AI 검색에 인용되는 기술 문서의 조건
 Grace
Grace
기술 문서의 독자가 바뀌었습니다. 이제 사람만 문서를 읽지 않고, AI 검색 엔진과 AI 코딩 어시스턴트도 기술 문서를 직접 소비하는데요. GitBook의 플랫폼 데이터 분석에 따르면, 2025년 한 해 동안 AI의 문서 페이지 뷰가 500% 이상 증가했고, 연말 기준 전체 문서 독자 중 AI 비중은 40%를 넘었습니다.
이 변화는 기술 조직에 다음과 같은 영향을 미치는데요. AI가 기술 문서를 정확하게 이해하고 인용하면, 사용자가 제품 사용법을 더 빠르게 파악하고 개발자는 더 좋은 코드로 양질의 소프트웨어를 만들 수 있죠. 또 AI 검색으로 기술 문서가 정확히 인용되면 조직과 제품의 신뢰도를 높일 수 있고요. 잠재 고객이 제품을 발견하는 데 도움이 될 수 있습니다.
그러나 대응하지 않으면 AI가 오래된 버전의 문서를 인용하거나, 맥락 없이 일부만 잘라 답변에 사용할 수 있고요. 내용을 부정확하게 재구성해 사용자에게 제공할 가능성이 있습니다. 이는 사용자 경험을 저하하고, 조직과 제품의 신뢰도에 타격을 입힐 수 있죠.
이 글에서는 AI의 문서 소비 메커니즘, AI 시대에 달라져야 할 문서 구조와 작성 원칙, 문서 인프라 점검과 AI 인용 측정 방법을 알아보겠습니다.
AI의 기술 문서 소비 방식
AI가 기술 문서를 소비하는 경로는 이미 보편화된 것과 지금 부상하는 것으로 나뉩니다. 각 경로의 동작 방식을 정확히 이해해야 문서 구조, 작성 원칙, 배포, 인프라 설계 방향을 올바르게 판단할 수 있습니다.
보편화된 AI의 문서 소비 경로
먼저 AI 검색 엔진과 AI 코딩 어시스턴트, 두 경로를 살펴보겠습니다.
AI 검색 엔진
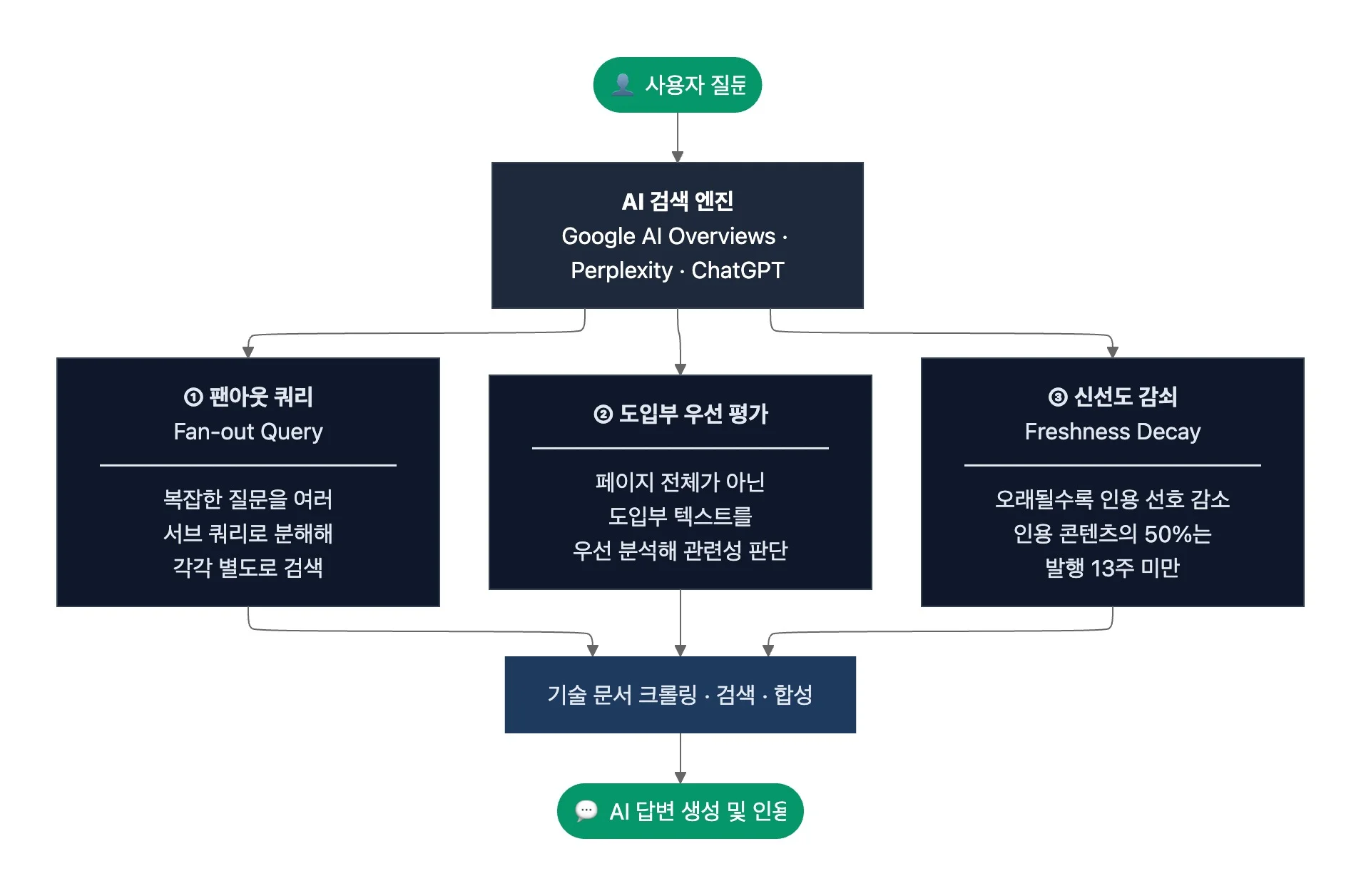
AI 검색 엔진은 사용자의 질문과 관련해 여러 웹 소스를 검색·합성해 직접 답변을 생성하는 AI 기반 검색 플랫폼입니다. Google AI Overviews, Perplexity, ChatGPT 웹 검색 등이 대표적이죠. 이 플랫폼들의 내부 동작 방식은 다르지만, 기술 문서를 크롤링·검색·합성해 답변에 인용한다는 핵심 동작은 공통적입니다.
AI 검색 엔진은 현재 AI의 가장 보편적인 기술 문서 소비 경로인데요. 문서 플랫폼 GitBook이 문서 업계 종사자 1131명을 대상으로 실시한 설문 보고서 “State of Docs 2026”에 따르면, 사용자가 문서를 발견하는 경로 1위는 직접 탐색(66%), 2위는 제품 내 링크(54%), 3위는 전통 검색 엔진(45%)이며, AI 기반 검색은 35%로 4위였습니다. 아직 전통 검색 엔진보다 낮지만, 비교적 최근에 등장한 경로가 전통 검색 엔진과의 격차를 10%p로 좁혔다는 점에서 성장 속도가 가파르죠.
AI 검색 엔진이 문서를 소비하는 방식에는 세 가지 핵심 특징이 있습니다. 첫째, AI는 사용자의 복잡한 질문을 여러 서브 쿼리로 분해해 각각 별도로 검색하는데요. 이를 ‘팬아웃 쿼리(Fan-out Query)’라고 합니다. 둘째, AI 검색 엔진은 페이지의 도입부 텍스트를 우선 평가해 답변과의 관련성을 판단하고요. 페이지 전체를 동일한 비중으로 보지 않습니다. 셋째, AI가 인용하는 콘텐츠는 시간이 지날수록 더 새로운 소스로 대체됩니다. 이를 ‘신선도 감쇠(Freshness Decay)’, 즉 콘텐츠가 오래될수록 AI의 인용 선호가 줄어드는 현상이라고 하죠. SEO·AI 검색 전문 에이전시 Amsive의 분석에 따르면, AI가 인용한 콘텐츠의 50%는 발행 13주 미만의 최신 콘텐츠였습니다.
