n8n 기반 DevOps·AI 콘텐츠 자동 수집·요약 실전 가이드
 Andy
Andy
안녕하세요. 인포그랩에서 백엔드 엔지니어로 근무하는 Andy입니다. 오늘날 IT 업계의 변화 속도는 매우 가파릅니다. 최근에는 AI 발전이 가속화되면서 관련 소식이 연일 쏟아지고 있죠. DevOps·소프트웨어 엔지니어들은 이러한 변화에 빠르게 대응하기 위해 최신 정보를 꾸준히 접하려 노력합니다. 여러분은 평소 IT 소식을 어떻게 접하고 계신가요?
인포그랩도 엔지니어들의 이러한 수요에 대응하기 위해 공식 뉴스레터 ‘인포레터’로 DevOps, AI, 자동화 분야의 최신 동향을 전하고 있습니다. 국내외 IT 기업, 커뮤니티의 기술 블로그와 뉴스레터를 살펴보며 엔지니어들에게 유용한 콘텐츠를 엄선하고요. 이를 ‘추천 DevOps 콘텐츠’ 코너에서 소개하죠.
처음에는 사람이 콘텐츠를 직접 수집했습니다. 그러나 수십 개의 채널을 일일이 확인하려면 시간과 노력이 많이 들었습니다. 좋은 콘텐츠를 놓칠 때도 있었죠.
저는 이 문제를 해결하기 위해 n8n 기반의 콘텐츠 자동 수집, 요약 시스템을 구축했습니다. 이 시스템은 주 3회 40여 개의 채널을 자동으로 모니터링하고요. DevOps, AI, 자동화 관련 콘텐츠를 선별해 한국어로 요약합니다.
이 글에서는 콘텐츠 자동 수집, 요약 시스템의 아키텍처와 핵심 구현 방법, 개발 과정에서 마주한 문제점과 해결 방안을 공유하겠습니다.
시스템 구조
이 시스템은 두 개의 독립적인 워크플로로 구성했습니다. 바로 콘텐츠 수집 워크플로와 콘텐츠 요약 워크플로입니다. 수집과 요약을 분리한 덕분에 워크플로를 훨씬 더 효율적으로 관리할 수 있었습니다.
제가 느낀 워크플로 분리 운영의 구체적인 장점은 이렇습니다. 첫째, 각 워크플로를 독립적으로 테스트하고 수정할 수 있습니다. 둘째, 한 워크플로에서 문제가 생겨도 다른 워크플로는 정상 작동합니다. 셋째, Notion 데이터베이스(DB)가 자연스럽게 두 워크플로의 버퍼 역할을 수행해 안정적으로 운영할 수 있습니다.
각 워크플로의 역할과 실행 주기는 다음과 같습니다.
| 워크플로 | 역할 | 실행 주기 |
|---|---|---|
| 콘텐츠 수집 | 웹에서 DevOps, AI, 자동화 관련 콘텐츠를 크롤링하고 Notion DB에 저장 | 주 3회 (월/수/토) |
| 콘텐츠 요약 | 수집된 콘텐츠를 AI로 요약해 Notion 페이지에 추가 | 주 3회 (콘텐츠 수집 후 실행) |
워크플로 실행 주기를 주 3회로 정한 이유는 두 가지입니다. 첫째, 주 1회는 너무 느려서 최신 동향을 놓칠 위험이 있고요. 둘째, 매일 실행하면 동일한 콘텐츠가 중복으로 수집될 수 있습니다. 워크플로 실행 주기를 월/수/토로 분산하면, 일주일간 발행되는 신규 콘텐츠를 적절히 수집할 수 있었습니다.
기술 스택은 최대한 간소하게 유지했습니다. n8n을 워크플로 오케스트레이션 도구로 사용했고요. Claude Sonnet 4로 콘텐츠를 분석, 필터링했습니다. 또 Firecrawl로 웹 스크래핑을 처리했고요. Notion을 수집된 데이터의 저장소로 활용했죠. 실행 결과는 Slack으로 전송해 실시간으로 모니터링할 수 있도록 구축했습니다.
이제 각 워크플로의 구체적인 동작 방식을 살펴보겠습니다.
워크플로 1: 웹 콘텐츠 수집
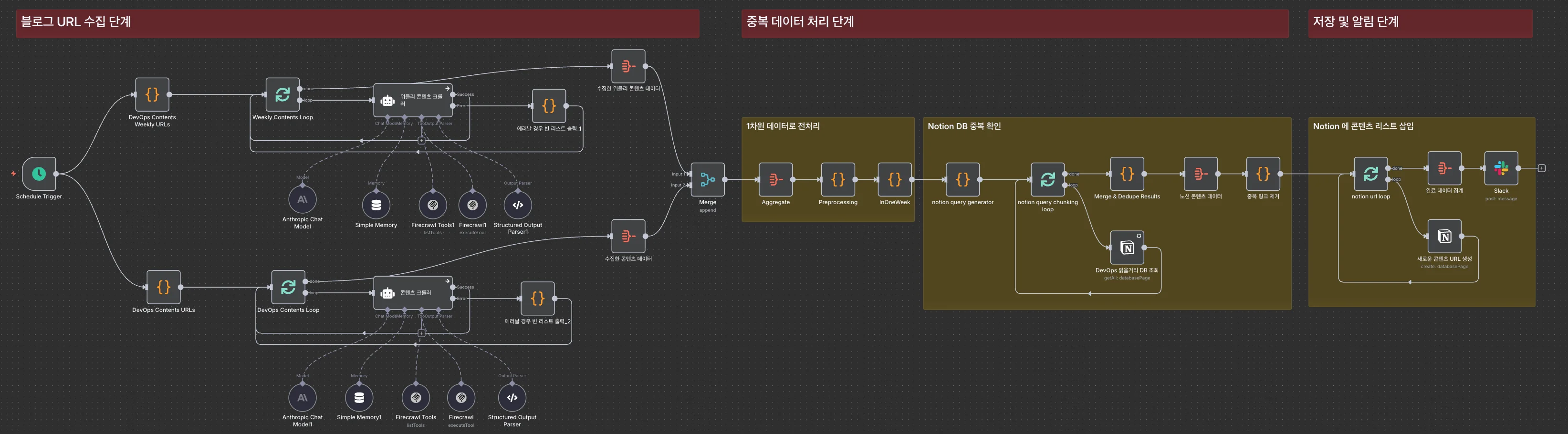
콘텐츠 수집 워크플로는 40여 개의 기술 블로그와 뉴스레터에서 DevOps, AI, 자동화 관련 콘텐츠만 선별해 Notion에 저장합니다.
여기서 핵심 과제는 두 가지였습니다. 첫째, 다양한 구조의 웹사이트에서 효과적으로 정보를 추출하는 것입니다. 기술 블로그와 뉴스레터는 콘텐츠 구조가 완전히 달라서 접근 방식을 차별화해야 합니다. 둘째, 불필요한 중복을 방지하면서 새로운 콘텐츠만 수집하는 것입니다.
이 워크플로는 다음 세 단계로 문제를 해결합니다.
- Step 1. 콘텐츠 URL 수집: 지정된 URL에서 AI와 Firecrawl MCP를 활용해 DevOps, AI, 자동화 관련 콘텐츠 URL을 수집합니다.
- Step 2. 데이터 전처리: 수집 기간을 확인하고, Notion DB에 이미 존재하는 URL을 필터링합니다.
- Step 3. 저장, 알림: 최종 선별된 콘텐츠를 Notion에 저장하고, Slack으로 완료 알림을 전송합니다.
