[현장 스케치] “n8n Korea 온라인 밋업 #3 팀을 위한 자동화 3탄” 후기!

안녕하세요, 대한민국 DevOps 액셀러레이터! 인포그랩입니다. 🙌
2025년 4월 25일, 인포그랩이 주최한 세 번째 [n8n Korea 온라인 밋업]을 참가자들의 큰 호응과 열띤 참여 속에 성공적으로 진행했습니다. 🎉
이번 밋업에서는 지난 두 번째 밋업보다 더욱 확장된 n8n 실전 자동화 사례를 다뤘는데요.
💡 개발팀 스탠드업부터 디자인 피드백 실시간 적용, 마케팅용 기술 콘텐츠 수집·배포, 장애 분석까지
기술팀뿐만 아니라 비 기술팀의 업무 효율을 높이는 다양한 n8n 자동화 워크플로를 공유했습니다.
총 4개의 세션 발표와 참가자 질의응답만으로도 두 시간이 쏜살같이 지나갔는데요.
💬 실시간 채팅도 활발해 참가자들의 관심과 집중도가 그 어느 때보다도 높았던 자리였습니다.
지금부터 세 번째 n8n Korea 밋업의 주요 발표 내용과 현장 분위기를 살펴보겠습니다.
이번 밋업에는 👨💻 인포그랩 소프트웨어 엔지니어 Fabbro와 Jhin, DevOps 엔지니어 Chad와 Joshua가 발표자로 참여했습니다. 🧑💼 테크니컬 라이터 Grace가 사회를 맡았고요.
이전 밋업과 달리 모든 발표자가 각자 다른 장소에서 원격으로 참여한 ‘완전 분산형 온라인 밋업’이었습니다. 🌐

🎬 오후 7시, 밋업이 시작됐습니다.
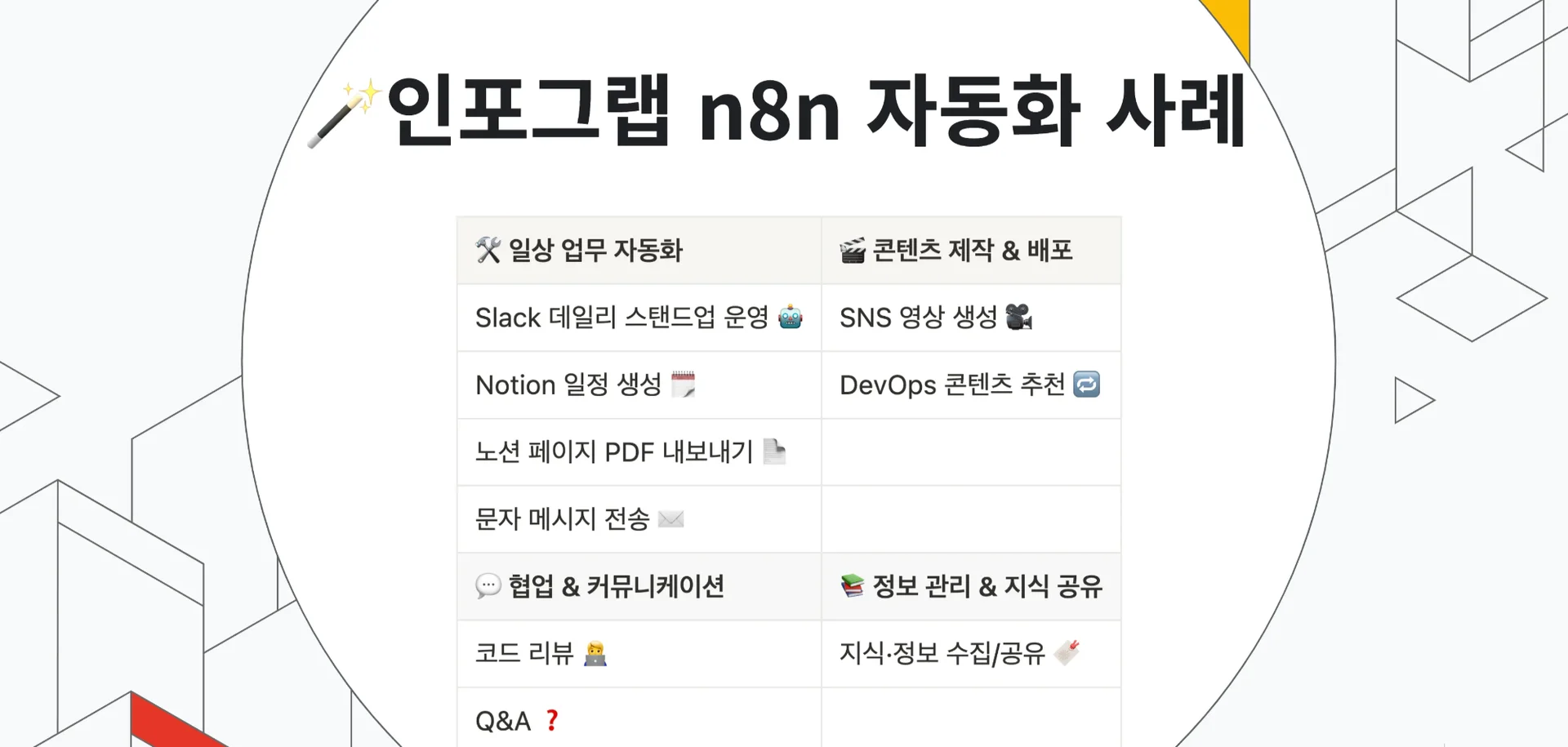
먼저 Grace가 인포그랩의 다양한 n8n 자동화 사례를 중심으로, 사내 자동화 역량을 소개했는데요. Slack 데일리 스탠드업 봇 운영, Notion 페이지 PDF 내보내기, 문자 메시지 전송, SNS 영상 생성, DevOps 콘텐츠 추천, 코드 리뷰 등 현업에 실제 적용한 자동화 사례를 공유했습니다.

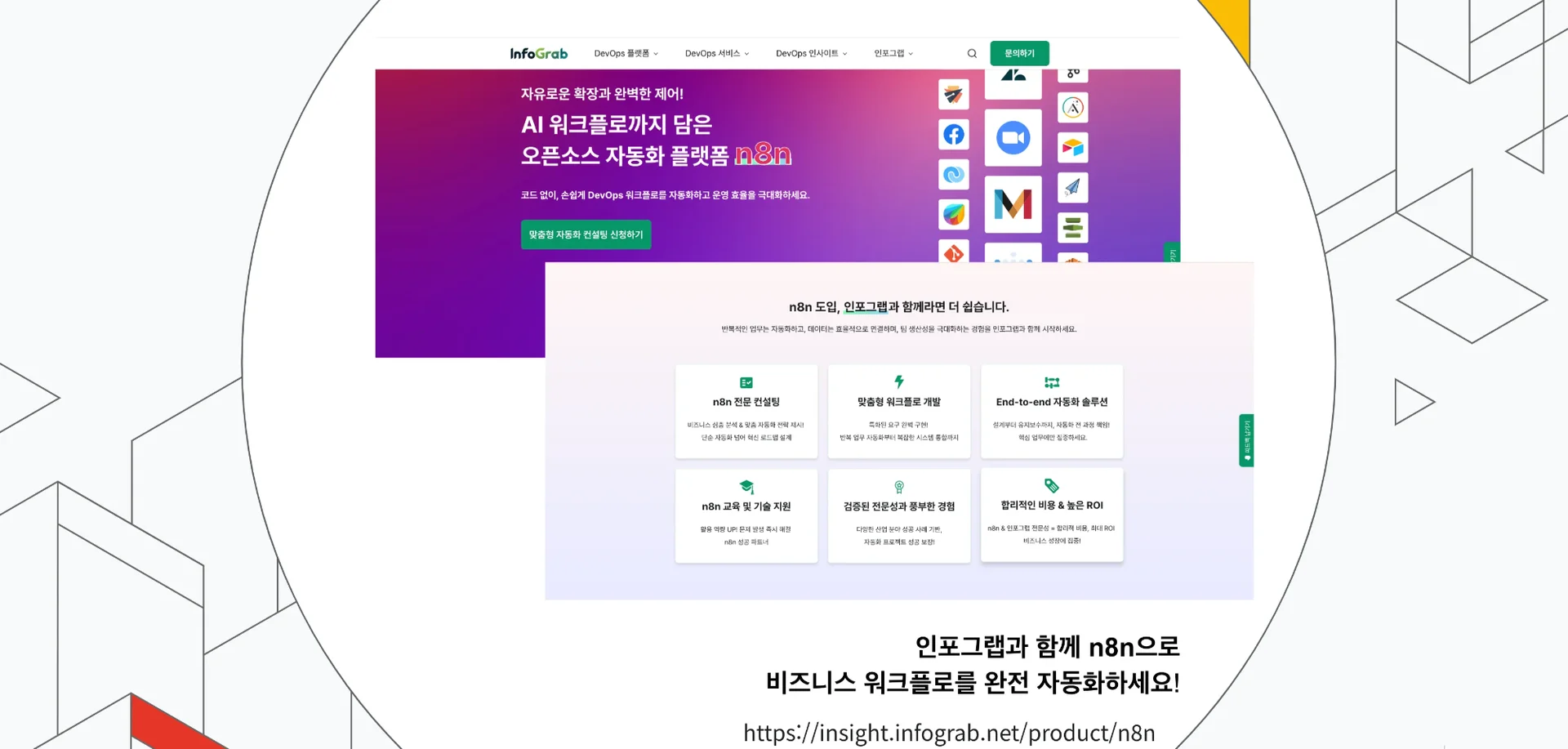
이어서 인포그랩의 n8n 자동화 지원 서비스를 자세히 소개했습니다.