AI 코딩 어시스턴트
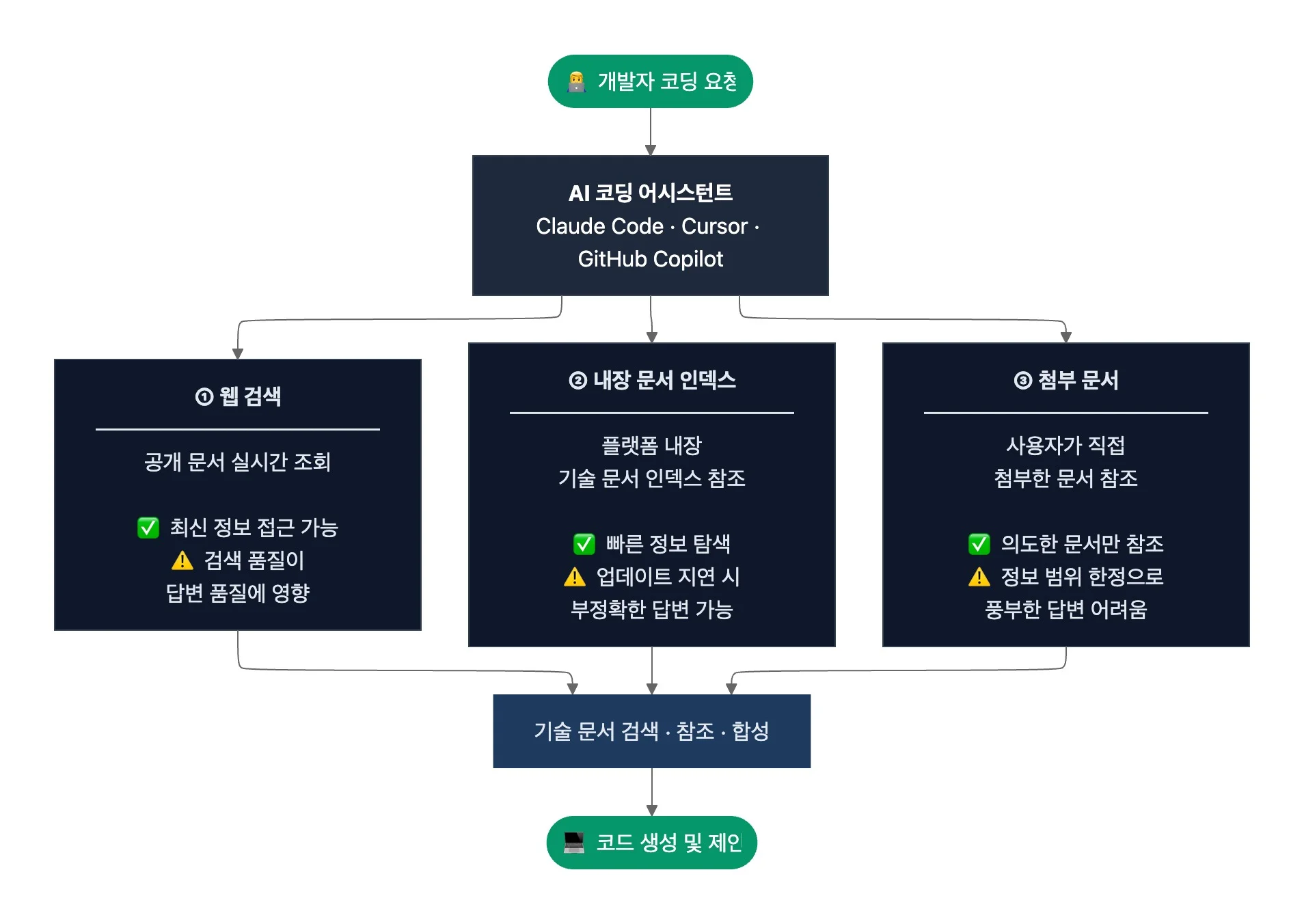
AI 코딩 어시스턴트는 개발자의 코딩 작업을 지원하면서 관련 기술 문서를 자동 검색·참조해 그 내용을 바탕으로 코드를 생성하는 AI 도구입니다. Claude Code, Cursor, GitHub Copilot 등이 그 예죠. 이 도구는 개발자 사이에서 빠르게 일상화되면서 기술 문서의 주요 소비 경로로 자리잡고 있습니다.
AI 코딩 어시스턴트가 문서를 소비하는 경로는 크게 세 가지인데요. 첫째, 웹 검색으로 공개 문서를 실시간 조회하고요. 둘째, 플랫폼에 내장된 기술 문서 인덱스를 참조합니다. 셋째, 사용자가 직접 첨부한 문서를 읽기도 하죠.
경로에 따라 AI가 접근하는 문서의 최신성과 범위는 달라집니다. 웹 검색은 최신 정보에 접근할 수 있지만, AI가 참조하는 문서는 검색 결과의 순위와 답변과의 관련성에 따라 달라지는데요. 검색 품질이 AI 답변의 품질에 영향을 줄 수 있죠. 아울러 플랫폼에 내장된 기술 문서 인덱스는 정보를 빠르게 찾는 데 도움이 되는데요. 그러나 업데이트가 지연되면 답변이 부정확할 수 있습니다. 또 첨부 문서는 사용자가 제공한 범위로 정보가 한정돼 풍부한 답변을 얻기 어려울 수 있고요.
지금 떠오르는 문서 소비의 새로운 경로
이어서 MCP 서버와 llms.txt 두 가지 새로운 경로를 살펴보겠습니다. 아직 초기 단계이지만 점점 확산되고 있는 문서 소비 방식입니다.