Step 1. 콘텐츠 URL 수집
이 단계에서는 두 가지 유형의 URL을 수집합니다.
- Daily URLs: GitLab 블로그, AWS 블로그와 같은 기술 블로그 사이트
- Weekly URLs: KubeWeekly, SRE Weekly와 같은 뉴스레터 사이트
이 두 가지 유형을 구분해서 처리하는 이유는 콘텐츠 구조가 다르기 때문입니다.
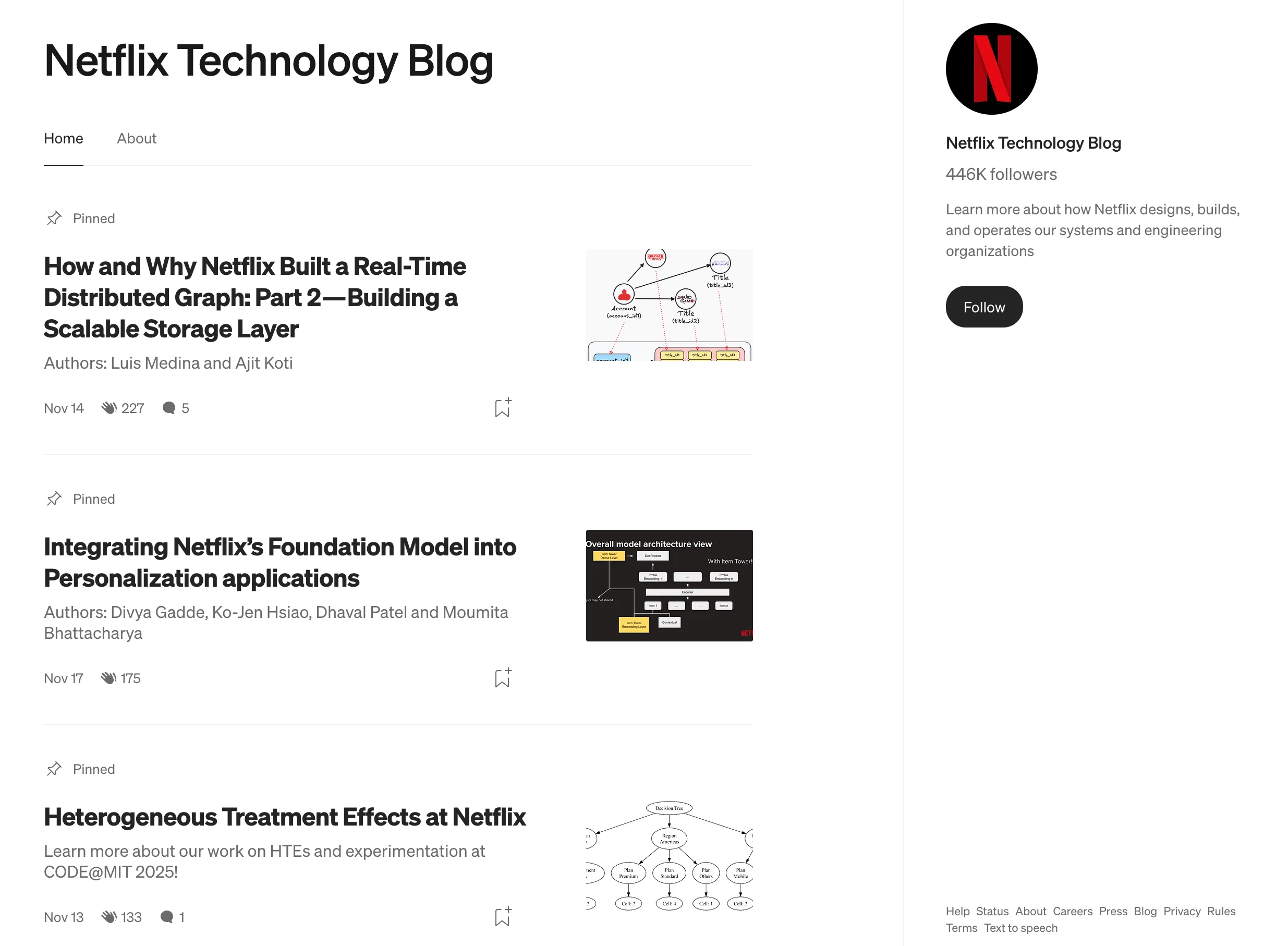
기술 블로그는 대개 홈 역할을 하는 한 페이지에 여러 글의 제목과 링크가 목록 형태로 나열돼 있습니다. 예를 들어, 넷플릭스 블로그를 방문하면 그 페이지 자체에서 각 글의 제목과 URL을 바로 추출할 수 있습니다. 즉, 목록 페이지 하나를 크롤링하면 여러 개별 글의 정보를 한 번에 수집할 수 있는 구조입니다.
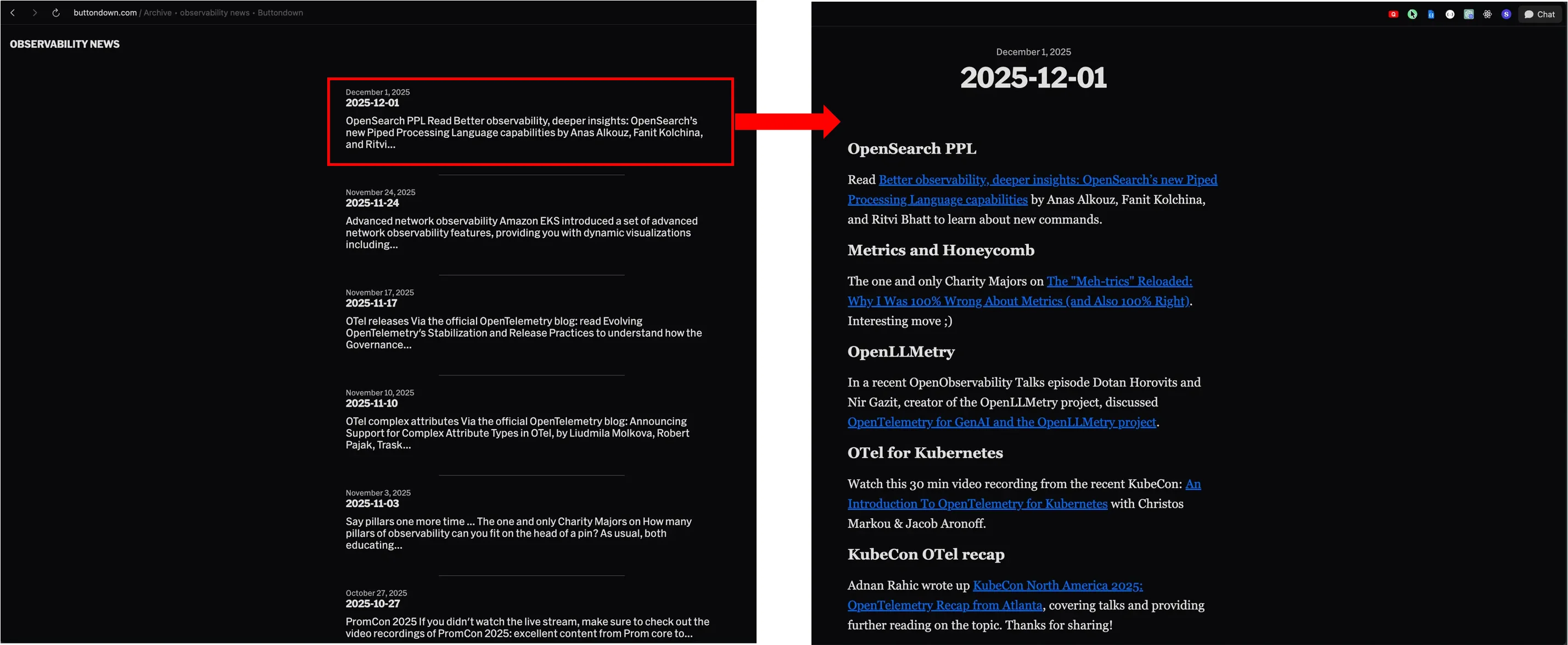
반면에 뉴스레터는 이중 구조로 돼 있습니다. Observability News와 같은 뉴스레터는 특정 회차의 뉴스레터 페이지 안에 여러 외부 콘텐츠로 연결되는 링크들을 포함합니다. 즉, 뉴스레터 홈페이지 → 특정 회차 페이지 → 개별 콘텐츠 링크라는 계층 구조로 돼 있죠.