인포그랩은 ▲n8n 전문 컨설팅 ▲맞춤형 워크플로 개발 ▲설계~유지보수 자동화 솔루션 ▲n8n 교육, 기술 지원을 제공하는데요. n8n 자동화 라이프사이클 전반을 적극 지원하고 있습니다. n8n을 더 빠르게 안정적으로 도입하고 싶으시면 언제든지 인포그랩에 문의하시면 됩니다.

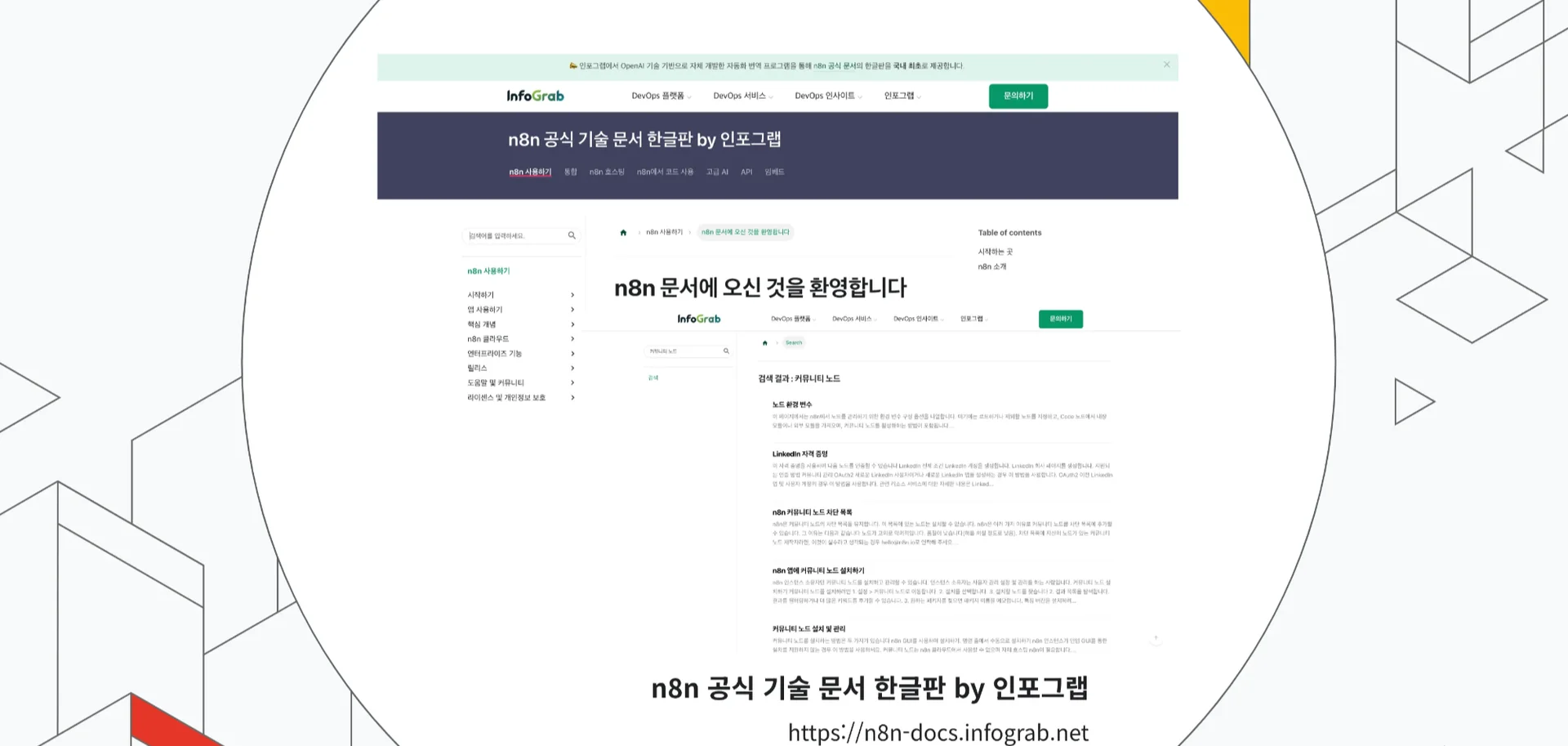
그다음, “n8n 공식 기술 문서 한글판 by 인포그랩”과 “n8n Korea - 워크플로 자동화 커뮤니티 (링크드인)”를 소개했는데요.
n8n 공식 기술 문서 한글판에서는 인포그랩의 GPT 기반 자동 번역 프로그램을 활용해 n8n 전체 공식 문서를 한글로 제공합니다.
📖 Grace는 “공식 문서는 n8n 자동화를 학습할 때 가장 정확하고 신뢰할 만한 자료로, 입문자에게 추천한다”고 설명했어요.

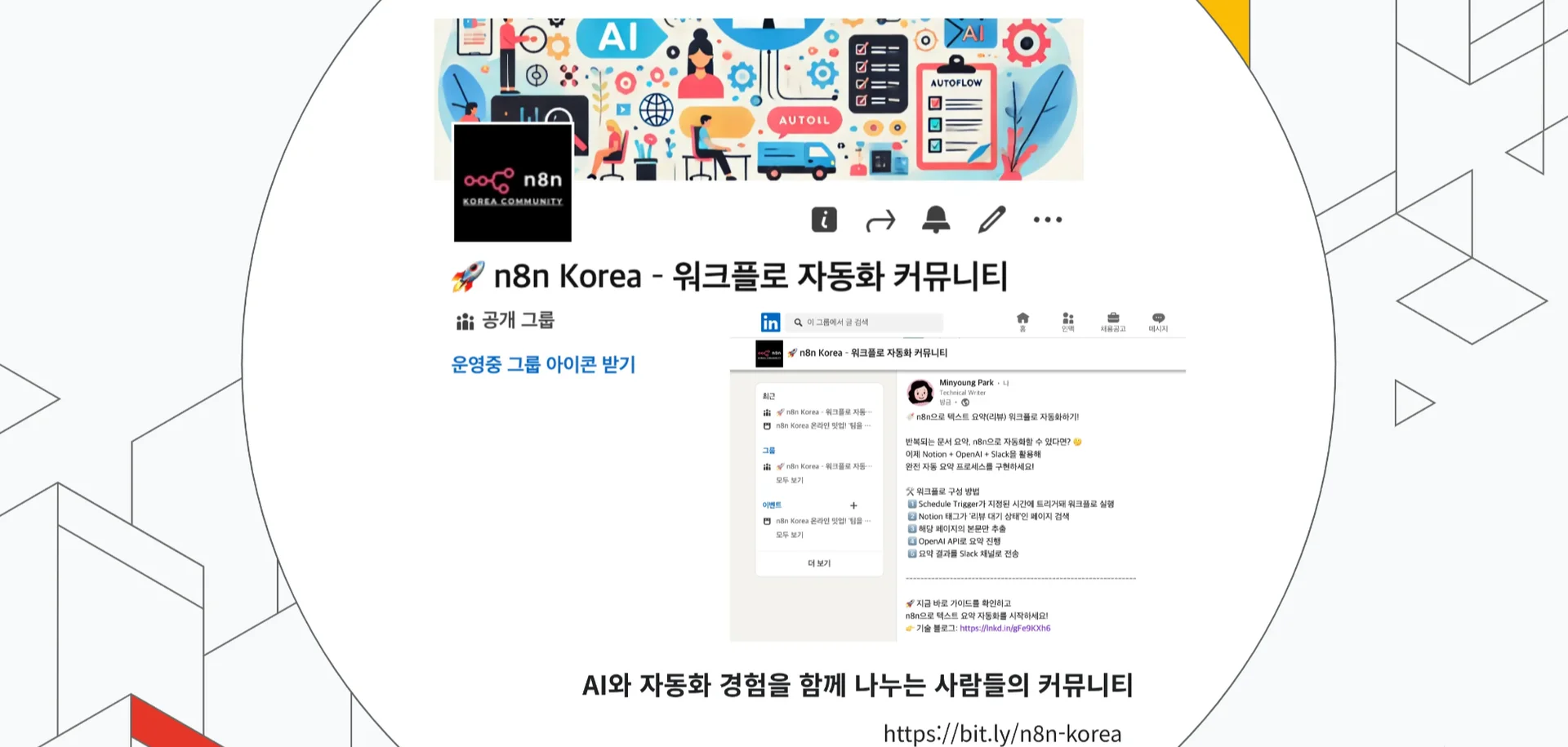
n8n Korea 커뮤니티에는 지난 밋업 영상과 n8n 사용법 데모, 가이드 등 실전 중심 자료를 공유하는데요. 최근 회원 수 190명을 돌파하며, 업계의 관심이 빠르게 증가하고 있습니다. 이번 밋업 영상도 커뮤니티 가입자에게만 단독 공개할 예정입니다.
Session 1. 개발팀을 위한 스탠드업 자동화 👨💻


그럼 이제 본격적으로 세션 내용을 살펴볼까요?