MCP 서버
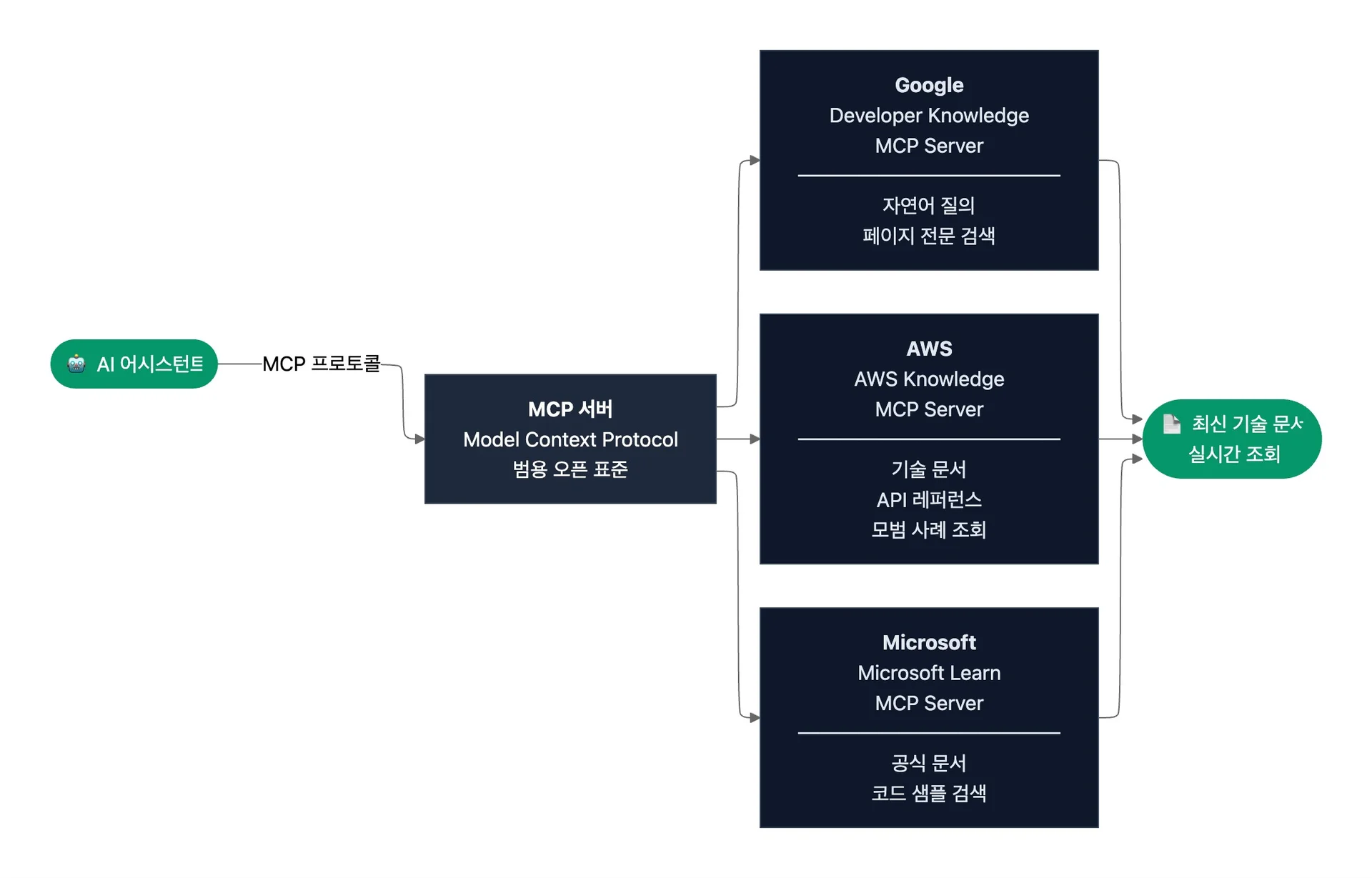
MCP(Model Context Protocol)는 AI 어시스턴트를 외부 데이터 소스와 연결하는 범용 오픈 표준입니다. AI가 학습 데이터에만 의존하지 않고, 실시간으로 외부 시스템의 최신 정보에 접근하도록 돕죠. 기술 문서 맥락에서 보면, AI 어시스턴트는 MCP 서버로 특정 제품이나 서비스의 문서에 직접 접근해 최신 정보를 실시간으로 조회할 수 있습니다.
이미 주요 클라우드 벤더가 자사 기술 문서에 접근할 수 있는 MCP 서버를 출시했는데요. Google은 자연어 질의와 페이지 전문 검색이 가능한 Developer Knowledge MCP Server를, AWS는 자사 기술 문서와 API 레퍼런스, 모범 사례를 조회할 수 있는 AWS Knowledge MCP Server를, Microsoft는 Microsoft Learn의 공식 문서와 코드 샘플을 검색·조회할 수 있는 Microsoft Learn MCP Server를 제공합니다. 3대 클라우드 벤더가 이 방식을 채택한 것은 AI의 실시간 문서 접근을 전략적으로 중요한 경로로 판단하고 있다는 신호입니다.
llms.txt
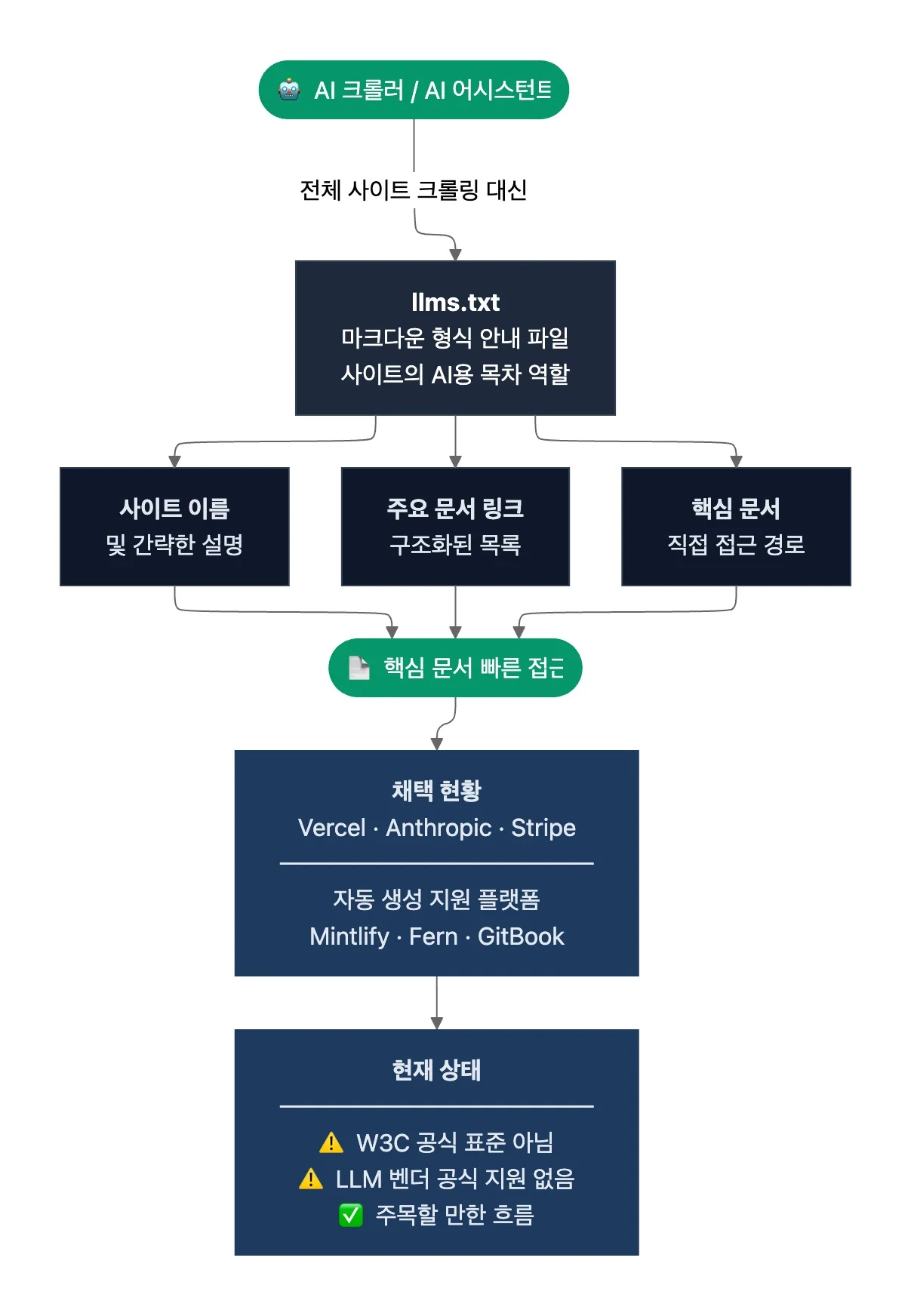
llms.txt는 웹사이트의 핵심 문서를 AI가 효율적으로 찾아 읽을 수 있도록 마크다운 형식으로 정리한 안내 파일입니다. 사이트 이름, 간략한 설명, 주요 문서 링크를 구조화해 담고 있어 AI에게 사이트의 목차 역할을 하죠. AI는 이 파일로 전체 사이트를 크롤링하지 않고도 핵심 문서에 빠르게 접근할 수 있습니다.
2024년 9월 AI 연구·개발 랩 Answer.AI 공동 창립자인 Jeremy Howard가 llms.txt를 제안했고요. 이후 Vercel, Anthropic, Stripe 등이 이를 채택한 것으로 알려졌습니다. Mintlify, Fern, GitBook 등 주요 문서 플랫폼이 llms.txt의 자동 생성을 지원하죠.
llms.txt는 아직 W3C 같은 웹 기술 국제 표준화 기구의 공식 표준이 아닌 제안 단계에 있습니다. 주요 LLM 벤더 중 자사 AI 크롤러가 llms.txt를 공식 지원한다고 발표한 곳은 없고요. 채택 현황은 측정 주체와 시점에 따라 수백 개에서 수십만 개까지 편차가 큽니다.