뉴스레터 홈페이지를 방문하면 그 페이지 자체에서 개별 콘텐츠의 제목과 URL을 바로 추출할 수 없습니다. 홈페이지에 나열된 특정 회차의 뉴스레터 페이지에 들어가야 그 페이지에 포함된 개별 링크를 수집할 수 있죠. 따라서 뉴스레터를 크롤링할 때는 뉴스레터 홈페이지가 아닌 특정 회차 뉴스레터 페이지 내부의 링크를 하나씩 추출해야 합니다. 이러한 구조 때문에 처음에는 단순히 뉴스레터 홈페이지를 크롤링하면 실제 콘텐츠가 아닌 특정 회차의 뉴스레터 페이지 URL만 반복적으로 수집되는 문제가 발생했습니다.
이러한 구조적 차이 때문에 저는 콘텐츠를 수집하는 AI Agent에 다음 지침을 추가했습니다. 특정 회차의 뉴스레터 페이지 자체를 하나의 항목으로 반환하는 게 아니라, 그 페이지 안의 개별 링크를 각각의 별도 항목으로 추출하도록 명확히 지시했죠.
중요: KubeWeekly와 같은 주간 뉴스레터 페이지를 처리할 때는 반드시 다음 단계를 따르세요:
- 절대로 뉴스레터 자체만 반환하지 마세요
- 뉴스레터 페이지에서 DevOps/SRE 관련된 모든 개별 링크를 찾으세요
- 각 개별 링크마다 별도의 항목으로 JSON 배열에 추가하세요
- 뉴스레터 페이지 URL이 아닌 실제 개별 기사 URL을 사용하세요
이 지침 덕분에 매주 같은 뉴스레터 페이지 URL이 중복으로 수집되는 문제를 방지할 수 있었습니다.
AI Agent 구성
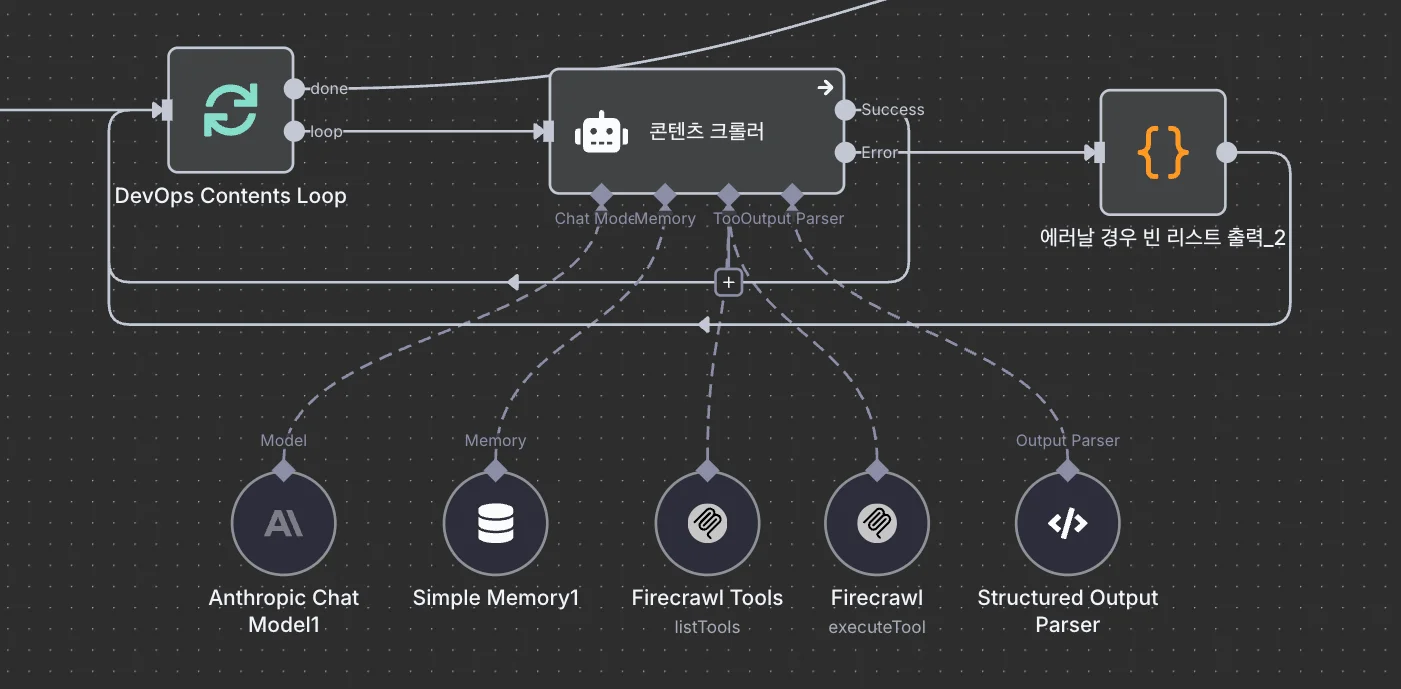
AI Agent는 콘텐츠 URL 수집과 필터링을 수행하는 핵심 컴포넌트입니다. 이는 웹페이지를 크롤링하고, 콘텐츠를 분석하며, 프롬프트에 따라 결과를 반환하는 역할을 담당합니다. 콘텐츠 수집 워크플로에서 AI Agent는 세 가지 주요 구성 요소로 이뤄졌습니다.
| 컴포넌트 | 역할 |
|---|---|
| Claude Sonnet 4 | 콘텐츠 분석, 필터링 |
| Firecrawl MCP | 웹페이지 스크래핑 |
| Output Parser | JSON 형식으로 결과 정규화 |
특히 Firecrawl MCP와 Output Parser를 선택한 배경에는 워크플로 구축 과정에서 마주한 현실적인 문제들이 영향을 미쳤습니다. 그 내용은 다음과 같습니다.
-
문제 1: 웹사이트 접근 차단 (Firecrawl MCP로 해결)
처음에는 n8n의 기본 HTTP Request 노드로 웹페이지를 가져오려 했습니다. 이는 가장 단순하고 직관적인 방법이었죠. URL을 입력하면 해당 페이지의 HTML을 가져오는 방식입니다. 그러나 실제로 시도해 보니 많은 사이트에서 접근이 차단되는 문제가 있었습니다.
