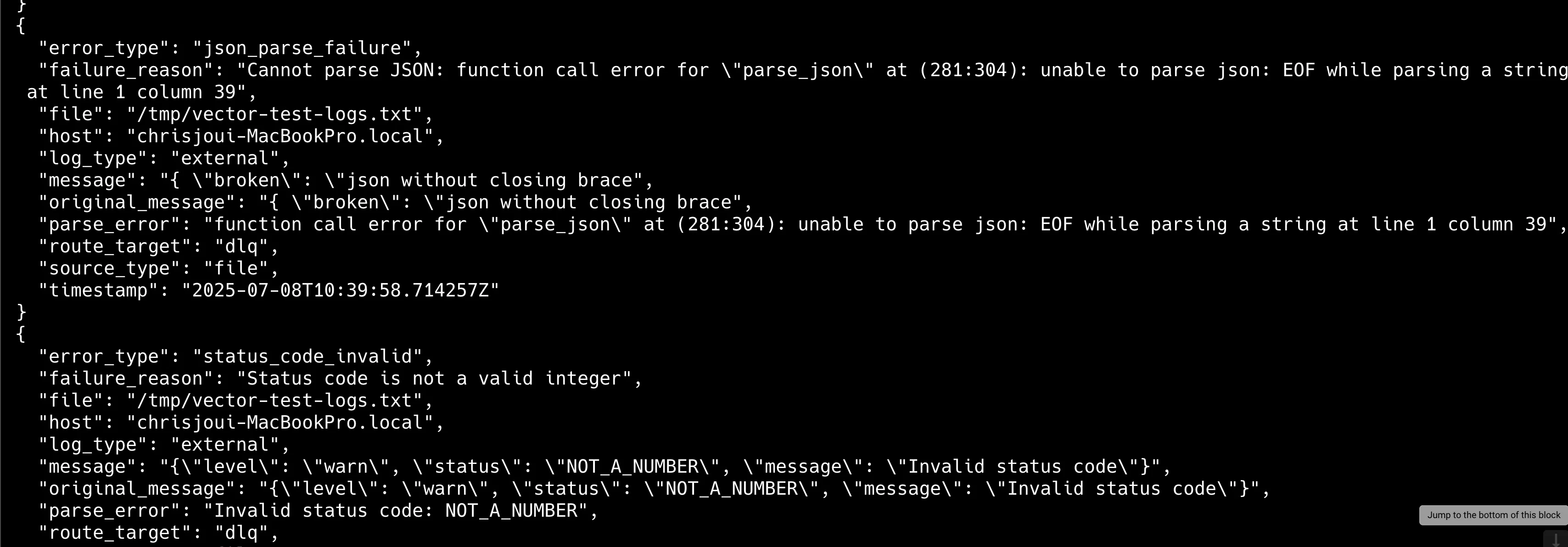
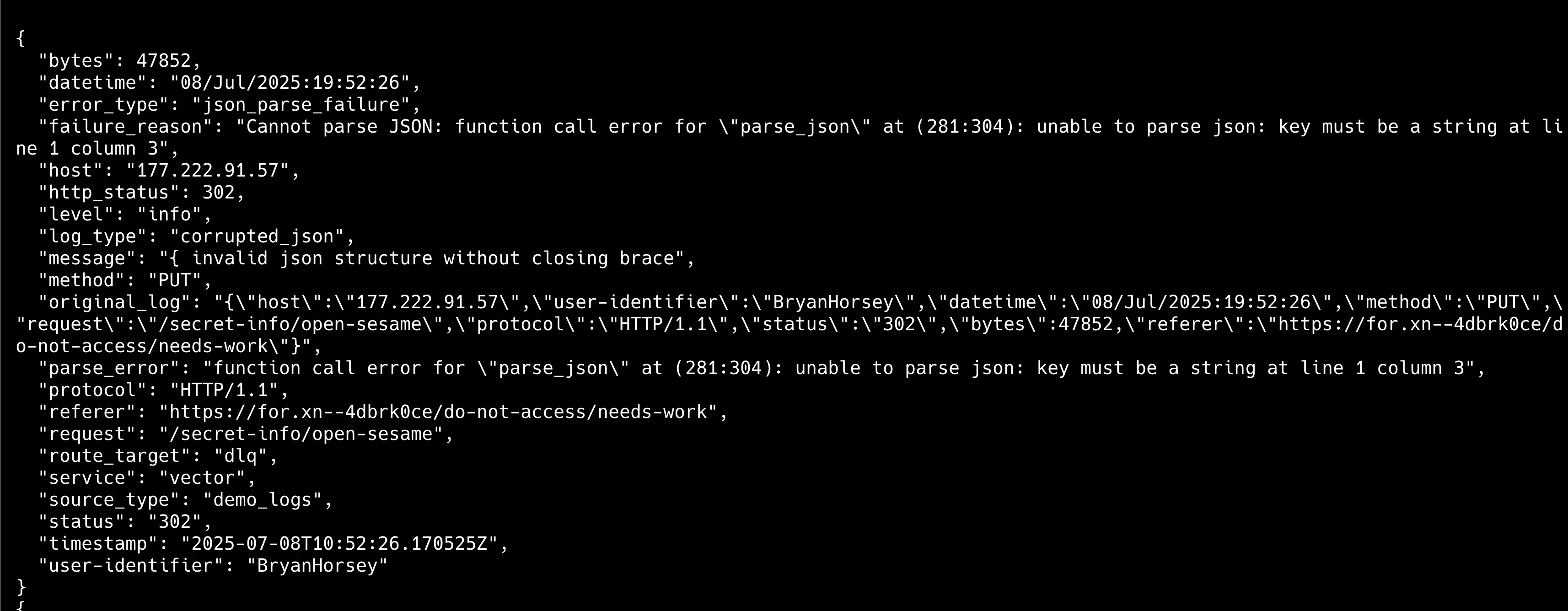
위와 같이 구성하면 파싱에 실패한 로그도 손실 없이 별도로 저장됩니다. 로그는 나중에 분석하고 복구할 수 있습니다. VRL의 핵심 장점은 ‘컴파일 타임에 모든 타입 에러를 찾아 프로덕션 환경에서 예상치 못한 데이터 손실을 방지한다’는 것입니다. 또한 Rust로 네이티브 컴파일돼 인터프리터 방식보다 훨씬 더 빠르게 실행할 수 있습니다.
Loki 연동
다음으로 Vector에서 Loki로 로그를 전송하는 방법을 실습하겠습니다. 이 실습은 Vector와 Loki의 연동 과정을 이해하고, 실제 환경에서 로그를 효율적으로 전송하는 방법을 익히는 데 목적이 있습니다.
-
Docker로 Loki를 실행합니다.
shell# Loki 컨테이너 실행 (테스트용) $ docker run -d --name loki -p 3100:3100 grafana/loki:2.9.0 -
loki-demo.yaml설정 파일을 생성합니다.yaml# loki-demo.yaml data_dir: "vector-vl" # ⚠️ 데모용: 프로덕션에서는 Persistent Volume 필수 sources: demo_logs: type: demo_logs format: json interval: 1.0 count: 5 transforms: loki_prepare: type: remap inputs: ["demo_logs"] source: | # JSON 메시지 파싱 parsed = parse_json!(.message) # HTTP 상태 코드 기반 로그 레벨 설정 status_code = to_int!(parsed.status) if status_code >= 500 { .level = "error" } else if status_code >= 400 { .level = "warn" } else { .level = "info" } # 서비스 정보 추출 .service = "demo-app" # Loki 라벨에 적합한 형태로 변환 .app_label = .service .level_label = .level # 추가 필드들 .http_status = status_code .http_method = parsed.method .request_path = parsed.request .user_id = parsed."user-identifier" sinks: loki_output: type: loki inputs: ["loki_prepare"] endpoint: "http://localhost:3100" # Loki 라벨 설정 labels: app: "{{ app_label }}" level: "{{ level_label }}" source: "vector-demo" # 로그 본문 설정 encoding: codec: json # 동시에 콘솔에도 출력 console_output: type: console inputs: ["loki_prepare"] encoding: codec: json -
Loki 연동 설정을 검증하고 실행합니다.