첫 번째 세션에서는 소프트웨어 엔지니어 Fabbro가 ‘개발팀을 위한 스탠드업 자동화’를 주제로 발표했습니다.
GitLab에서 팀원의 업무 내용을 자동 수집해 데일리 스탠드업 보고서를 자동 생성, Slack에 자동 공유하는 워크플로를 보여줬는데요. 이 워크플로는 지난 밋업 참가자의 실제 니즈를 반영해 개발한 자동화 사례였습니다.
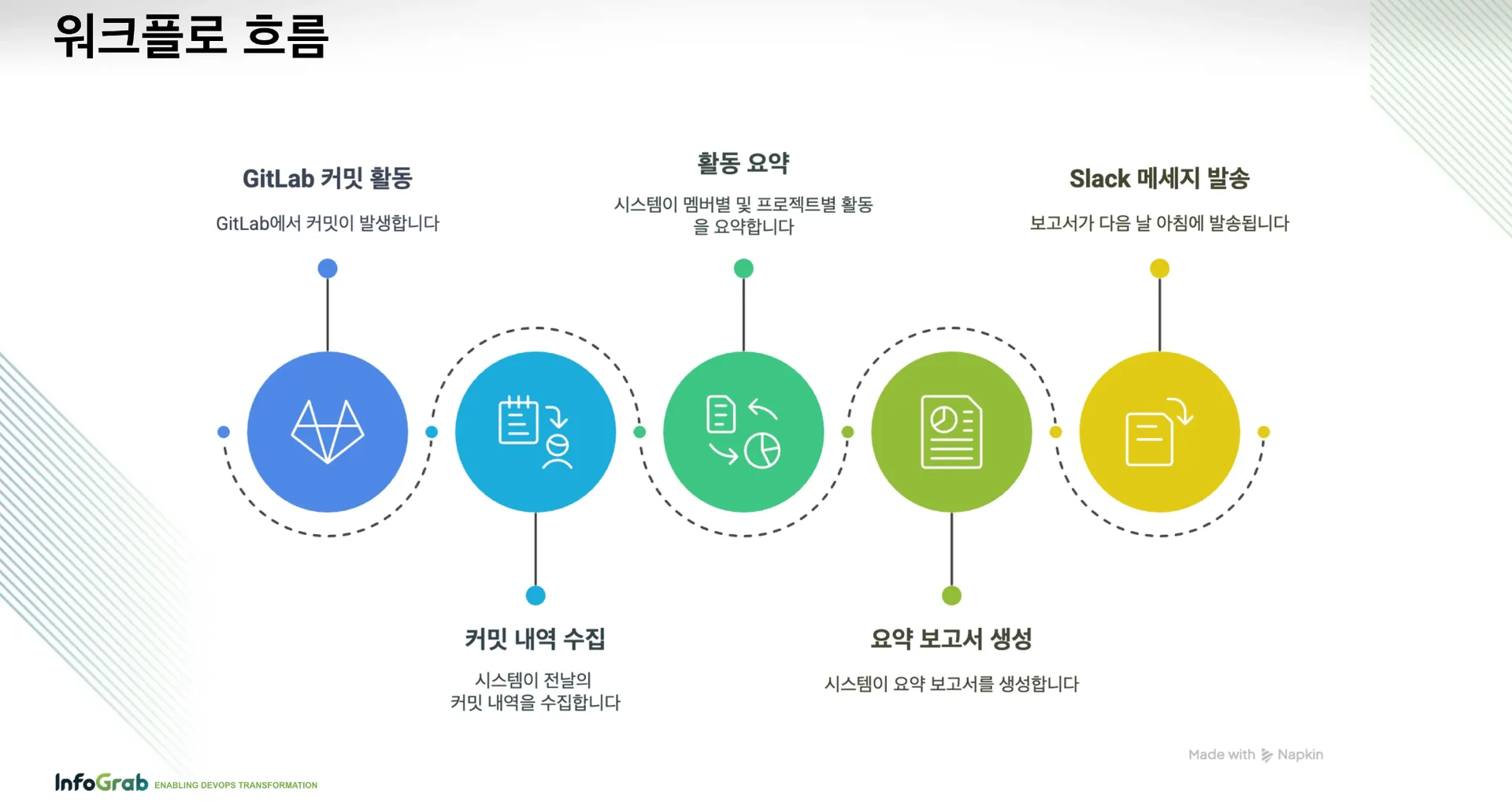
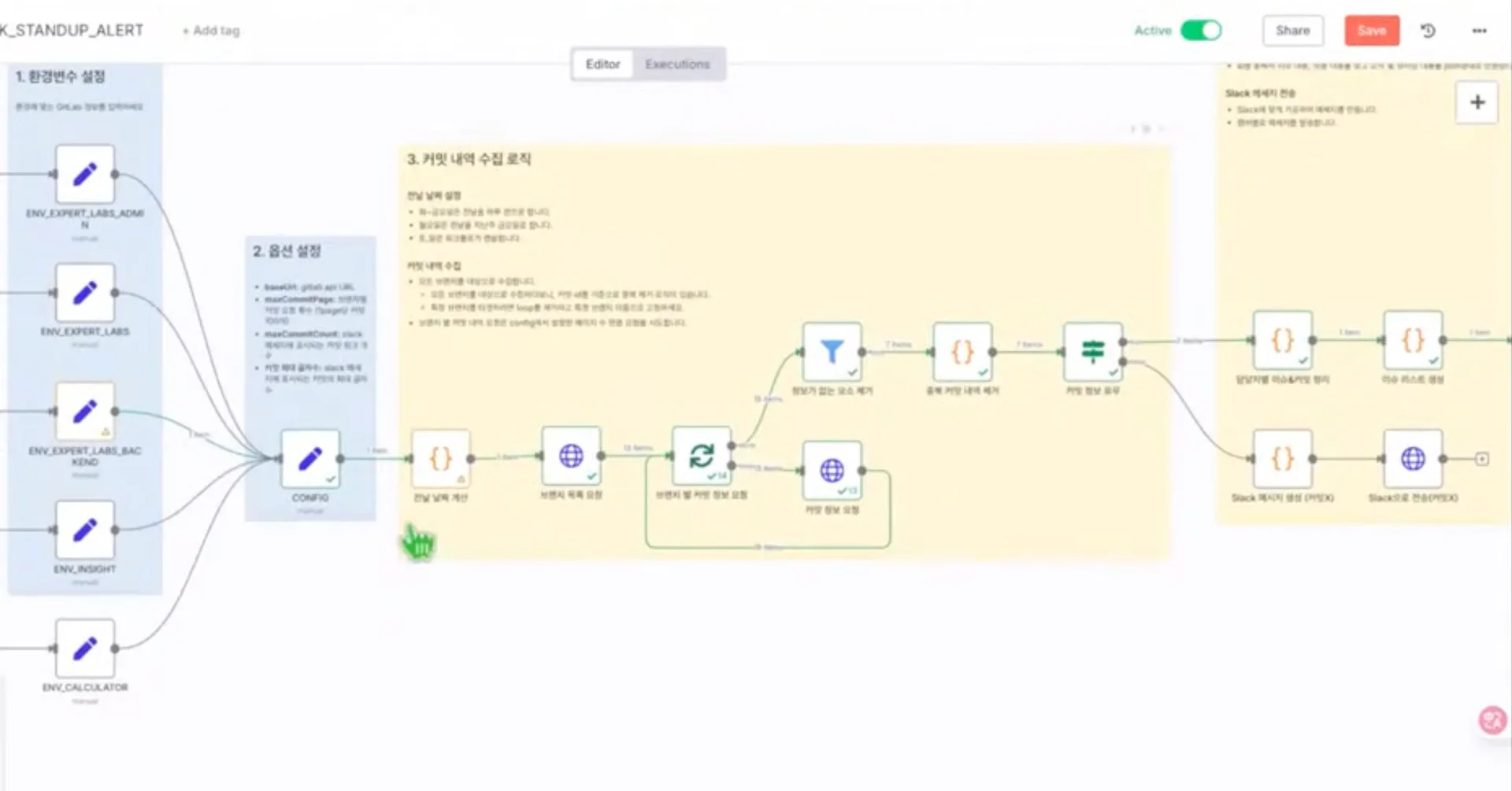
구체적인 워크플로는 이렇습니다. GitLab에서 전날 커밋 내역 수집 → 팀원별/프로젝트별 활동 요약 → 요약 보고서 생성 → 다음 날 아침, Slack에 보고서를 발송하는 방식이고요.