여러 웹사이트가 Cloudflare와 같은 보안 서비스를 사용해 자동화된 봇의 접근을 차단했는데요. Cloudflare는 웹사이트를 DDoS 공격이나 악의적인 크롤링에서 보호하는 서비스입니다. 따라서 일반적인 HTTP 요청은 봇으로 판단돼 막히죠. 이 차단을 우회하지 않으면 많은 기술 블로그와 뉴스레터에서 콘텐츠를 수집할 수 없었습니다.
저는 이 문제를 해결하기 위해 Firecrawl MCP를 사용했습니다. Firecrawl의 핵심 장점은 두 가지입니다.
- 고급 스크래핑 기술을 제공합니다. Firecrawl은 JavaScript 렌더링과 동적 콘텐츠 처리를 지원하며, 기본적인 봇 차단 시스템을 우회할 수 있습니다. 다만, Cloudflare와 같은 고급 봇 차단 시스템은 지속적으로 발전하고 있어, 모든 사이트에서 우회가 항상 성공하는 건 아닙니다.
- MCP로 AI Agent와 자연스럽게 연동됩니다. MCP는 AI가 외부 도구를 호출할 수 있게 해주는 프로토콜입니다. Firecrawl이 MCP를 지원하므로 AI Agent가 필요할 때 직접 웹 스크래핑 도구를 호출할 수 있습니다. 별도의 복잡한 통합 작업 없이 AI가 스스로 웹페이지를 가져와 분석할 수 있죠.
저는 이러한 장점을 고려해 n8n-node-mcp 패키지에 Firecrawl MCP를 설정해 AI Agent가 웹 스크래핑 도구를 호출하도록 설정했습니다.
-
문제 2: AI 응답 형식의 불일치 (Output Parser로 해결)
웹페이지를 성공적으로 가져와도 문제가 있었습니다. 바로 AI 응답 형식의 일관성이었죠. AI는 같은 프롬프트를 받아도 매번 조금씩 다른 형식으로 응답합니다. 예를 들어, 어떤 때는 제목과 URL을 JSON 배열로 반환하고, 어떤 때는 마크다운 목록으로 반환하거나, 일반 텍스트 설명과 함께 섞어 반환할 수 있죠.
이렇게 응답 형식이 매번 달라지면 결과를 처리하는 코드를 작성하기가 어렵습니다. JSON으로 올 때도 있고, 텍스트로 올 때도 있다면, 모든 상황을 대비한 복잡한 파싱 로직을 만들어야 하기 때문입니다. 게다가 AI가 새로운 형식으로 답변하기 시작하면 예상치 못한 오류가 발생할 수 있습니다.
저는 이 문제를 해결하기 위해 n8n의 Output Parser를 사용했습니다. Output Parser는 AI에게 원하는 JSON 스키마를 프롬프트에 포함해 전달하고, 응답받은 후 파싱하는 도구입니다. AI가 반환해야 하는 데이터의 구조를 명확히 지시하면, AI는 대부분 그 구조를 따르도록 유도됩니다. 다만 프롬프트 기반 방식이므로, 마크다운 코드 블록으로 JSON을 감싸거나 예상치 못한 형식으로 반환하는 일이 생길 수 있습니다.
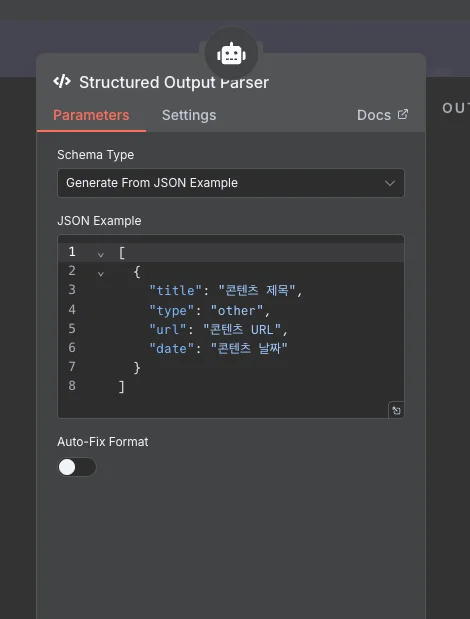
예를 들어, “제목은 title이라는 필드에, URL은 url이라는 필드에, 날짜는 date라는 필드에 넣어라”고 스키마를 정의하면, AI는 일반적으로 이 세 가지 필드를 가진 JSON 객체를 반환합니다. Output Parser는 이 응답을 파싱해 정규화된 형식으로 제공합니다.
이로써 AI 응답을 처리하는 코드가 훨씬 더 단순해졌고요. 복잡한 조건문이나 예외 처리를 줄이고 일관된 구조의 JSON을 받아 바로 다음 단계로 전달할 수 있었습니다. AI 응답의 일관성이 크게 향상되면서 전체 워크플로의 안정성도 개선됐죠.
Step 2. 데이터 전처리
콘텐츠 URL을 수집한 다음, 무분별한 데이터 적재를 방지하기 위해 두 가지 검증 절차를 거칩니다.
-
게시 날짜 검증
프롬프트에는 워크플로 실행일 기준 최근 일주일 이내 발행된 콘텐츠만 수집하도록 지시했습니다. 그러나 AI가 이 날짜 조건을 정확히 파악하지 못해 그 이전에 발행된 콘텐츠를 가져올 때가 있었습니다.
저는 이 문제를 해결하기 위해 Code 노드를 활용했습니다. 수집된 데이터의 발행일을 파싱해 워크플로 실행 시점에서 일주일 이내에 발행된 콘텐츠만 남기도록 설정했습니다. 이로써 오래된 콘텐츠가 수집되는 걸 방지할 수 있었습니다.
-
중복 URL 필터링
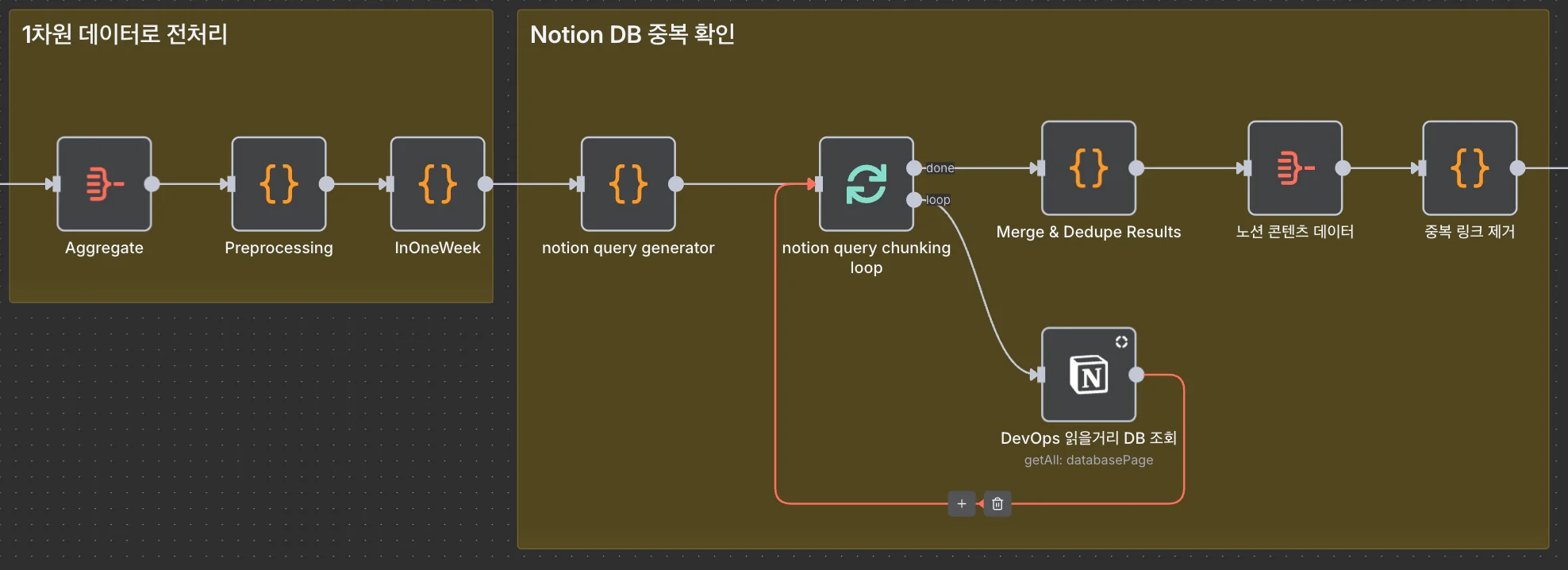
수집된 콘텐츠가 Notion DB에 이미 존재하는지 확인하는 과정도 필요했습니다. 저는 새로 수집한 콘텐츠 URL 목록을 기반으로 Notion API 필터 쿼리를 동적으로 생성해 ‘해당 URL이 DB에 존재하는지’ 조회하는 방식을 사용했습니다. 조회 결과로 반환된 항목은 이미 저장된 콘텐츠이므로, 이를 수집 목록에서 제외하는 필터링 로직을 Code 노드로 작성해 중복 저장을 방지했습니다.