shell# 설정 검증 $ vector validate loki-demo.yaml # 실행 예상 결과 √ Loaded ["loki-demo.yaml"] √ Component configuration √ Health check "loki_output" √ Health check "console_output" ------------------------------- Validated # Vector 실행 $ vector --config loki-demo.yaml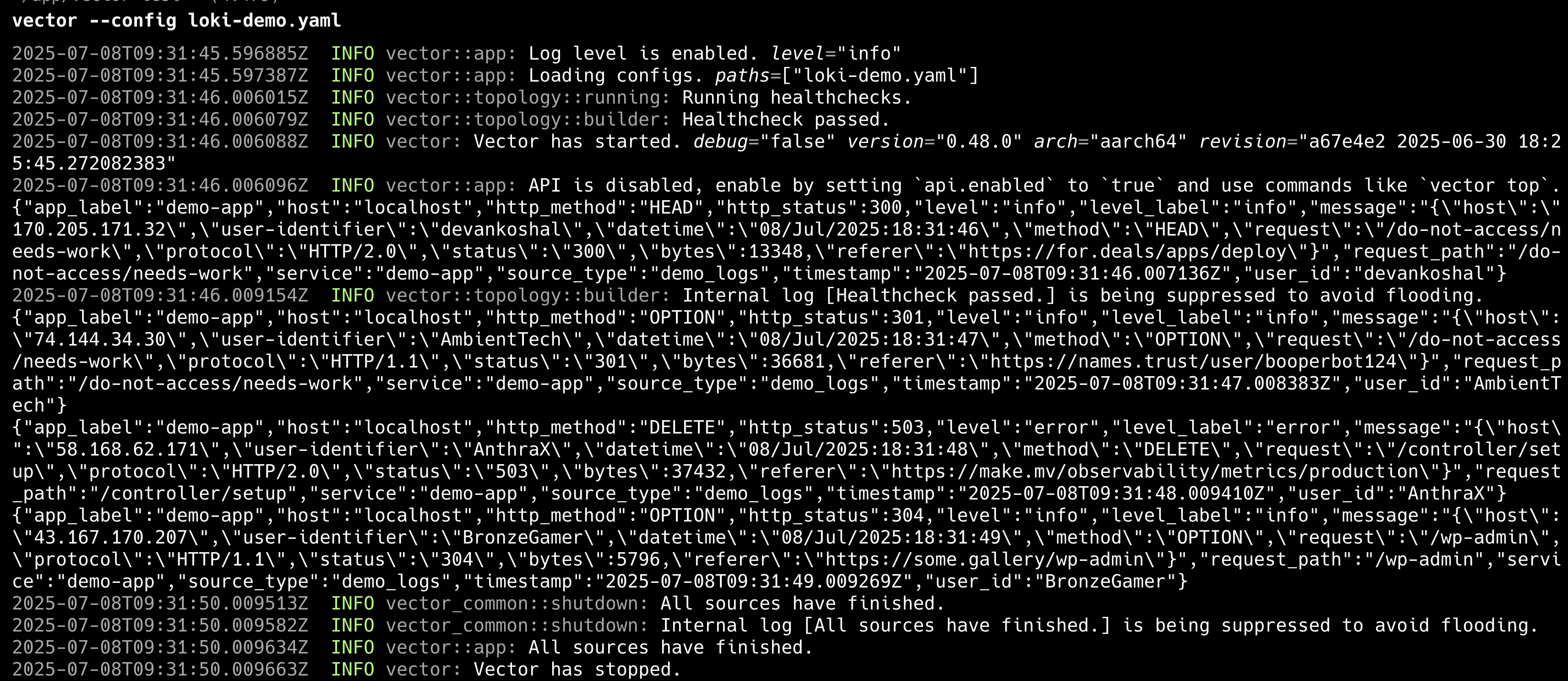
-
정상적으로 실행되면 콘솔에서 로그를 확인할 수 있으며, 이는 Loki로 전송됩니다. Loki에 전송된 로그를 확인합니다.