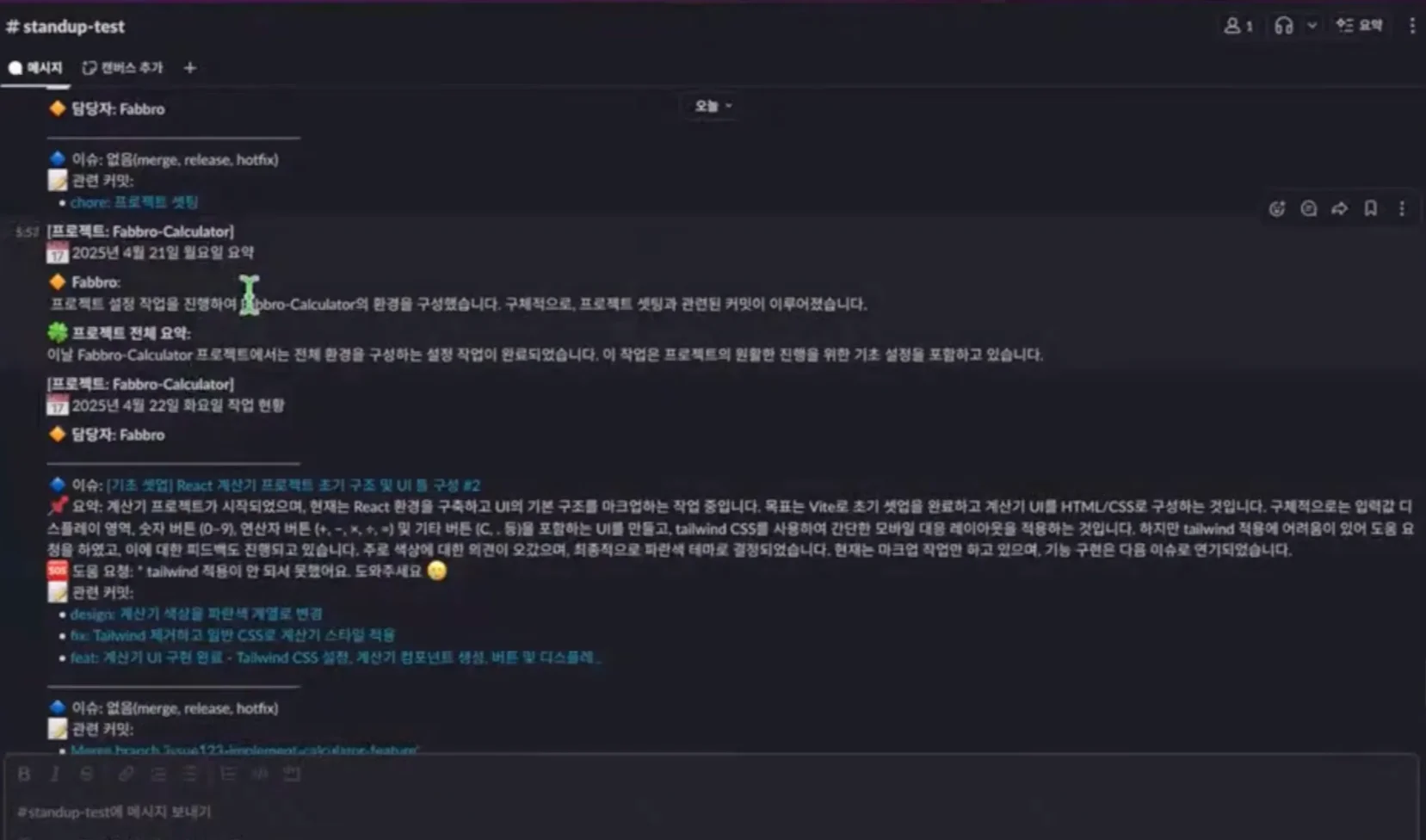
보고서는 프로젝트명, 날짜, 담당자명, GitLab 이슈, 커밋 등으로 구성됐습니다. GitLab 이슈에 남긴 도움 요청 메시지, 팀원 간 스레드 논의 내용도 포함했죠. 또 주간 보고서를 생성해 한 주간 팀원의 활동 내용과 프로젝트 현황, 피드백도 정리하도록 구성했습니다.
이 워크플로는 GitLab뿐만 아니라 GitHub, Jira 등 다양한 협업 도구와도 연동할 수 있고요. 팀 환경에 맞춰 유연하게 적용할 수 있습니다.
Fabbro는 “어떤 정보를 파악해야 빠르게 업무를 이어갈 수 있을지 고민하고, 이와 관련한 팀 차원의 컨벤션을 정의해 구체적으로 구현하면 자동화 효과가 더욱 강력해질 것”이라고 조언했습니다.
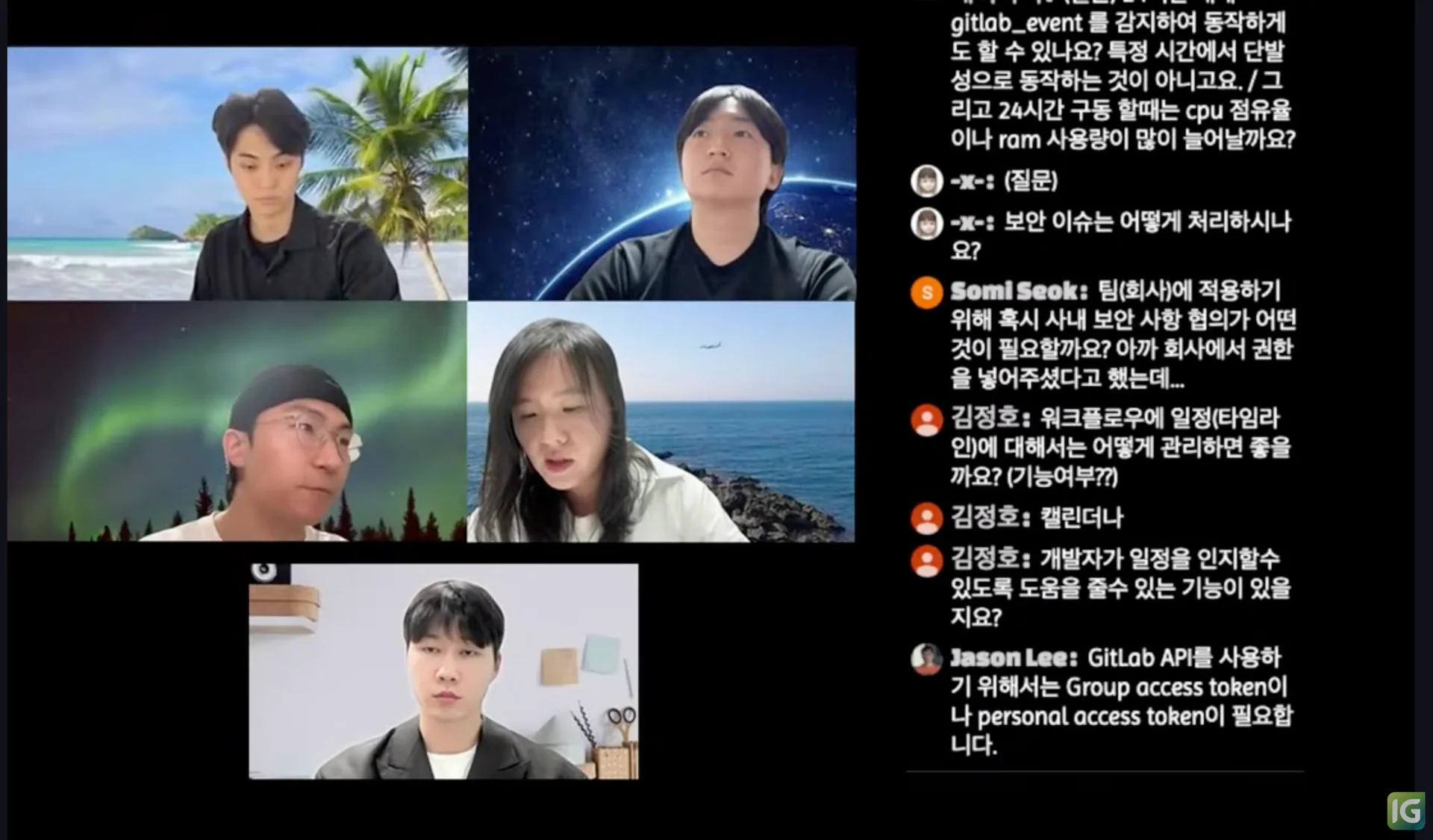
참가자들은 실무 적용 방안을 두고 다양한 질문을 쏟아냈는데요. 워크플로 일정 관리 방법, 사내 보안 사항 협의 방향, GitLab 이벤트 실시간 탐지·동작 방법, 실시간 실행 시 CPU 점유율과 RAM 사용량 변화 등 현실적이고, 심도 있는 질문이 이어졌습니다.
또 다른 참가자는 “업무 공유와 커밋 메시지를 남길 때 문화 측면에서 좋은 예시”라는 소감을 남겼고요.
‘보고’는 필수 업무지만, 반복되다 보면 시간이 오래 걸려 부담스러울 때도 있는데요. n8n으로 이를 자동화하면 소통 업무 간소화, 보고 누락 방지, 업무 투명성 향상, 조직 신뢰도 강화 효과를 거둘 수 있습니다. Fabbro가 발표한 ‘개발팀 스탠드업 자동화’는 이 효과를 달성하는 지름길로, 팀 협업의 품질까지 높이는 뜻깊은 사례였습니다.
Session 2. 디자인팀을 위한 피드백 적용 자동화 🎨


두 번째 세션에서는 DevOps 엔지니어 Chad가 ‘디자인팀을 위한 피드백 적용 자동화’를 주제로 발표했습니다.
Slack에 남긴 디자인 요청 사항을 Figma에 실시간으로 자동 반영하는 워크플로를 소개했는데요. 최근 주목받는 MCP와 n8n을 연동해 자동화 기능을 확장하는 방법을 구체적으로 다뤄 인상적이었습니다.