이때 한 가지 제약이 있었습니다. Notion API의 필터 쿼리는 한 번에 최대 100개의 조건만 포함할 수 있습니다. 수집된 URL이 100개를 초과하면, 쿼리를 여러 개로 분할(chunking)해야 합니다. 저는 Loop Over Items 노드로 분할된 쿼리를 순차적으로 실행하고, 모든 중복 URL을 확인하도록 구현했습니다.
이러한 과정을 거쳐 중복 콘텐츠 수집을 최소화하고, Notion DB를 깔끔하게 유지할 수 있었습니다.
Step 3. Notion 저장, Slack 알림
데이터 전처리가 완료되면, 최종적으로 수집한 데이터를 Notion DB에 적재하고, 수집 결과를 Slack에 메시지로 전송합니다. 이 단계에서는 n8n의 기본 노드들을 활용해 데이터 저장과 Slack 알림 로직을 구현할 수 있습니다.
Notion DB 데이터 저장
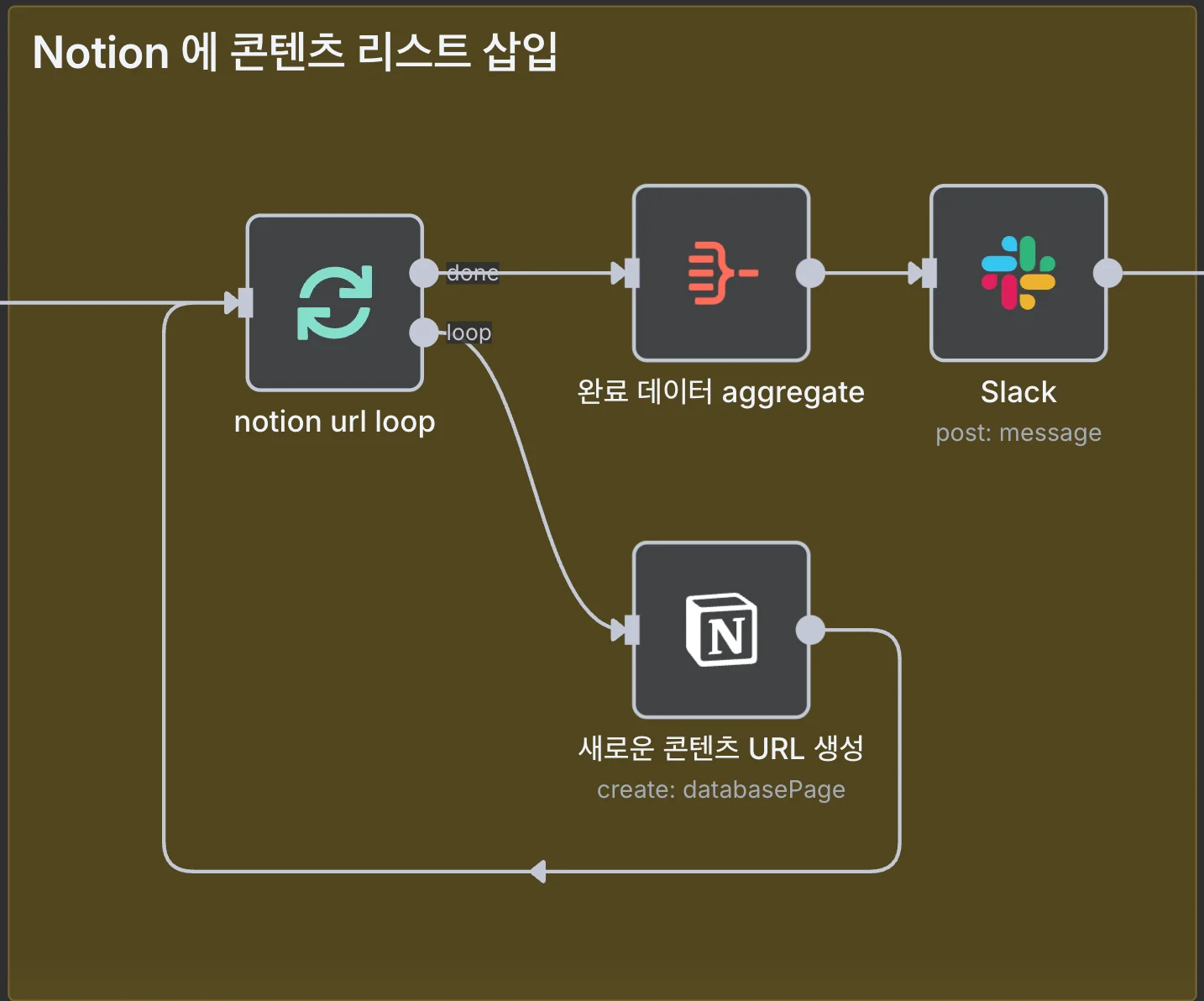
Notion DB에 데이터를 저장할 때는 Loop Over Items 노드의 loop 출력이 Notion 노드로 연결되도록 설정했습니다. 이는 필터링된 각 콘텐츠 항목을 Notion DB에 하나씩 삽입하는 구조죠.
Notion DB에는 다음과 같은 속성을 정의하고, 수집한 데이터를 매핑했습니다.
| 수집 데이터 | Notion DB 속성 | 속성 타입 | 설명 |
|---|---|---|---|
| 콘텐츠 제목 | Title | Title | 노션 페이지의 제목으로 표시 |
| 콘텐츠 URL | Link | URL | 원본 콘텐츠 링크 |
Slack 알림 전송

Notion DB에 데이터 저장이 완료되면, Loop Over Items 노드의 done 출력이 활성화됩니다. 이는 모든 항목의 처리가 완료됐다는 신호입니다. 이때 Aggregate 노드와 Slack 노드가 실행됩니다.
-
Aggregate 노드
이 노드는 Loop Over Items에서 처리된 모든 항목을 하나의 배열로 모아주는 역할을 합니다. 개별적으로 처리된 항목을 다시 집계해야 Slack 메시지에서 ‘총 몇 개의 콘텐츠를 수집했는지’와 같은 통계 정보를 표시할 수 있습니다.