shell# Loki API를 통해 라벨 조회 $ curl -G -s "http://localhost:3100/loki/api/v1/labels" # 특정 라벨의 로그 조회 $ curl -G -s "http://localhost:3100/loki/api/v1/query_range" \ --data-urlencode 'query={app="demo-app"}' # jq 가 있다면 result 만 조회 $ curl -G -s "http://localhost:3100/loki/api/v1/query_range" \ --data-urlencode 'query={app="demo-app"}' | jq .data.result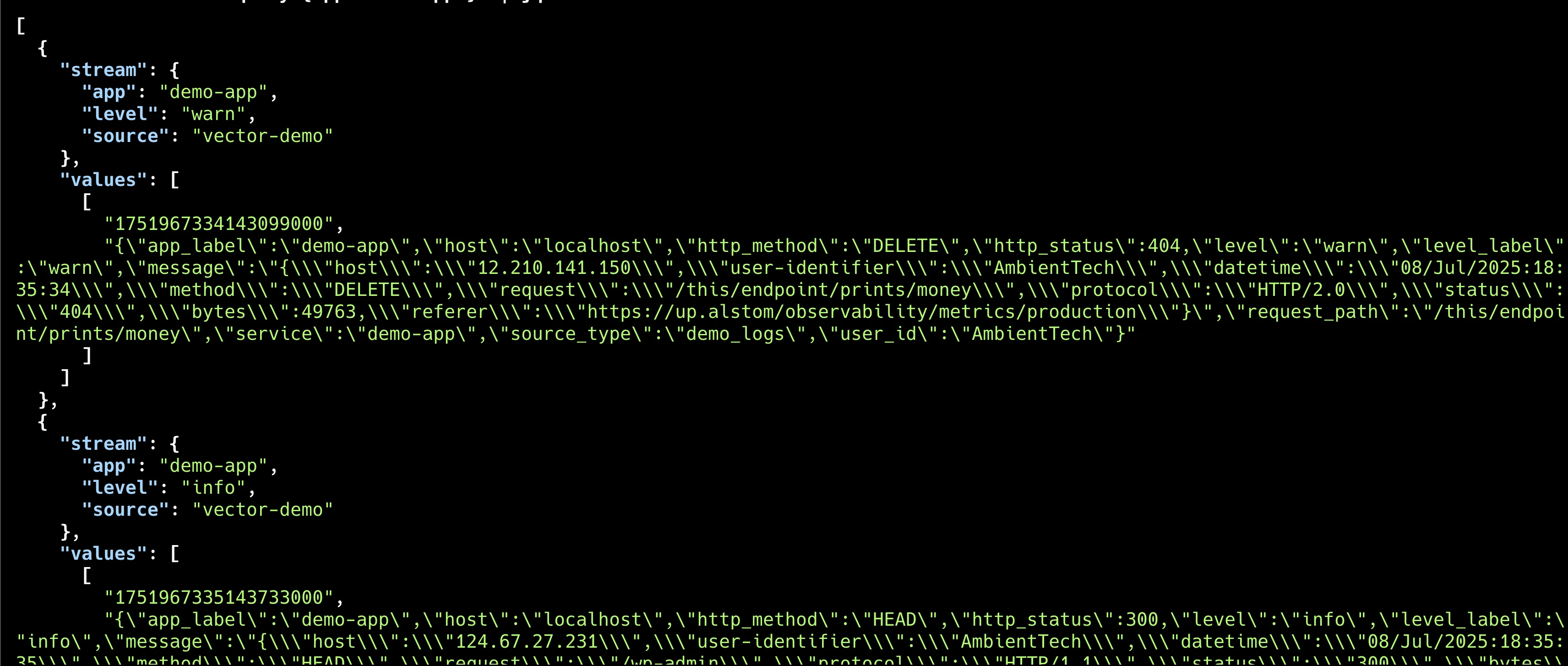
위 실습에서 보다시피 Vector의 데이터 변환 기능과 Loki의 라벨 시스템을 결합하면, 복잡한 로그 데이터를 효율적으로 구조화하고 저장할 수 있습니다. 이는 운영 환경에 필요한 로그 분류와 검색 최적화를 동시에 달성할 수 있어 실용적입니다.
Elasticsearch와 다양한 백엔드 통합
이어서 Vector가 Elasticsearch를 비롯해 다양한 백엔드와 통합되는 방식을 살펴보겠습니다. 이 과정은 각 백엔드에 최적화된 데이터 처리 방식으로 비용을 줄이고, 성능을 극대화하는 Observability 아키텍처를 구현하는 데 도움이 됩니다.