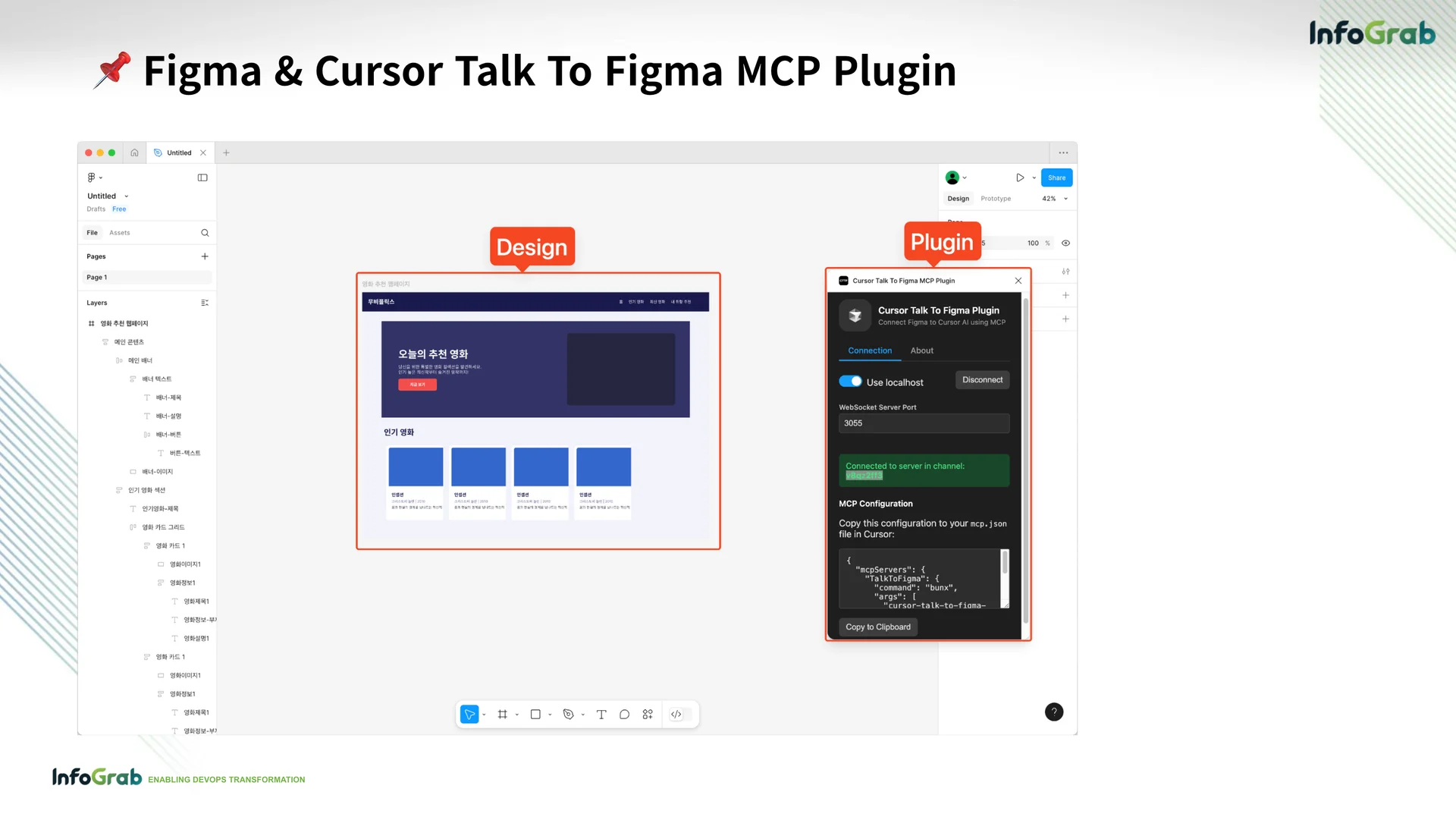
Chad는 ‘Cursor Talk to Figma’ MCP를 n8n과 함께 사용하는 방법을 자세히 보여줬는데요. 이 MCP가 디자인 피드백 적용 자동화의 핵심 도구이기 때문입니다.
Cursor Talk to Figma MCP는 Cursor AI 코드 에디터와 Figma 디자인 도구 간 양방향 통신을 지원합니다. 개발자나 디자이너는 이를 활용해 자연어 명령으로 Figma 디자인을 생성하고 수정할 수 있죠.
예를 들어, Cursor에서 “로그인 페이지를 만들어줘”라고 입력하면, Figma에서 디자인 요소를 자동 생성할 수 있습니다. 이 MCP는 응답이 빠르고, 실시간 업데이트를 지원하는 게 강점입니다.
Chad의 디자인 피드백 적용 자동화 워크플로는 다음과 같이 구성됐습니다. Slack 챗봇에 “포켓몬스터 도감 웹페이지를 만들어줘” 입력 → Slack 이벤트 수신 → 메시지 포맷팅 → AI 에이전트 처리 → Figma에 해당 웹페이지를 자동 생성하는 방식이죠.
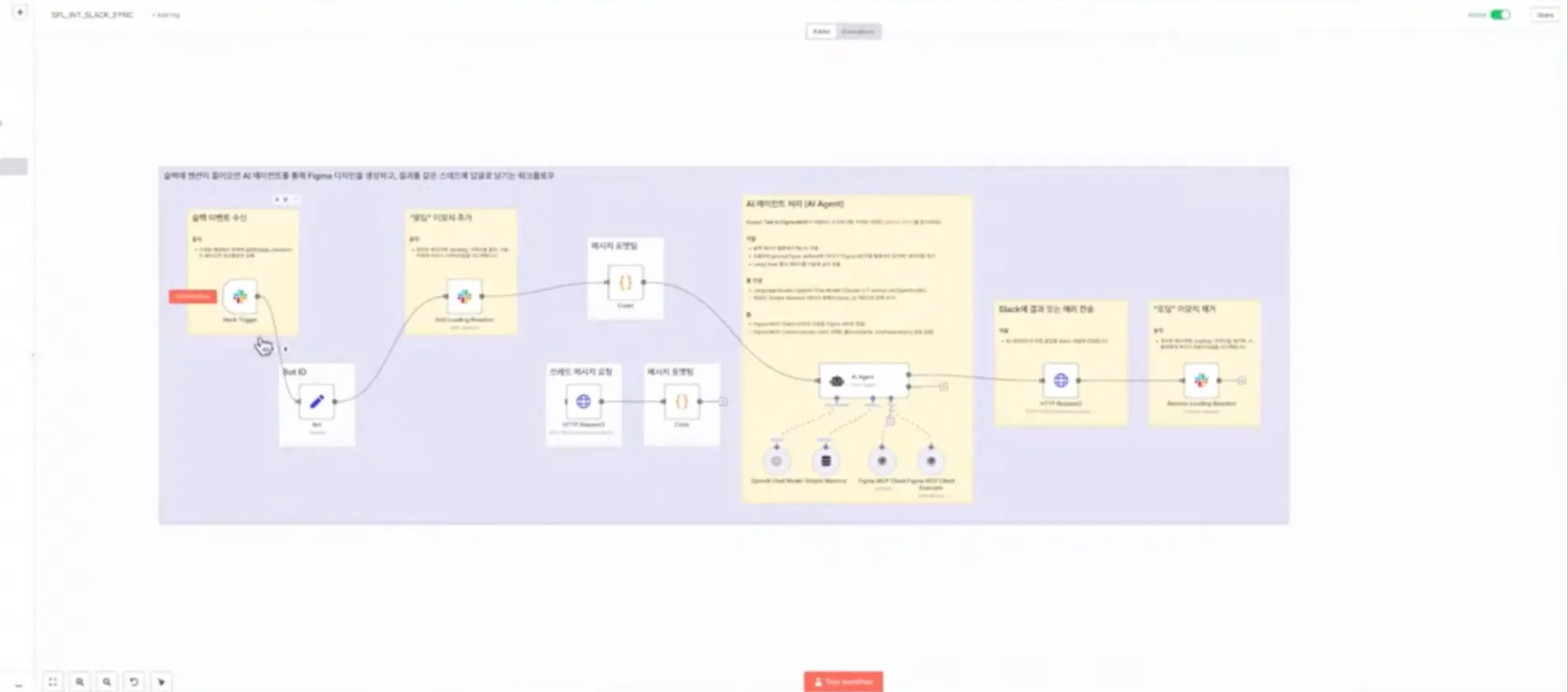
Chad는 향후 워크플로 개선 방향으로 “디자인 페이지에서 팀원이 유용한 피드백을 이모지로 표시하면, 이모지가 많이 달린 피드백을 Figma에 자동 등록하도록 설정할 수 있다”고 말했습니다. 또 n8n 1.88 버전부터 도입된 MCP Client Tool 노드를 사용하면 좋은 워크플로를 만들 걸로 예상했고요.
한편, 이번 Q&A 시간에도 기술적으로 깊이 있는 질문이 잇따랐는데요. MCP Client와 MCP Client Executor의 차이, make 대비 n8n의 강점 등 문의가 있었습니다. MCP와 n8n 실무 적용을 염두에 둔 질문이 두드러졌습니다.
Chad의 발표는 MCP와 n8n 연동으로 자동화 기능을 확장하고, 디자인팀의 ‘틈새 니즈’도 세밀하게 해결할 수 있음을 보여줬고요. 나아가 디자인과 리뷰 속도 향상, 팀 소통 비용 절감, 협업 흐름 개선 효과가 기대되는 사례였습니다.