-
Slack 노드
워크플로 실행 결과를 Slack의 특정 채널에 메시지로 전송합니다. 저는 Slack 메시지에 다음 정보를 담아 콘텐츠 수집 결과를 한눈에 파악하도록 구성했습니다.
- Slack 메시지 구성 요소
- 워크플로 실행 날짜
- 수집된 콘텐츠 개수
- Notion DB 링크
이렇게 구성하면 팀원들이 Slack에서 콘텐츠 수집 결과를 바로 확인하고, 링크를 클릭해 Notion DB에서 새로운 콘텐츠를 빠르게 확인할 수 있습니다.
- Slack 메시지 구성 요소
전역 에러 모니터링
저는 워크플로에서 발생하는 에러를 효과적으로 관리하기 위해 Error Trigger 노드를 활용한 전역 에러 처리 워크플로도 구축했습니다. 이로써 여러 워크플로에 에러가 발생할 때마다 중앙에서 모니터링하고, Slack으로 즉시 알림을 받아 빠르게 대응할 수 있었습니다.
배경: 노드별 에러 처리의 한계
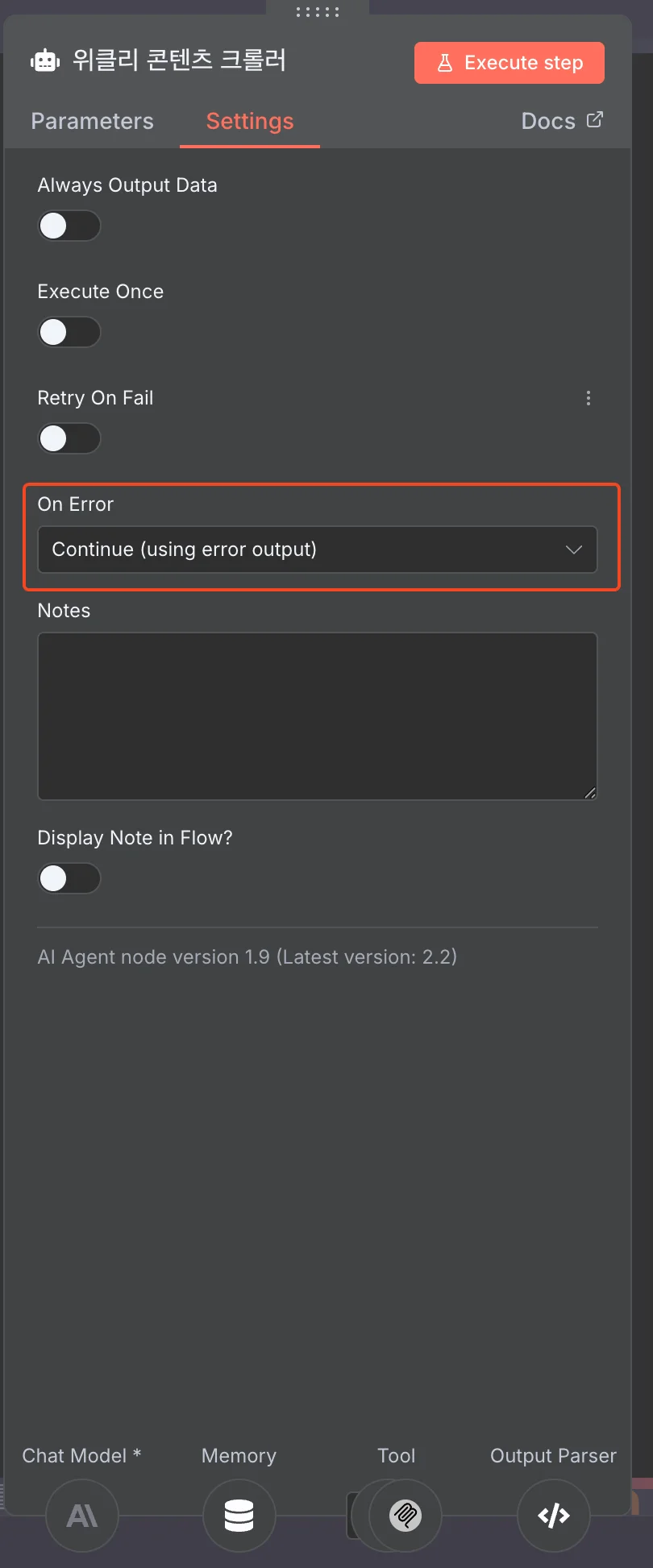
n8n에서는 각 노드의 Setting > On Error 필드로 노드별 에러 처리를 커스터마이징할 수 있습니다. 저는 위 로직에서 콘텐츠 크롤링 에이전트 설정으로 Continue (using error output) 값을 넣어, 에러가 발생하면 제가 작성한 Code 노드로 전달되도록 설정했습니다. 그러나 노드마다 에러 처리를 작성하면 워크플로가 복잡해지고 설정이 번거로워지는 문제가 있었죠.
구현: Error Trigger 기반 전역 에러 처리 워크플로
저는 전역 에러 처리 워크플로를 구축해 이 문제를 해결했습니다.
-
에러 처리 워크플로 생성
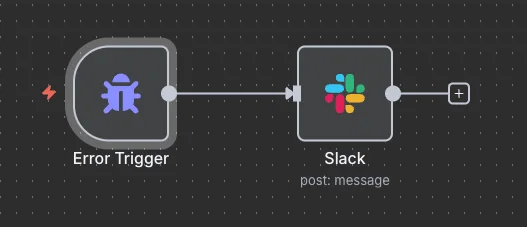
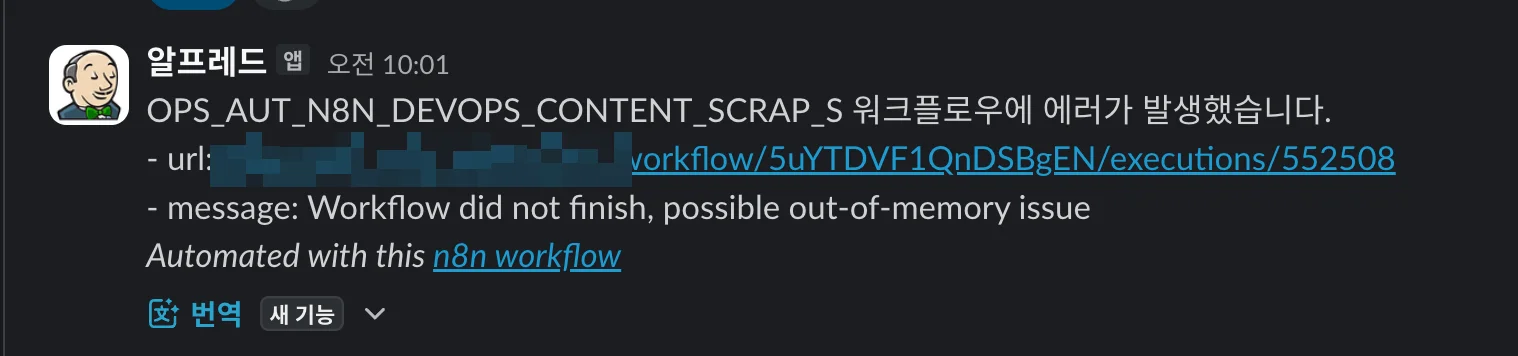
n8n의 Error Trigger 노드를 사용하면, 워크플로 실행이 실패할 때 에러를 중앙에서 탐지하고 처리할 수 있습니다. 저는 이 노드로 에러 발생 시 Slack으로 알림을 보내는 워크플로를 생성했습니다. 워크플로는 다음과 같이 구성됐습니다.