-
기본 Elasticsearch 연동 설정
기본적인 Elasticsearch 연동 설정 방식은 다음 예제를 참고하세요.
yaml# vector.yaml data_dir: "vector-vl" # ⚠️ 데모용: 프로덕션에서는 Persistent Volume 필수 sources: kubernetes_logs: type: kubernetes_logs auto_partial_merge: true self_node_name: "vector-node" transforms: elasticsearch_enhancement: type: remap inputs: ["kubernetes_logs"] source: | # JSON 로그 파싱 message_str = to_string(.message) ?? "" if contains(message_str, "{") { parsed, err = parse_json(message_str) if err == null && is_object(parsed) { . = merge!(., parsed) } } # 서비스 정보 추출 .service = .kubernetes.labels.app || "unknown" .namespace = .kubernetes.pod_namespace .hostname = get_hostname!() # 로그 레벨 정규화 level_str = to_string(.level) ?? "info" .level = downcase(level_str) # Elasticsearch 인덱스 패턴을 위한 날짜 필드 .@timestamp = now() .cluster = "production" # 에러 로그 특별 처리 if .level == "error" { .alert_required = true .error_hash = sha1(message_str) } sinks: elasticsearch_logs: type: elasticsearch inputs: ["elasticsearch_enhancement"] endpoints: ["http://elasticsearch:9200"] # Vector 0.48.0에서 bulk 설정으로 인덱스 지정 bulk: index: "logs-%Y.%m.%d" # Elasticsearch 최적화 compression: "gzip" batch: max_bytes: 10485760 # 10MB (Elasticsearch에 최적화) timeout_secs: 30 # 재시도 설정 request: retry_attempts: 5 retry_initial_backoff_secs: 2 -
고급 멀티 백엔드 설정(동시 전송)
고급 멀티 백엔드 설정 방식은 다음 예제를 참고하세요.
yamltransforms: route_by_severity: type: route inputs: ["elasticsearch_enhancement"] route: critical_logs: '.level == "error" || .level == "fatal"' metrics_data: '.type == "metric"' normal_logs: 'true' sinks: # 중요 로그는 Elasticsearch로 실시간 전송 elasticsearch_critical: type: elasticsearch inputs: ["route_by_severity.critical_logs"] endpoint: "http://elasticsearch:9200" index: "critical-logs-%Y.%m.%d" # 메트릭은 Prometheus로 prometheus_metrics: type: prometheus_exporter inputs: ["route_by_severity.metrics_data"] address: "0.0.0.0:9598" # 일반 로그는 Elasticsearch로 (배치 최적화) elasticsearch_normal: type: elasticsearch inputs: ["route_by_severity.normal_logs"] endpoint: "http://elasticsearch:9200" index: "logs-%Y.%m.%d" compression: "gzip" batch: max_bytes: 20971520 # 20MB timeout_secs: 60 # 대용량 배치 # 보조 스토리지: Loki (장기 보관용) loki_archive: type: loki inputs: ["route_by_severity.normal_logs"] endpoint: "http://loki:3100" compression: "gzip" labels: app: "{{ service }}" namespace: "{{ namespace }}" level: "{{ level }}" purpose: "archive" # 클라우드 백업: S3 s3_backup: type: aws_s3 inputs: ["elasticsearch_enhancement"] bucket: "log-backup-bucket" key_prefix: "logs/%Y/%m/%d/" compression: "gzip"
위와 같이 설정하면 중요한 에러 로그는 Elasticsearch로 실시간 전송돼 Kibana에서 즉시 확인할 수 있습니다. 반면에 일반 로그는 배치 처리로 묶어 전송해 네트워크와 리소스 효율성을 높일 수 있습니다. 또한 Loki를 중장기 로그 저장과 기본 로그 검색용으로 활용하고, S3는 장기 아카이빙과 데이터 백업용으로 활용하면 하이브리드 Observability 스택을 더 효과적으로 구성할 수 있습니다.
Kubernetes 배포 실습
마지막으로 실제 프로덕션 환경에서 Vector를 Kubernetes에 배포하는 방법을 실습하겠습니다. 이 과정은 지금까지 학습한 Vector의 기능을 Kubernetes 환경에 통합해 클라우드 네이티브 Observability 파이프라인을 완성하는 최종 단계입니다.