Session 3. 마케팅팀을 위한 기술 콘텐츠 수집·배포 자동화 📣


세 번째 세션에서는 DevOps 엔지니어 Joshua가 ‘마케팅팀을 위한 기술 콘텐츠 수집·배포 자동화’를 주제로 발표했습니다.
DevOps/시스템 엔지니어 대상 콘텐츠를 Hacker News에서 자동 수집하고, 링크드인에 자동 배포하는 워크플로를 공개했는데요. 특히 정교한 프롬프트 엔지니어링으로 고품질 콘텐츠를 자동 선별한 뒤, 정보를 체계적으로 구조화해 가독성 높게 자동 편집한 점이 돋보였습니다. 이 워크플로도 MCP와 n8n을 연동한 사례였어요.
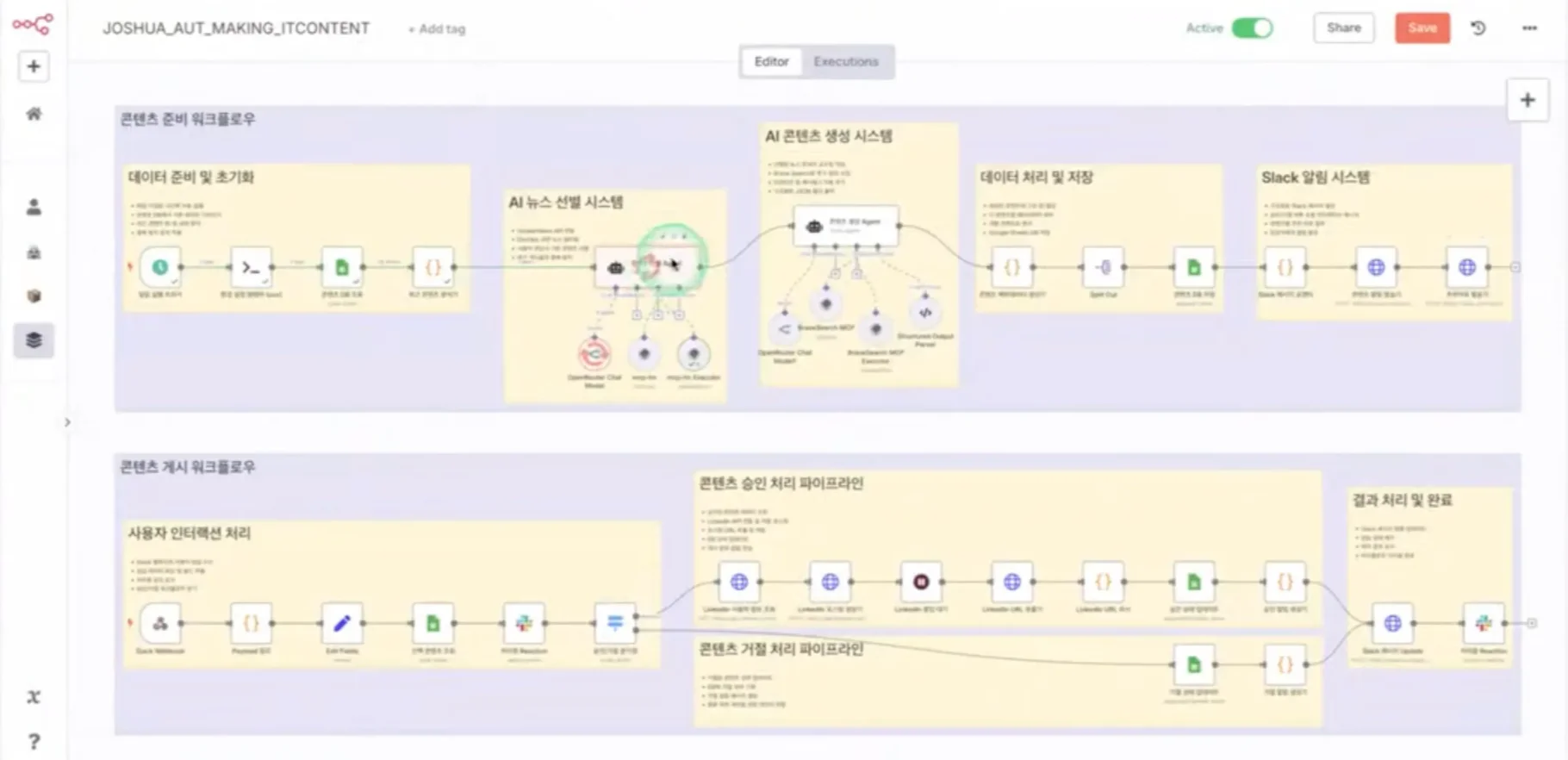
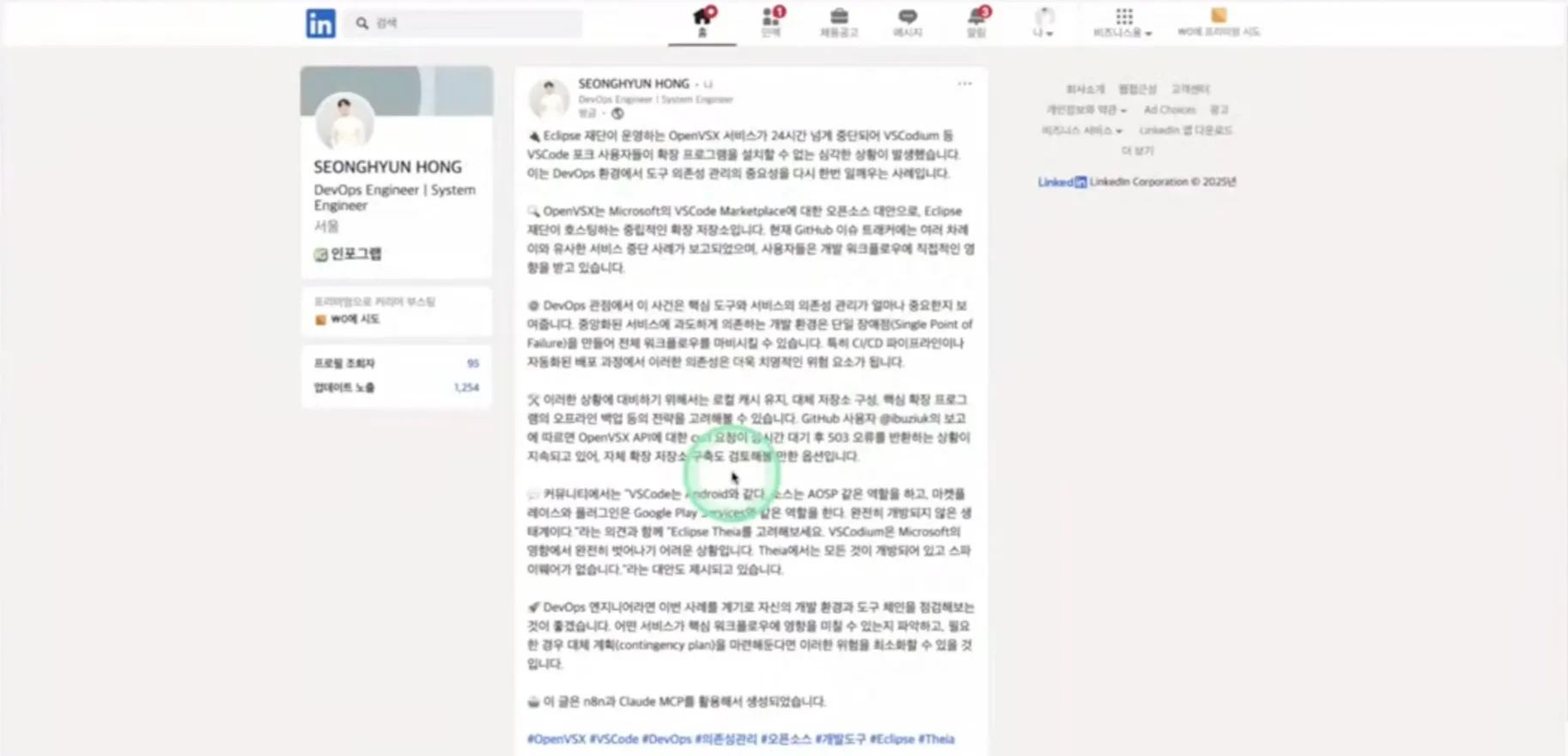
기술 콘텐츠 수집·배포 자동화 워크플로의 핵심은 바로 AI 에이전트였는데요. Joshua는 두 가지 AI 에이전트를 만들었습니다. 하나는 콘텐츠 선별 에이전트, 다른 하나는 콘텐츠 생성 에이전트인데요. 이는 무분별한 콘텐츠 생성을 제어하고, 콘텐츠 품질을 개선하기 위한 장치로 개발했습니다.
콘텐츠 선별 에이전트의 작동 방식은 이렇습니다. 사용자 선호도 분석 → Hacker News에서 데이터 수집 → 상세 정보 수집 → 관련성과 선호도 기반 콘텐츠 선별 → 선별 결과를 포맷팅하는 방식이죠.