다만, llms.txt는 AI가 문서를 효율적으로 소비하기 위한 인터페이스로 주목할 만한 가치는 있고요. 기술 조직이 지금 당장 이를 사용하지 않더라도, 흐름을 인식하는 것은 의미가 있습니다.
AI 네이티브 시대의 기술 문서 구조와 작성 원칙
사람은 문서 구조가 다소 불명확해도 경험과 맥락으로 의미를 추론할 수 있습니다. 반면 AI는 문서를 구조화된 섹션 단위로 처리하며, 특정 섹션을 추출해 답변에 삽입하는데요. 문서 구조가 불명확하면 AI가 내용을 정확히 이해하거나 인용하기 어렵죠. 따라서 AI를 위한 기술 문서는 시각적 계층 구조와 의미적 명확성을 동시에 갖추는 것이 중요합니다. 다음은 이를 위한 구체적인 방법입니다.
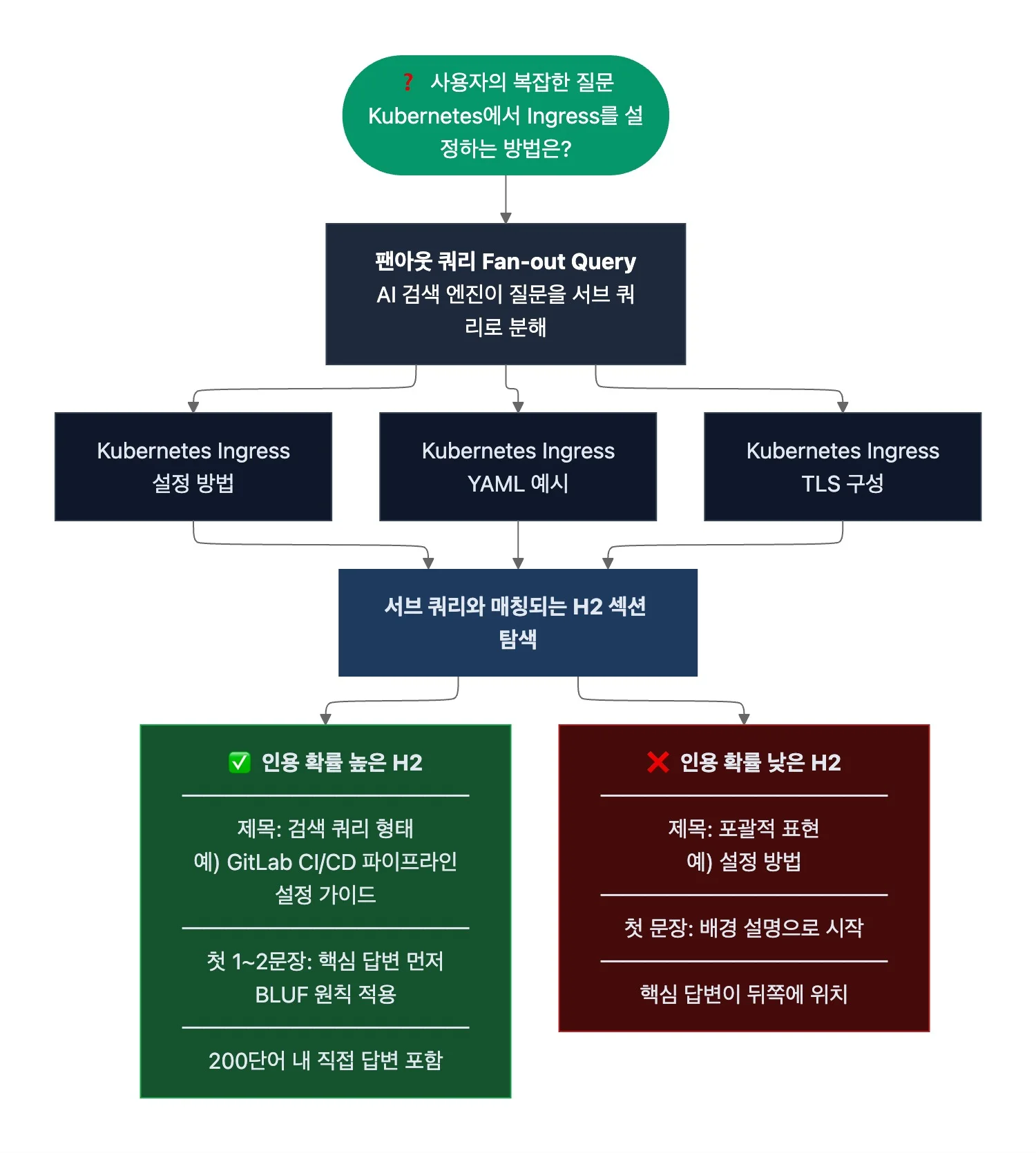
1. 각 H2 섹션이 하나의 질문에 독립적으로 답하도록 작성
-
필요성:
- AI 검색 엔진은 사용자의 복잡한 질문을 여러 개의 서브 쿼리로 분해해 각각 별도로 검색하는 ‘팬아웃 쿼리’ 방식으로 동작합니다. 예를 들어, “Kubernetes에서 Ingress를 설정하는 방법은?”이라는 질문은 “Kubernetes Ingress 설정 방법”, “Kubernetes Ingress YAML 예시”, “Kubernetes Ingress TLS 구성” 등으로 분해되죠. 문서의 각 H2 섹션이 이러한 서브 쿼리 하나의 답이 될 수 있어야 AI 검색 결과에 해당 섹션이 인용될 확률이 높아집니다.
-
적용 방법:
- H2 제목을 독자가 실제로 검색할 법한 질문이나 핵심 키워드 형태로 작성합니다. 예를 들어, “설정 방법”보다 “GitLab CI/CD 파이프라인을 설정하는 방법은?” 또는 “GitLab CI/CD 파이프라인 설정 가이드”가 AI 검색의 서브 쿼리에 매칭될 가능성이 높죠.
- 각 H2 섹션의 첫 1~2 문장은 해당 질문에 직접 답하도록 작성합니다. 이를 ‘BLUF(Bottom Line Up Front) 원칙’이라고 하는데요. BLUF는 군사 커뮤니케이션에서 유래한 원칙으로, 핵심 요점이나 메시지를 가장 먼저 제시하는 방식입니다.
- AI 검색 엔진은 페이지의 도입부 텍스트를 우선 평가해 답변의 관련성을 판단하는데요. H2 섹션 첫 부분에 핵심 답변이 있으면 AI가 해당 섹션을 관련성 높은 소스로 판단할 가능성이 커집니다. AI 마케팅 에이전시 Enrich Labs의 GEO 가이드에 따르면, 첫 200 단어 내에 핵심 질문의 직접적인 답변이 있을 때 이 효과가 나타납니다.