테스트 환경 구축(kind 사용)
먼저 테스트용 Kubernetes 클러스터를 kind로 구축하겠습니다. 이 실습을 진행하려면 Docker가 실행 중이어야 합니다.
kind 설치
다음 명령어를 실행해 kind를 설치합니다.
# macOS - Homebrew
$ brew install kind
# Linux (x86_64)
$ curl -Lo ./kind <https://kind.sigs.k8s.io/dl/v0.20.0/kind-linux-amd64>
$ chmod +x ./kind
$ sudo mv ./kind /usr/local/bin/kind
# Windows (PowerShell)
PS> curl.exe -Lo kind-windows-amd64.exe <https://kind.sigs.k8s.io/dl/v0.20.0/kind-windows-amd64>
PS> Move-Item .\\kind-windows-amd64.exe c:\\some-dir-in-your-PATH\\kind.exe
kind 클러스터 생성
다음 명령어를 실행해 kind 클러스터를 생성합니다.
# kind 클러스터 생성
$ kind create cluster --name vector-demo
# kubectl 컨텍스트 확인
$ kubectl cluster-info --context kind-vector-demo

클러스터 상태 확인
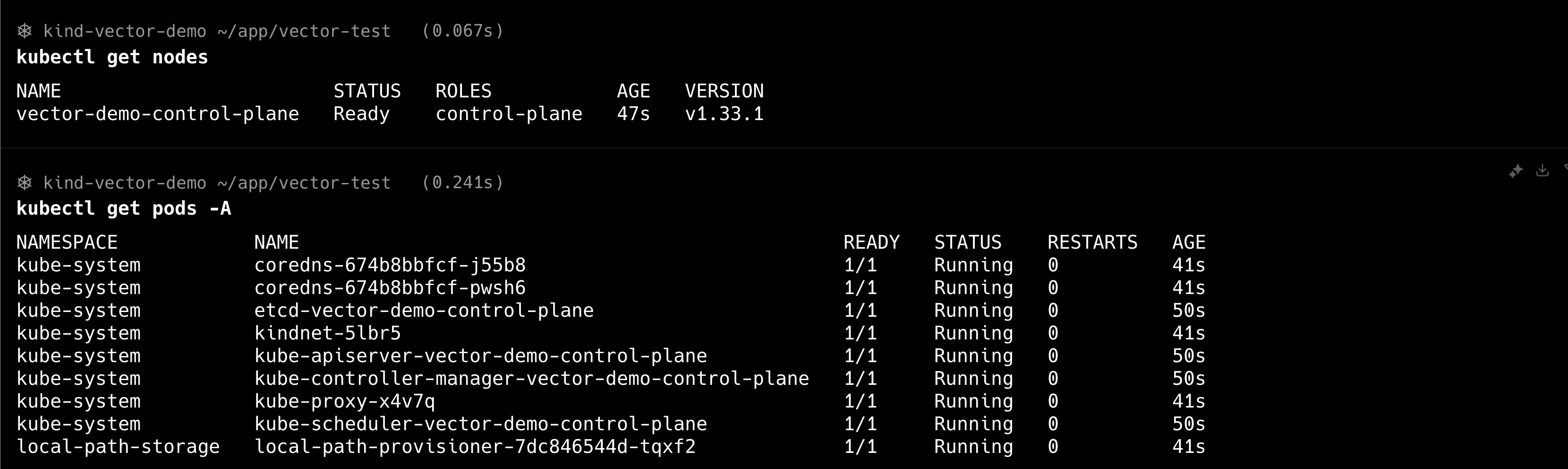
다음 명령어를 실행해 Kubernetes 클러스터 상태를 확인합니다.
# 노드 상태 확인
$ kubectl get nodes
# 시스템 Pod 상태 확인
$ kubectl get pods -A
Vector Helm 차트 배포
다음 명령어를 실행해 kind 클러스터에 Vector를 배포합니다.