- Error Trigger: 워크플로 실행 실패 시 자동으로 트리거됩니다.
- Slack 알림: 에러가 발생한 워크플로 이름, 실행 URL, 구체적인 에러 메시지를 전송합니다.
-
워크플로에 에러 처리 워크플로 연결
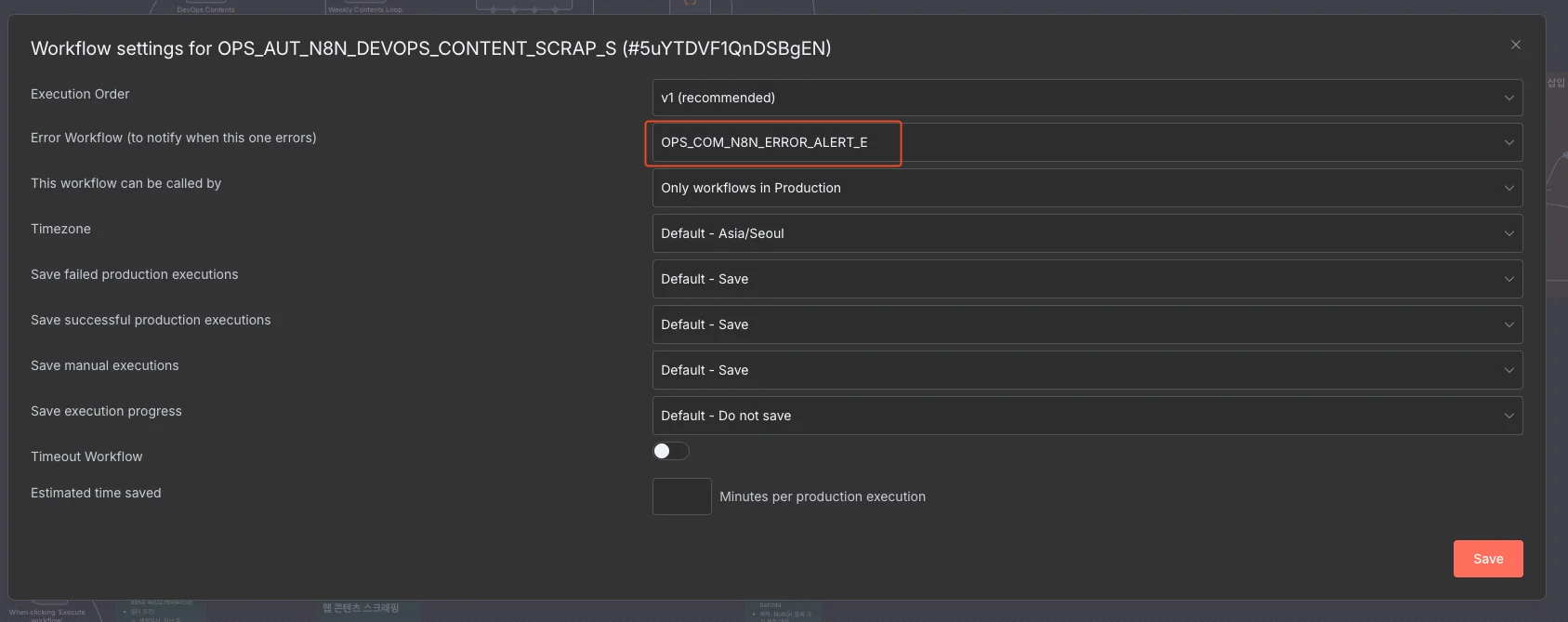
에러 처리 워크플로는 다른 워크플로에도 적용했습니다. 이 워크플로를 사용할 대상 워크플로의
Settings > Error Workflow항목에서 에러 처리 워크플로를 설정했죠.그 결과, 해당 워크플로에서 에러가 발생할 때마다 에러 처리 워크플로가 자동으로 실행되고요. 전송받은 Slack 알림 메시지의 링크를 클릭해 바로 디버깅할 수 있습니다.
워크플로 2: 콘텐츠 요약
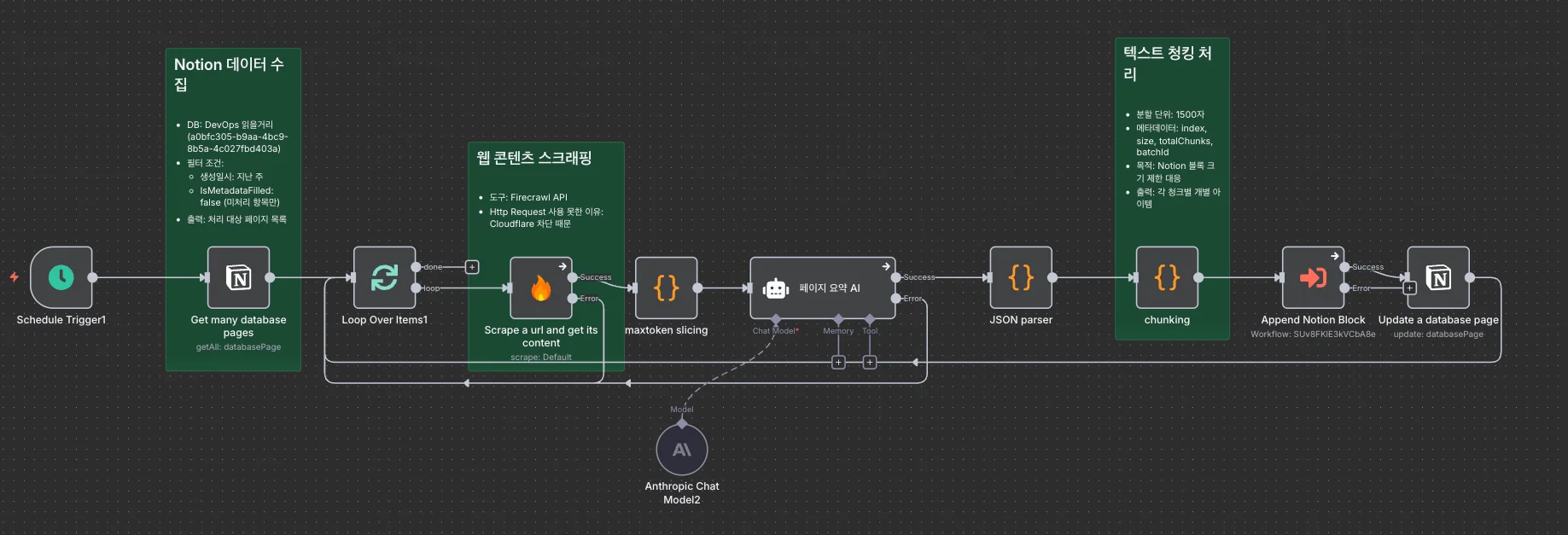
콘텐츠 수집 자동화만으로는 부족했습니다. 영문 기술 블로그를 일일이 읽으려면 시간이 오래 걸리죠. 저는 콘텐츠 수집 워크플로에서 한발 더 나아가 수집된 콘텐츠를 한국어로 요약하는 워크플로도 구축했습니다. 이 워크플로는 다음 4단계로 구성됐습니다.