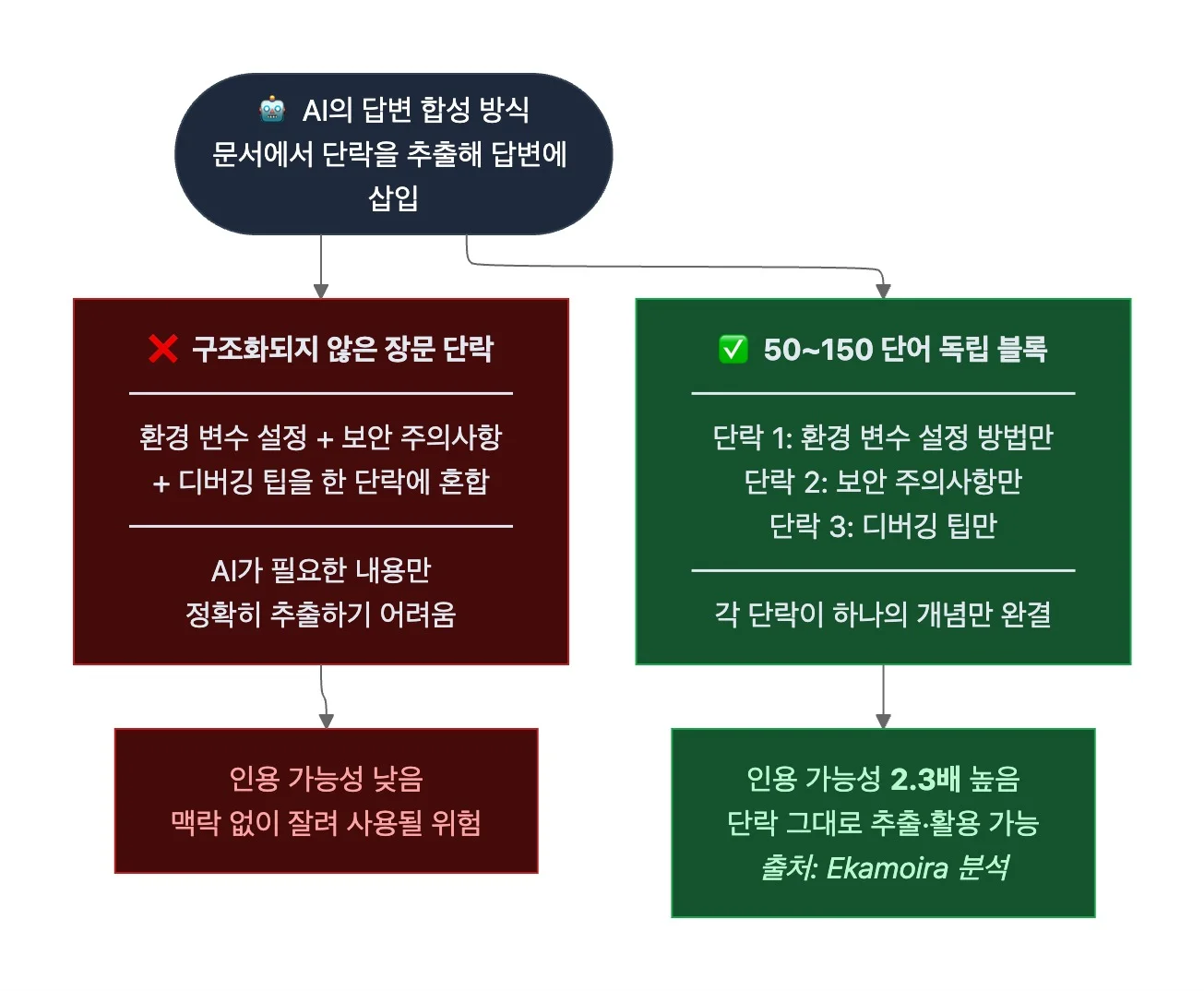
2. 각 단락을 50 ~ 150 단어 단위의 독립적 블록으로 구성
- 필요성:
- 앞서 H2 섹션 단위의 독립성을 다뤘다면, 여기서는 섹션 안의 각 단락 단위의 독립성을 다룹니다. AI는 답변을 합성할 때 문서에서 특정 단락을 추출해 답변에 삽입합니다. AI 검색 가시성 분석 플랫폼 Ekamoira의 분석에 따르면, 50 ~ 150 단어 단위의 자기 완결적 블록으로 구성된 콘텐츠는 구조화되지 않은 장문 콘텐츠보다 AI에 2.3배 더 많이 인용됐죠.
- 적용 방법:
- 하나의 단락이 하나의 개념만 완결된 구조로 다루도록 작성합니다. 예를 들어, 환경 변수 설정 방법, 보안 주의사항, 디버깅 팁을 다룬다면, 각 내용을 세 개의 독립된 단락으로 분리합니다. 각 단락이 자기 완결적일수록 AI가 해당 단락을 그대로 추출해 답변에 활용할 가능성이 높아집니다.
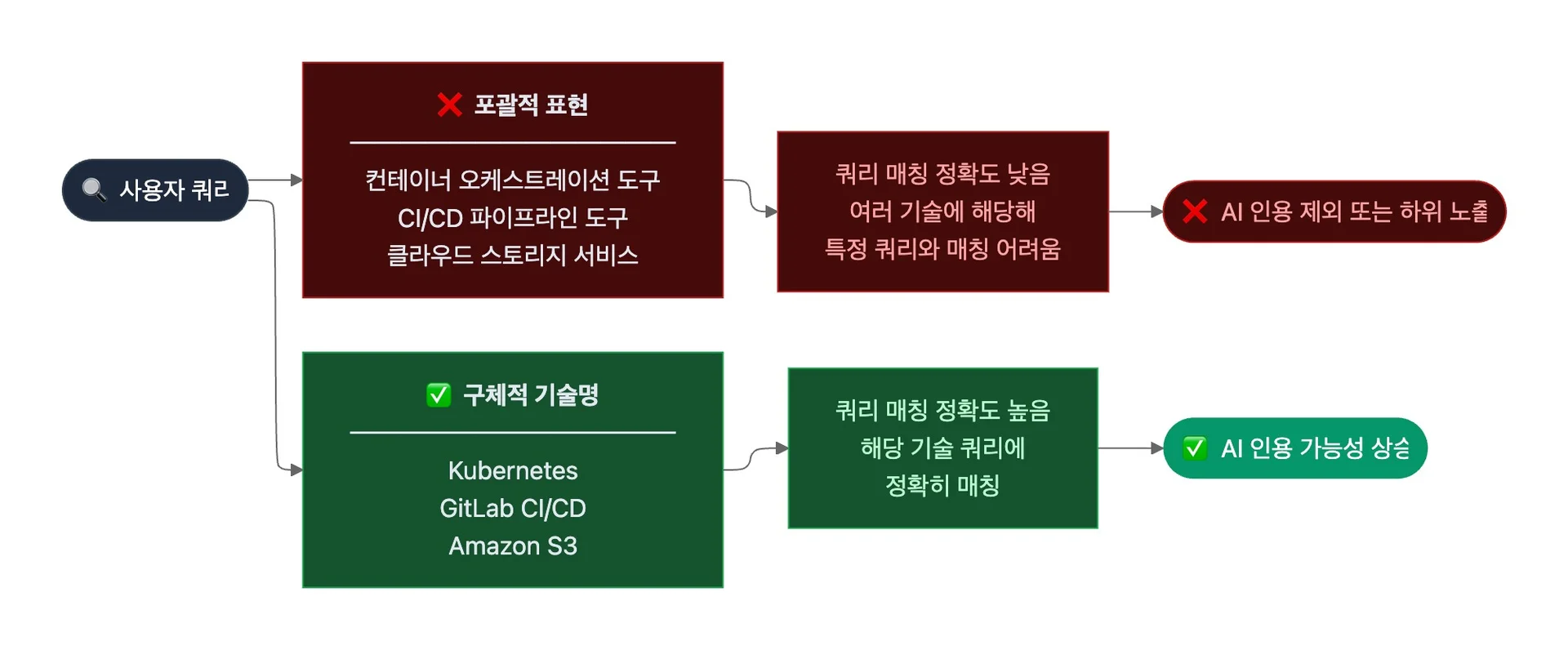
3. 구체적인 기술 용어 사용
- 필요성:
- 검색 시스템은 쿼리와 문서의 용어 일치도가 높을수록 관련성을 높게 평가합니다. 이 원리는 AI 검색 엔진에도 동일하게 적용되는데요. 포괄적인 표현은 여러 기술에 해당해 특정 쿼리의 매칭 정확도가 낮아지고, 구체적인 기술명은 해당 쿼리에 더 정확히 매칭될 가능성이 높습니다.