# Helm 저장소 추가
$ helm repo add vector https://helm.vector.dev
$ helm repo update
# Vector 네임스페이스 생성
$ kubectl create namespace vector-system
# Vector 설치 (Loki 중심 설정)
$ helm install vector vector/vector \
--namespace vector-system \
--set role=Agent \
--set image.tag=nightly-2025-07-04-distroless-libc
Vector 배포 상태 확인
다음 명령어를 실행해 Vector 배포 상태를 확인합니다.
# Vector Pod 상태 확인
$ kubectl get pods -n vector-system
# Vector 로그 확인
$ kubectl logs -n vector-system -l app.kubernetes.io/name=vector
# Vector DaemonSet 상태 확인
$ kubectl get daemonset -n vector-system

테스트 로그 생성
다음 명령어를 실행해 테스트 Pod를 생성합니다. 이는 Vector의 로그 수집 여부를 확인하기 위함입니다.
# 테스트 애플리케이션 배포
$ kubectl create deployment test-app --image=nginx
$ kubectl scale deployment test-app --replicas=2
# 서비스 생성
$ kubectl expose deployment test-app --port=80 --target-port=80
# Pod 상태 확인
$ kubectl get pods -l app=test-app
Pod에서 다음 명령어를 실행해 테스트 로그를 생성합니다.
# 테스트 로그 생성
$ kubectl exec deployment/test-app -- sh -c '
# 정상 요청
curl -s localhost/ > /dev/null
curl -s localhost/index.html > /dev/null
curl -s localhost/health > /dev/null
# 404 에러 생성
curl -s localhost/nonexistent-page > /dev/null
curl -s localhost/missing.html > /dev/null
# 다양한 User-Agent로 요청
curl -s -H "User-Agent: Mozilla/5.0" localhost/ > /dev/null
curl -s -H "User-Agent: Bot/1.0" localhost/ > /dev/null
'
# Vector가 로그를 수집하는지 확인
$ kubectl logs -n vector-system -l app.kubernetes.io/name=vector --tail=20
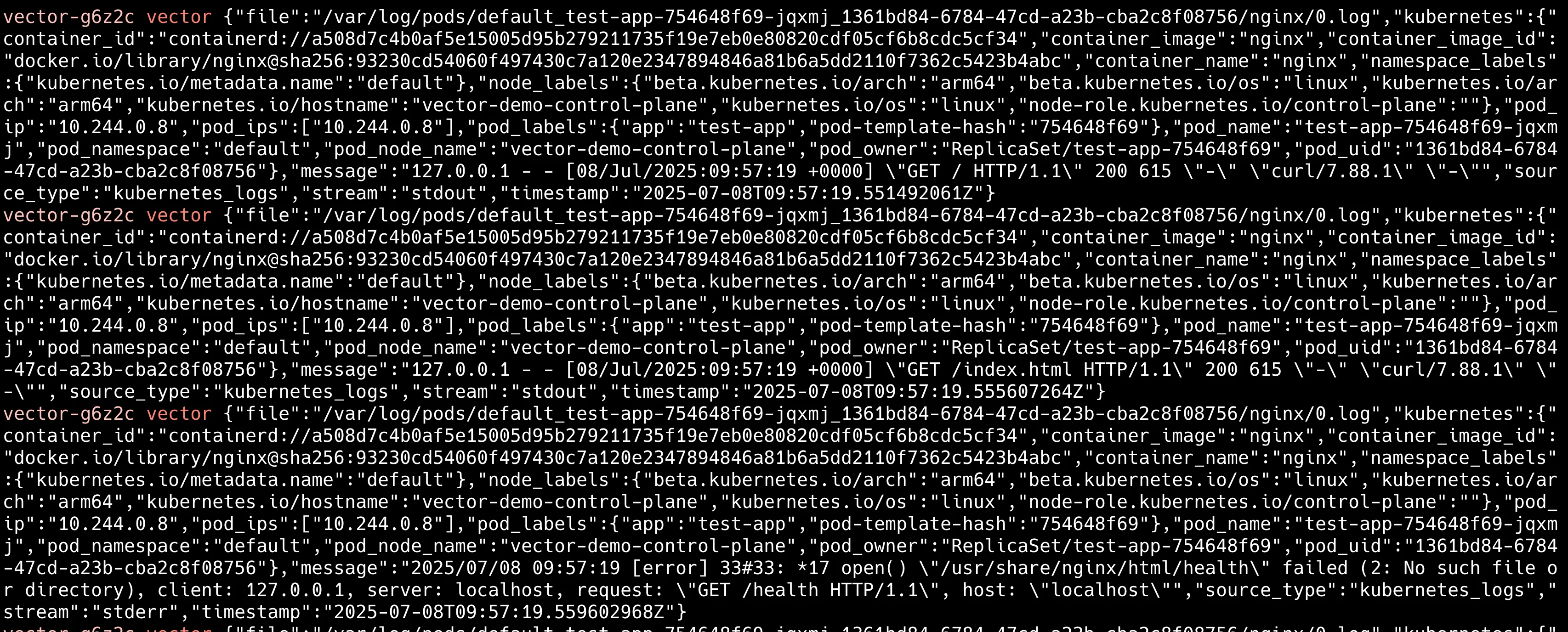
리소스 정리
실습이 완료됐습니다. 다음 명령어를 실행해 리소스를 정리합니다.