콘텐츠 생성 에이전트는 콘텐츠 선별 에이전트에게 받은 결과를 토대로 이렇게 작동합니다. 입력 뉴스 평가 → 추가 정보 검색 전략 계획 → Brave Search MCP로 정보 수집 → 링크드인 게시용 콘텐츠 구조화 → 개인화된 추천 작성 → 출력을 JSON 형식으로 포맷팅 → 링크드인 API로 전송하는 방식입니다.
최종 결과물인 링크드인 게시글은 다음과 같은 구조로 완성됐습니다. 콘텐츠 요약, 배경 설명, 의미 해석, 실용 팁, 여론 분석 등으로 구성됐고요. 문단 구분과 핵심 이모티콘 배치로 가독성과 시각적 완성도를 높였습니다.
아래에는 해시태그와 원문 링크를 삽입했고요. “n8n과 Claude MCP를 활용해 생성했다”고 명시해 AI 생성 콘텐츠임을 투명하게 밝혔습니다.

Joshua는 앞으로 진행하고 싶은 n8n 과업으로 다음 내용을 언급했는데요. “MCP Trigger 노드를 활용한 n8n SSE 서버를 도입해 안정성을 강화하고, AI 에이전트에 다양한 페르소나를 적용하도록 프롬프트를 템플릿화하고 싶다”고 말했습니다.
이 세션에서는 참가자들 간의 질의응답이 활발했습니다. 기술 콘텐츠 수집·배포 자동화를 향한 높은 관심을 확인할 수 있었죠. 한 참가자는 “좋은 품질의 응답을 받으려면 비용이 발생하겠다”며 AI 활용의 현실적 한계를 짚기도 했습니다.
이밖에 Expression 자연어 작성 시 이해도, 워크플로 구현 시간, n8n 워크플로 작업 시간 단축 방안, 시스템 간 API 연계 복잡도와 프롬프트 파인 튜닝 난이도 비교 등 실무 관련 질문이 이어졌고요.
Joshua가 발표한 ‘기술 콘텐츠 수집·배포 자동화’는 DevOps/시스템 엔지니어뿐만 아니라 다양한 페르소나로도 확장 적용할 수 있는 실용적인 사례였습니다. 이 모델은 마케팅팀 외에도 DevRel 팀, 커뮤니티 운영자, 개인 브랜딩에도 효과적으로 활용할 수 있을 걸로 예상됩니다.
Session 4. CS팀을 위한 고객 장애 분석 자동화 🛠️

네 번째 세션에서는 소프트웨어 엔지니어 Jhin이 ‘CS팀을 위한 고객 장애 분석 자동화’를 주제로 발표했습니다.
B2C 환경에서 발생하는 고객 이슈를 AI로 자동 분석하고, Slack과 GitLab으로 신속하게 대응하는 CS 자동화 워크플로를 소개했는데요. 기존 장애 대응 과정에서 반복되던 수작업을 n8n으로 대폭 간소화해 주목받았습니다.
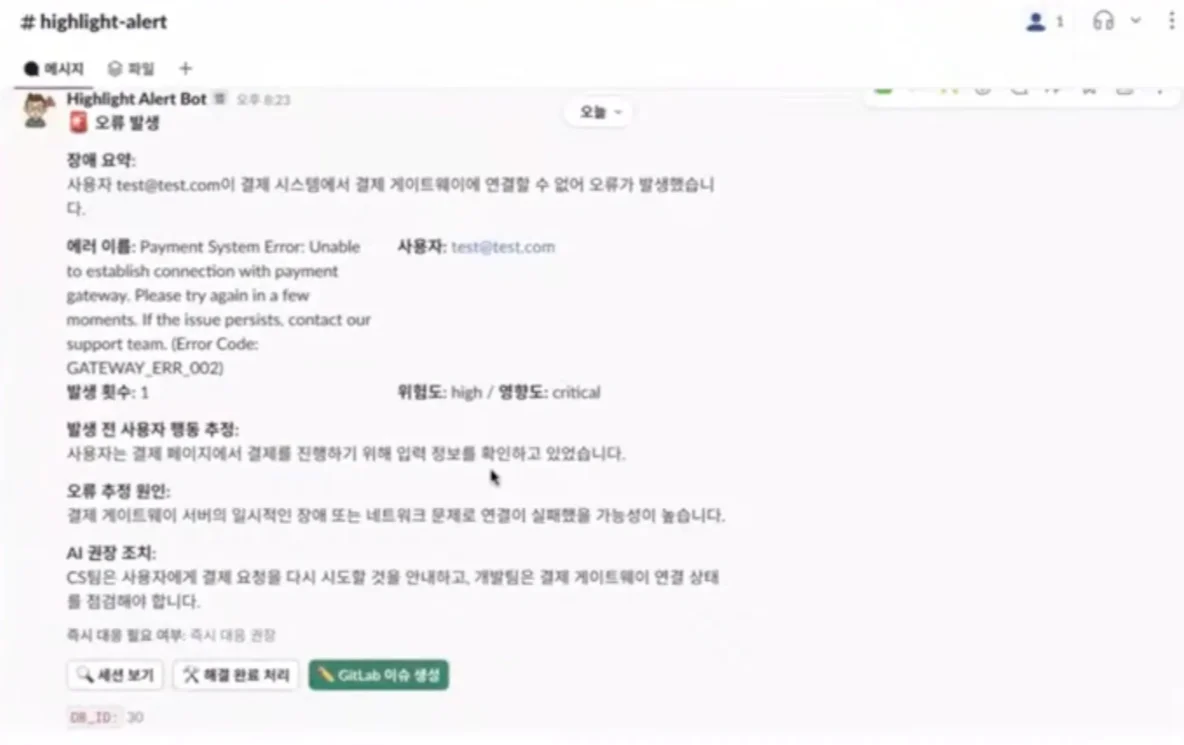
기존에는 고객 장애가 발생하면 다음과 같은 수작업을 거쳤습니다. 장애 접수 확인 → 원인 파악 시도 → 장애 이슈 등록 → 엔지니어 로그 검토 → 고객 히스토리 재요청, 수신 → 히스토리와 로그 비교 후 해결 과정을 밟았죠. 그러다 보니 장애 대응 시간이 오래 걸렸는데요. 그러나 n8n 자동화 워크플로를 구축하면, 장애 대응 과정을 최소한으로 축소할 수 있습니다.
Jhin은 Highlight, n8n, Slack, GitLab을 연동한 자동화 워크플로로 문제 해결 방법을 보여줬는데요. 구체적인 워크플로는 다음과 같습니다. Highlight이 프론트엔드/백엔드에서 정보를 받는 중 오류 확인 → n8n으로 웹훅 요청 전송 → CS팀이 확인하기 쉽도록 정보 가공 → Slack에 오류 메시지 발송 → GitLab에 이슈를 등록하는 방식이죠. 오류 원인은 AI로 분석해 조치 방향을 제시하도록 했고요.
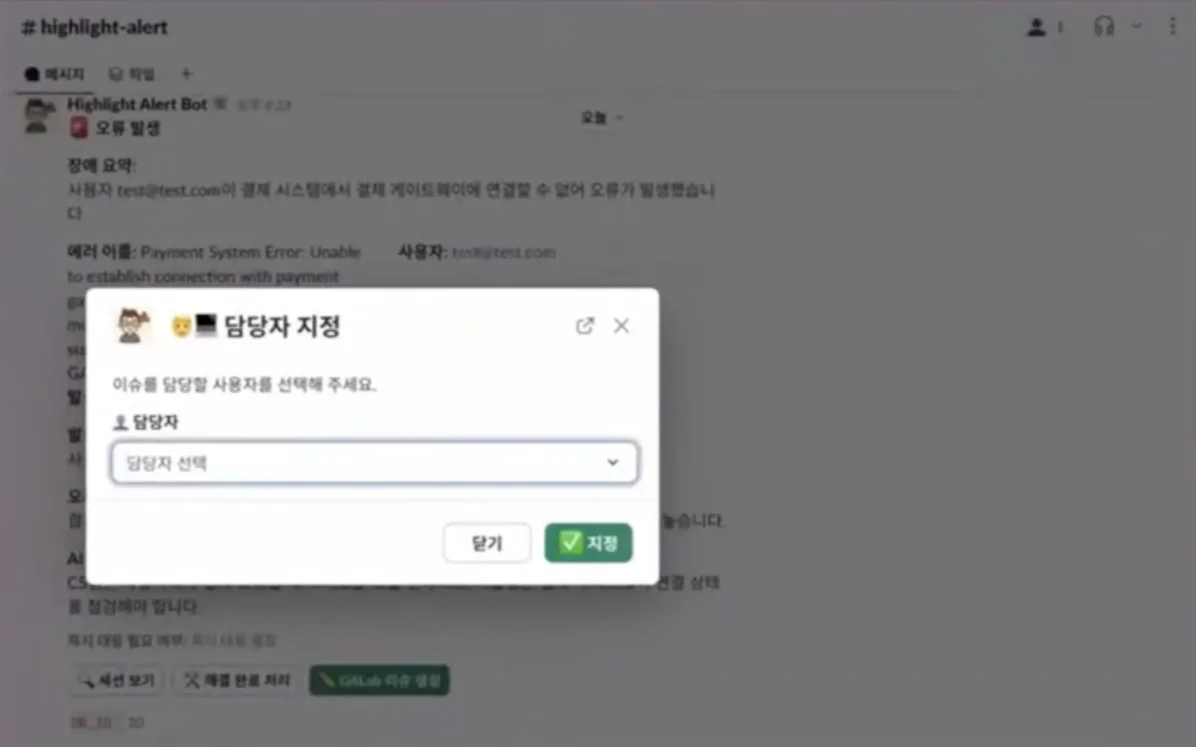
Slack에 보낸 오류 메시지는 장애 요약, 에러 이름, 사용자, 발생 횟수, 위험도/영향도, 발생 전 사용자 행동 추정, 오류 추정 원인, AI 권장 조치로 상세하게 구성했습니다.