- 적용 방법:
- 기술 문서에서 포괄적인 표현 대신 구체적인 기술명을 사용합니다. 예를 들어, "컨테이너 오케스트레이션 도구”보다 "Kubernetes", "CI/CD 파이프라인 도구"보다 "GitLab CI/CD"처럼 구체적인 이름을 쓰면 AI가 해당 기술 관련 쿼리에 더 정확히 매칭할 수 있습니다.
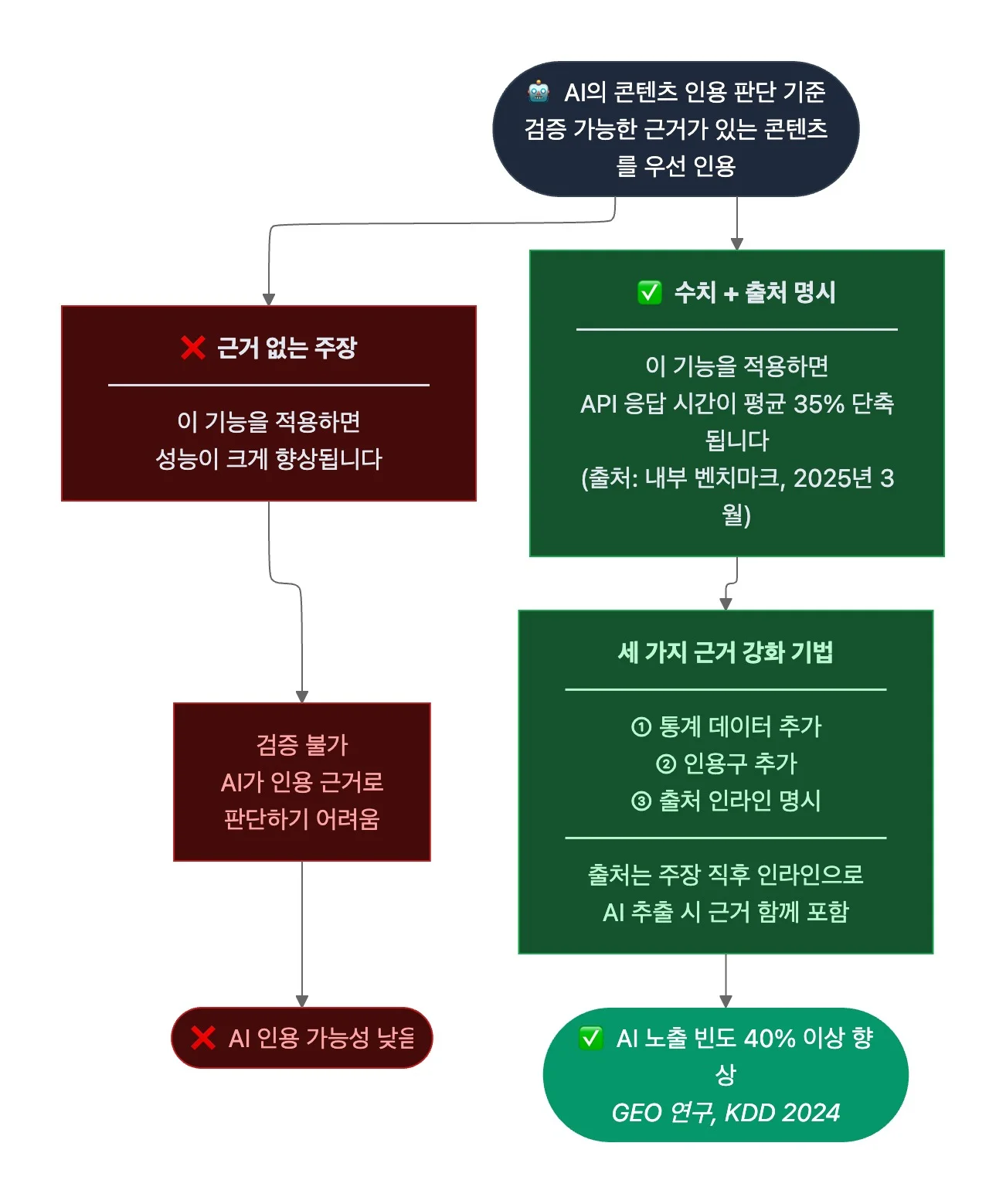
4. 출처와 통계 포함
- 필요성:
- AI는 검증 가능한 근거가 포함된 콘텐츠를 인용할 가능성이 더 높습니다. 프린스턴 대학교, 조지아공과대학교, IIT 델리 등 공동 연구팀의 GEO 연구(KDD 2024)에 따르면, 통계 데이터 추가, 인용구 추가, 출처 명시 등 기법을 적용했을 때 AI 생성 답변에서 콘텐츠 노출 빈도가 40% 이상 향상됐죠.
- 적용 방법:
- 주장에는 출처를, 성과에는 구체적 수치를 포함합니다. 예를 들어, 기술 문서에서 "이 기능을 적용하면 성능이 크게 향상됩니다"보다 "이 기능을 적용하면 API 응답 시간이 평균 35% 단축됩니다(출처: 내부 벤치마크, 2025년 3월)"처럼 수치와 출처를 함께 명시하면 AI가 인용할 가능성이 높아집니다. 출처는 주장 직후에 인라인으로 달아 AI가 해당 문장을 추출할 때 근거가 함께 포함되도록 합니다.
AI 네이티브 시대의 기술 문서 인프라 점검과 인용 측정
기술 문서 구조와 작성 원칙을 개선해도 배포와 인프라가 뒷받침되지 않으면 AI가 문서에 접근조차 하지 못할 수 있습니다. 다음은 우선순위별로 점검하고 조정해야 할 항목입니다.