# 테스트 애플리케이션 삭제
$ kubectl delete deployment test-app
$ kubectl delete service test-app
# Vector 삭제
$ helm uninstall vector -n vector-system
$ kubectl delete namespace vector-system
# kind 클러스터 삭제
$ kind delete cluster --name vector-demo
지금까지 Vector의 핵심 기능을 실제 클라우드 네이티브 환경으로 확장하는 주요 과정을 실습했습니다. 이 과정을 반복 학습하면, VRL의 유연한 데이터 변환 능력과 Kubernetes의 강력한 오케스트레이션을 결합해 복잡한 프로덕션 환경의 로그 관리 요구사항에 효과적으로 대응할 수 있습니다.
맺음말
Vector는 기존 ELK 스택(Elasticsearch, Logstash, Kibana)의 성능 한계를 뛰어넘는 차세대 로그 파이프라인 솔루션입니다. 이는 Logstash보다 최대 24배 빠른 성능과 압도적인 메모리 효율성으로 인프라 비용을 크게 절감할 수 있습니다. 아울러 VRL의 타입 안전성으로 안정적인 운영도 보장합니다.
특히 하이브리드 멀티 백엔드 라우팅을 활용하면, 중요한 로그는 Elasticsearch로 실시간 분석하고, 일반 로그는 Loki로 장기 보관하며, 메트릭은 Prometheus로 모니터링하는 최적화된 Observability 스택을 구축할 수 있습니다. 기존 ELK 스택 사용자라면 Vector로 마이그레이션해 즉각적인 성능 향상과 비용 절감 효과를 경험할 수 있습니다.
여러분도 Vector와 함께 클라우드 네이티브 환경에 최적화된 방식으로 효율적인 Observability를 완성하시길 바랍니다.
참고 자료
- Vector 공식 기술 문서, https://vector.dev/docs/
- Vectordotdev GitHub, https://github.com/vectordotdev/vector#performance
- Grafana dashboards, https://grafana.com/grafana/dashboards/
- Docker 공식 기술 문서, https://docs.docker.com/
- VRL Playground, https://playground.vrl.dev/
지금 이 기술이 더 궁금하세요? 인포그랩의 DevOps 전문가가 드립니다.
관련 태그

이 글이 도움이 되셨나요?
인포그랩 전문가가 맞춤 상담을 도와드립니다.
관련 글

Grafana Alloy로 로그·메트릭 통합 수집하기
Grafana Alloy는 메트릭, 로그, 트레이스 등 주요 Observability 데이터를 통합 수집하는 범용 에이전트입니다. 최근 Grafana Loki를 위한 로그 수집 에이전트인 Promtail의 대체 도구로 주목받고 있습니다. 이 글은 Promtail의 한계와 Alloy의 개선 방식, Docker 환경에서 설치 방법, 로그·메트릭 수집 방법, 운영 시 유의 사항을 다뤘습니다.

DevOps 측면에서 Observability와 Monitoring 의미
이 글에서는 DevOps 측면에서 Observability와 Monitoring에 대해 알아보고, Observability가 필요한 이유에 대해 알아봅니다.

Signoz 소개
Observability 솔루션 Signoz 소개