아울러 오류 메시지 하단에는 ‘세션 보기’, ‘해결 완료 처리’, ‘GitLab 이슈 생성’ 버튼이 포함됐는데요. ‘세션 보기’ 버튼을 누르면 Hightlight에 들어가 대시보드를 보고 오류 상황을 면밀히 파악할 수 있고요. 또 ‘GitLab 이슈 생성’ 버튼을 클릭하면 Slack에서 GitLab 이슈를 생성하고, 담당자를 할당할 수 있죠. Slack 오류 메시지에 담긴 내용은 GitLab 이슈에 자동 등록됩니다.
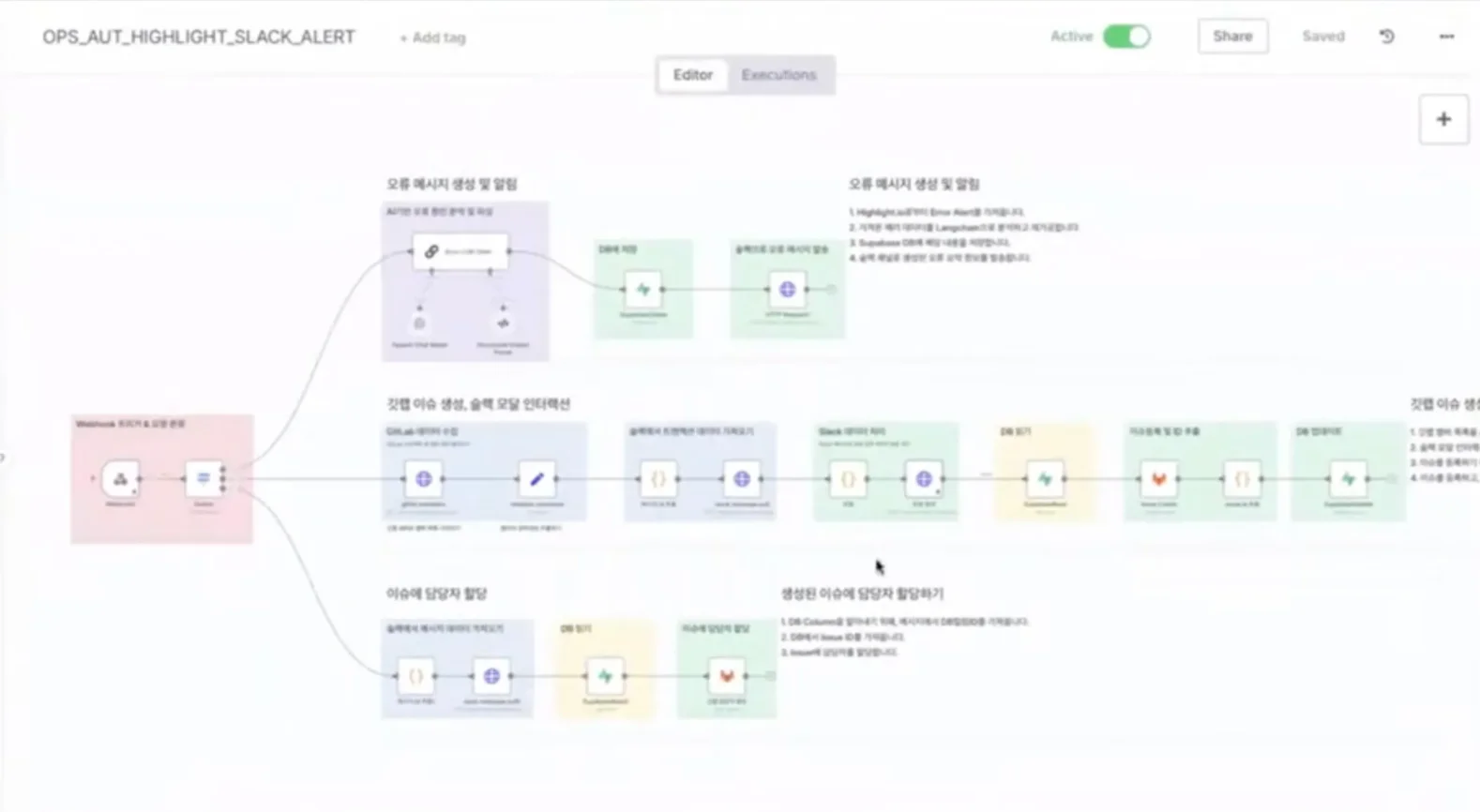
Jhin은 오류 유형을 자동 분류할 때, 에러 메시지의 정확성과 구체화의 중요성을 강조했습니다. 그는 “에러 메시지가 정확하고 세분화될수록 사용자가 겪은 오류를 쉽게 파악할 수 있다”며 “에러 처리 개발이 견고하면, AI가 오류를 분류하기에도 수월할 것”이라고 말했습니다.
한편, 네 번째 세션에서도 기술적 깊이가 돋보이는 질문이 쏟아졌는데요. n8n에서 활용할 수 있는 서드 파티 도구, LLM 출력의 포맷 검증과 프롬프트 재전송 동작 수행, Javascript로 ID, 사용자 이름을 가져올 때 사용한 노드 등 질문이 나왔습니다.
아울러 “여러 기능을 사용하는 예제를 볼 수 있는 데모라 너무 좋다”는 호평도 이어졌고요.
Jhin의 발표는 CS 담당자가 고객의 장애 상황을 빠르게 파악하고 해결하는 데 도움이 되는 실질적인 자동화 사례였습니다. 특히 AI 분석을 접목해 오류 원인을 신속히 파악하는 점이 인상적이었는데요. 이를 토대로 조직의 장애 대응 역량을 체계적으로 강화할 수 있을 거로 기대됩니다.
🎤 모든 세션 종료 후, 전체 Q&A 시간이 이어졌습니다.
발표자들은 사전 접수된 질문과 실시간 채팅에 올라온 질문에 적극적으로 답변했는데요. 💬
다양한 서드 파티 도구와 n8n 연동 방법, 반복 업무 자동화 아이디어, n8n 워크플로의 MCP 형식 A2A 활용 방법 등 실무 밀착형 질문이 잇따랐습니다.
🎁 드디어 마지막 순서, 경품 추첨 이벤트 시간이었는데요. 🥳
이번에는 발표자들이 실시간 채팅과 Q&A에 가장 활발히 참여한 세 분을 직접 선정했습니다.
🎊 당첨자분들에게는 **‘배달의민족 상품권 1만원권’**을 드렸고요. 이로써 n8n Korea 온라인 밋업 #3의 공식 일정을 마무리했습니다.
📌 이번 밋업은 2025년 상반기 마지막 밋업이었습니다.
n8n Korea 밋업은 잠시 휴식기를 가진 뒤, 하반기에 더욱 새롭고 완성도 높은 콘텐츠로 돌아올 예정입니다. 인포그랩은 전략적 재정비 기간에 밋업의 품질과 가치를 한층 더 강화할 계획입니다. 🔧
이번 참가 신청 단계에서 제안해 주신 다양한 자동화 아이디어는 기술 검토를 거쳐 다음 밋업 때 구현 사례를 공유하고자 합니다.
🎥 밋업 다시 보기는 어디서?
👉 이번 밋업 전체 영상은 n8n Korea - 워크플로 자동화 커뮤니티 멤버에게 단독 공개할 예정입니다.
아직 가입하지 않으셨다면, 지금 참여해 보세요!
➡️ 커뮤니티 바로 가기
🚀 인포그랩의 n8n 자동화 서비스는 현재 진행형입니다.
밋업은 잠시 쉬어가지만, 인포그랩의 n8n 자동화 지원 서비스는 항상 운영 중입니다.
n8n 도입, 워크플로 개발, 기술 컨설팅이 필요하시면 언제든지 문의해 주세요! 😊
📮 자동화 문의하기
다시 한번 함께해 주신 모든 분께 감사드리며,
하반기 밋업에 더욱 강력한 n8n 자동화 사례로 찾아뵙겠습니다.
고맙습니다!
📚 함께 보면 좋은 콘텐츠
DevOps 자동화의 핵심 도구 n8n! 인포그랩과 함께 더 빠르게, 효율적으로 도입하세요.
![[현장 스케치] 서울메타위크 2026 METACON에 인포그랩이 연사로 참여했습니다!](/img/event/thumbnail/event_399a508f-9223-8002-bedb-de0d4f42e538_0.7861d6d0.webp)
![[현장 스케치] 국내 소프트웨어 기업 H사 n8n 소개 세션 후기!](/img/event/thumbnail/event_321a508f-9223-8072-9241-d916a8a2ca83_0.6488236c.webp)
![[현장 스케치] “GitLab Korea #21 밋업 - AI 에이전트 기반 워크플로 + 데이터 기반 DevOps 가치 증명” 후기!](/img/event/thumbnail/event_310a508f-9223-8051-839e-e359599c1c45_21.b6ea0a07.webp)