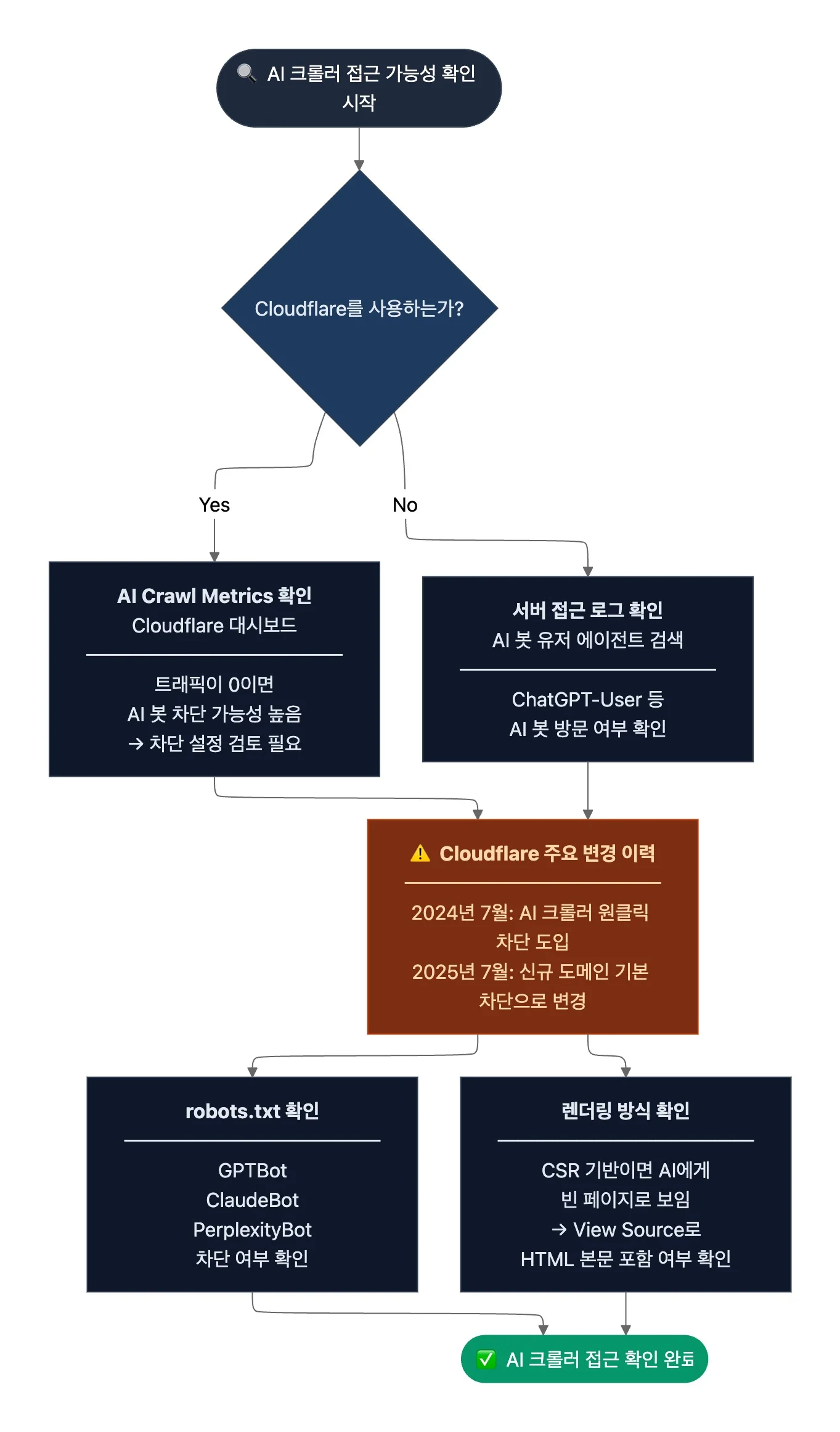
1. AI 크롤러의 문서 사이트 접근 가능성 확인
- 필요성:
- Cloudflare는 2024년 7월에 ‘AI 크롤러 원클릭 차단’ 옵션을 도입했습니다. 이어 2025년 7월부터 신규 도메인에 AI 크롤러 차단을 기본 설정으로 변경했는데요. Cloudflare를 사용하는 사이트는 별도 설정 변경 없이는 AI 봇 트래픽이 자동으로 차단됐을 수 있죠. 이 상태에서는 기술 문서 구조를 개선해도 AI가 문서를 읽을 수 없는데요. AI 크롤러의 문서 사이트 접근 가능성은 반드시 먼저 확인해야 합니다.
- 확인 방법:
- Cloudflare를 사용한다면, 대시보드의
AI Crawl Metrics에서 AI 봇 트래픽을 확인합니다. 트래픽이 0으로 나타나면 AI 봇이 차단됐을 가능성이 높기에 차단 설정을 확인해야 합니다. 구체적인 설정 변경 방법은 Cloudflare 버전과 플랜에 따라 다른데요. 자세한 내용은 Cloudflare의 공식 AI 봇 관리 문서를 참고하세요. - Cloudflare를 사용하지 않는다면, 서버 접근 로그에서
ChatGPT-User와 같은 AI 봇 유저 에이전트를 검색해 AI 봇이 실제로 사이트를 방문하는지 확인합니다. - Cloudflare 사용 여부와 관계없이
robots.txt에서GPTBot,ClaudeBot,PerplexityBot등 AI 크롤러를 차단하고 있지 않은지도 함께 확인합니다. - 문서 사이트가 CSR(Client-Side Rendering) 기반이면 AI 크롤러에게 빈 페이지로 보여 인용 대상에서 제외될 수 있습니다. 페이지 소스 보기(View Source)를 열어 본문 콘텐츠가 HTML에 포함됐는지도 함께 확인합니다.
- Cloudflare를 사용한다면, 대시보드의
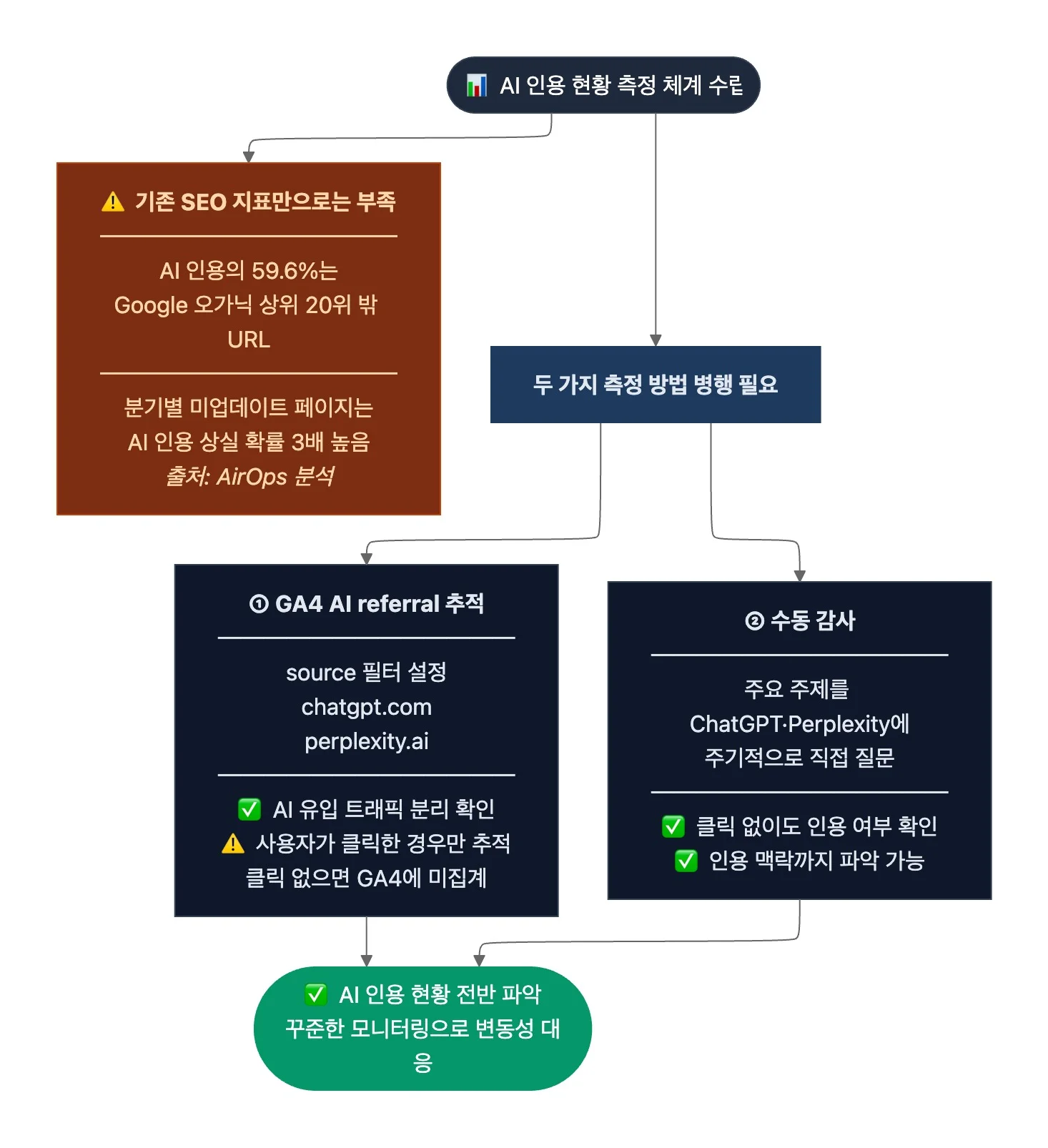
2. AI 인용 현황 측정 체계 수립
- 필요성:
- 기존 SEO 지표(순위, 오가닉 트래픽)만으로는 AI 인용 성과를 파악할 수 없습니다. AI 검색 최적화 플랫폼 AirOps의 Google AI Overviews 분석에 따르면, AI Overview 인용의 약 59.6%가 Google 오가닉 검색 결과 상위 20위에 없는 URL에서 발생하고요. 같은 분석에 따르면, 분기별로 업데이트되지 않은 페이지는 기존 AI 인용을 잃을 확률이 3배 더 높다고 하죠. 이 수치들은 Google AI Overviews에 한정된 데이터로 Perplexity나 ChatGPT의 인용 패턴과 다를 수 있습니다. 그러나 기존 SEO 순위와 AI 인용이 별개이며, 지속적인 콘텐츠 업데이트가 필수임을 수치로 보여주죠. AI 인용은 고정된 순위가 아니기에 변동성이 크고, 꾸준한 모니터링이 필요합니다.
- 측정 방법:
- GA4에서 AI referral 트래픽을 분리 추적합니다. source 필터에
chatgpt.com,perplexity.ai등을 설정하면 AI 플랫폼에서 유입되는 트래픽을 별도로 확인할 수 있습니다. 다만, 이 방법은 AI가 문서를 인용한 뒤 사용자가 링크를 클릭해 유입된 경우만 추적합니다. AI가 문서를 인용했어도 사용자가 클릭하지 않으면 GA4에 잡히지 않습니다. - 따라서 수동 감사를 병행해야 합니다. 자기 조직의 기술 문서 주요 주제를 ChatGPT나 Perplexity에 주기적으로 질문해 ‘실제로 인용되고 있는지’, ‘어떤 맥락에서 인용됐는지’ 확인합니다. GA4의 클릭 유입 추적과 수동 감사를 함께 수행하면 AI 인용의 전반적인 현황을 파악하는 데 도움이 됩니다.
- GA4에서 AI referral 트래픽을 분리 추적합니다. source 필터에
이 글에서 다룬 방법은 기존 SEO를 대체하는 것이 아닙니다. 잘 구조화된 문서, 명확한 제목 계층, 구체적인 기술 용어, 출처가 있는 정보, 정기적인 업데이트는 SEO와 AI 인용 모두에 유리합니다. 기존 SEO 기반 위에 AI 소비를 위한 구조적 레이어를 얹는 것으로 접근하는 걸 권장합니다.
맺음말
지금까지 AI가 기술 문서를 소비하는 메커니즘, AI 네이티브 시대에 달라져야 할 문서 구조와 작성 원칙, 문서 인프라 점검과 AI 인용 측정 방향을 살펴봤습니다. 이 글의 요점은 다음과 같은데요.
- AI 검색 엔진과 AI 코딩 어시스턴트는 이미 기술 문서의 주요 소비자입니다. MCP와
llms.txt같은 새로운 경로도 확산되고 있습니다. - 문서의 각 섹션이 독립적으로 답할 수 있는 구조, 50 ~ 150 단어의 자기 완결적 블록, 구체적인 기술 용어, 출처와 통계가 AI 인용 확률을 높입니다.
- AI 크롤러 접근 가능성 확인과 AI 인용 현황 측정 체계 구축이 필요합니다.
참고 자료
- Rémi Gonnu, “AI docs readership increased over 500% in 2025. What does it mean for you?”, GitBook, 2026-02-04, https://www.gitbook.com/blog/ai-docs-data-2025
- “The State of Docs Report 2026”, GitBook, https://www.stateofdocs.com/2026/docs-and-product
- “Content Freshness and AI Search: Why 50% of AI Citations Are Under 13 Weeks Old”, Salespeak, 2026-03-09, https://salespeak.ai/aeo-news/content-freshness-ai-search
- Jess Kuras, “Introducing the Developer Knowledge API and MCP Server”, Google for Developers, 2026-02-04, https://developers.googleblog.com/introducing-the-developer-knowledge-api-and-mcp-server/
- “Welcome to Open Source MCP Servers for AWS”, AWS, https://awslabs.github.io/mcp/
- “Microsoft Learn MCP Server overview”, Microsoft, https://learn.microsoft.com/en-us/training/support/mcp
- Jeremy Howard, “The /llms.txt file”, llms-txt, 2024-09-03, https://llmstxt.org/
- Seijin, “Generative Engine Optimization (GEO): The Complete 2026 Guide to Ranking in AI Search”, Enrich Labs, 2026-02-24, https://www.enrichlabs.ai/blog/generative-engine-optimization-geo-complete-guide-2026
- Soumyadeep Mukherjee, “LLM Citation Tracking: The Science of How AI Systems Choose Sources to Reference”, Ekamoira, 2026-01-04, https://www.ekamoira.com/blog/ai-citations-llm-sources
- Pranjal Aggarwal·Vishvak Murahari·Tanmay Rajpurohit·Ashwin Kalyan·Karthik Narasimhan·Ameet Deshpande, “GEO: Generative Engine Optimization”, KDD 2024, 2024-06-28, https://arxiv.org/pdf/2311.09735
- “Cloudflare, AI 크롤러의 인터넷 전체 스크래핑 방식을 혁신하다: 새로운 비즈니스 모델의 길을 개척하는 권한 기반 접근 방식”, Cloudflare, 2025-07-01, https://www.cloudflare.com/ko-kr/press/press-releases/2025/cloudflare-just-changed-how-ai-crawlers-scrape-the-internet-at-large/
- “Block AI Bots”, Cloudflare, https://developers.cloudflare.com/bots/additional-configurations/block-ai-bots/
- Oshen Davidson, “The 2026 State of AI Search: How Modern Brands Stay Visible”, AirOps, 2025-12-02, https://www.airops.com/report/the-2026-state-of-ai-search
우리 회사에 딱 맞는 DevSecOps 관행과 프레임워크를 찾고 계시나요? DevOps 전문가, 인포그랩과 상담하세요!
사전 동의 없이 2차 가공 및 영리적인 이용을 금하며, 온·오프라인에 무단 전재 또는 유포할 수 없습니다.
Grace
Technical Writer
DevOps 도입이 필요하신가요?
인포그랩 전문가가 맞춤 을 도와드립니다.
관련 글

Claude Skills로 기술 콘텐츠 품질 관리 자동화하기
인포그랩은 AI 네이티브 기업으로 도약하며, 전사적으로 Claude Skills 개발을 장려하고 있습니다. 이 글은 글쓴이가 기술 블로그 리뷰 Skill을 만든 과정, 시행착오, 개선 경험을 다뤘습니다. ‘완성된 성공 사례’가 아닌, ‘진행 중인 실험’의 기록입니다.
2026년 2월 11일

‘Teleport 공식 기술 문서 한글판 by 인포그랩’을 소개합니다
‘Teleport 공식 기술 문서 한글판 by 인포그랩’은 OpenAI의 생성형 AI 모델 GPT를 사용해 Teleport 공식 기술 문서 총 700여 개를 한글로 번역해 제공합니다. 이 서비스에서는 Teleport 도입, 설치, 관리, 사용 방법 등 정보를 한글로 즉시 볼 수 있습니다. 또 키워드 검색 기능으로 필요한 문서를 쉽고 빠르게 찾을 수 있습니다. 인포그랩은 Teleport의 공식 리셀러입니다.
2024년 11월 27일

엔지니어를 위한 기술 블로그 작성 비법(feat. 빠르고 완성도 높게 글쓰기)
오늘날 엔지니어는 README, API 설계 문서, 가이드 등 다양한 기술 문서를 작성합니다. 이들은 기업 브랜딩과 DevRel 활동을 위해 사내 기술 블로그 기고도 자주 요청받습니다. 이 글은 인포그랩과 소프트웨어 엔지니어 Andy의 기술 블로그 업무 수행 방식을 토대로 ‘엔지니어가 마감일 안에 사내 기술 블로그를 쉽고 빠르게 고품질로 완성하는 팁’을 다뤘습니다.
2024년 8월 21일