- Step 1. Notion DB에서
IsMetadataFilled값이 False인 페이지만 가져옵니다. - Step 2. Loop 노드를 통해 각 URL을 Firecrawl 노드로 크롤링합니다.
- Step 3. 크롤링한 데이터를 LLM으로 요약(한국어)하고, 작성자를 추출합니다.
- Step 4. 해당 Notion 페이지에 메타데이터와 본문을 업데이트합니다.
이 워크플로의 동작 방식은 단순합니다. 그러나 저는 구축 과정에서 두 가지 난관에 부딪혔는데요. 이 장에서는 콘텐츠 요약 워크플로의 구축 방법보다 문제 해결 과정을 자세히 소개하려 합니다.
문제 1: Notion API 블록 크기 제한
AI가 생성한 요약문을 Notion 페이지에 저장할 때, 다음 문제에 직면했습니다.
- Notion API 제한사항: Notion API 공식 문서에 따르면, rich_text 블록은 최대 2,000자까지만 지원합니다. AI가 생성하는 요약문은 종종 이 제한을 쉽게 초과하므로, 텍스트를 여러 블록으로 분할해야 했습니다.
저는 Code Node로 요약문을 1,500자 단위로 분할해 이 문제를 해결했습니다. 2000자 제한보다 작은 크기로 나누면 안전하게 여유분을 확보할 수 있습니다.
// 1,500자 단위로 분할 (2,000자 제한에 여유분 확보)
const chunkSize = 1500;
const chunks = [];
for (let i = 0; i < fullText.length; i += chunkSize) {
const chunk = fullText.substring(i, i + chunkSize);
chunks.push({
text: chunk,
index: Math.floor(i / chunkSize) + 1,
totalChunks: Math.ceil(fullText.length / chunkSize),
notionUrl: notionPageUrl
});
}
문제 2: n8n의 중첩 루프 제한
분할된 데이터를 Notion DB에 저장하려면 이중 루프가 필요했습니다.
- 외부 루프: 각 콘텐츠를 순회합니다.
- 내부 루프: 각 콘텐츠의 청크를 순회합니다.
그러나 n8n의 Split In Batches 노드는 중첩 루프를 직접 지원하지 않습니다. 이때 Execute Workflow 노드로 서브 워크플로를 분리하는 것이 가장 권장되는 접근 방법입니다.
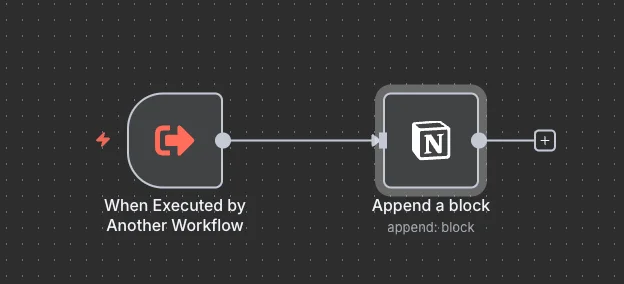
저는 Execute Workflow 노드를 활용한 서브 워크플로를 구축했습니다. 이 워크플로는 Notion 페이지 정보와 텍스트를 입력받아 페이지 본문에 내용을 등록합니다.
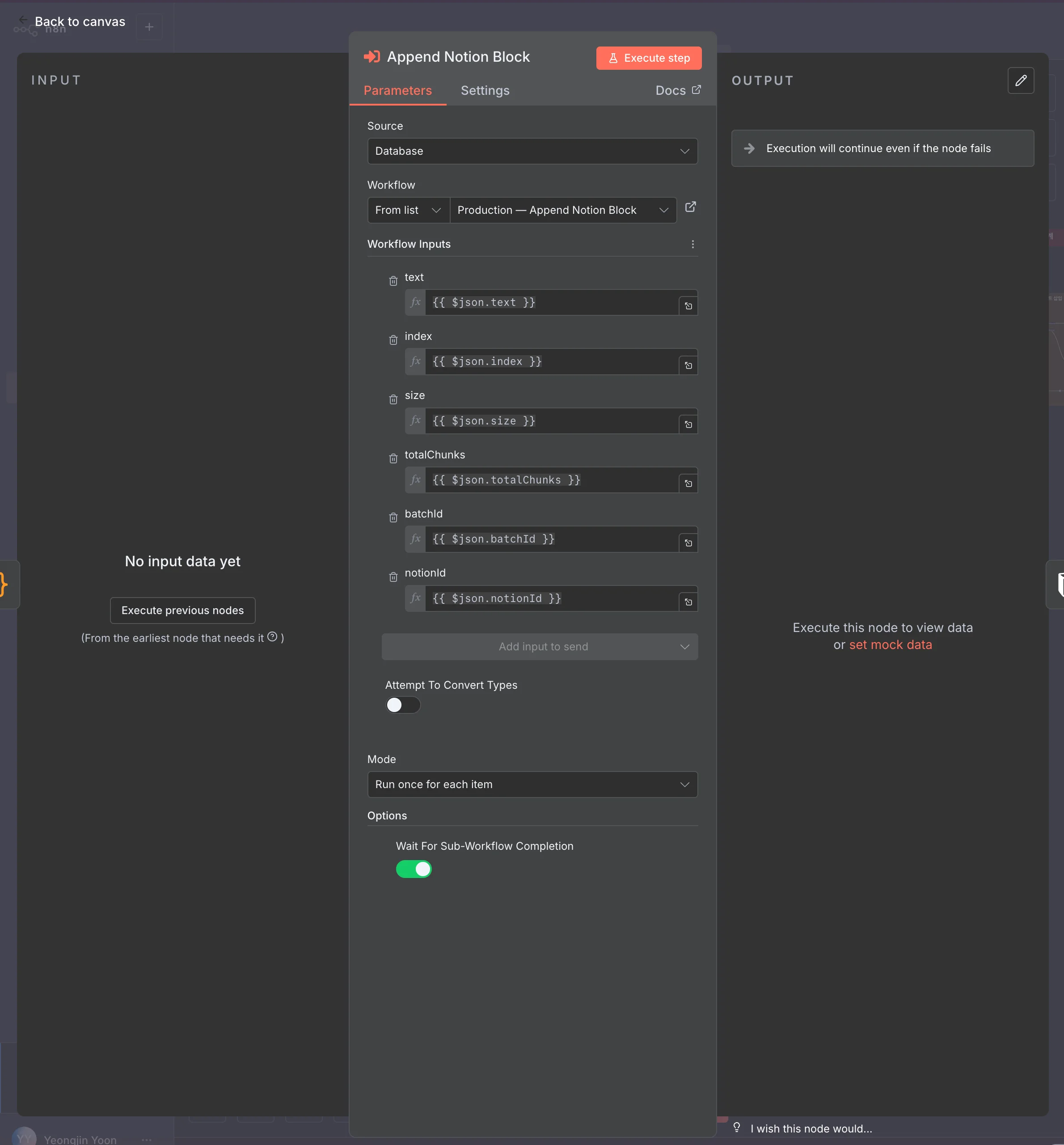
콘텐츠 요약 워크플로에서는 두 가지를 설정했습니다. 먼저 Mode를 Run once for each item으로 지정해 리스트의 각 항목을 개별적으로 처리하도록 했습니다. 아울러 Options에서 Wait For Sub-workflow Completion을 활성화해 순차적으로 본문을 작성하도록 구축했습니다.

그 결과, 위와 같이 Notion 페이지 본문에 콘텐츠 요약 내용이 자동으로 정확히 입력됐습니다.
맺음말
올해 콘텐츠 자동 수집, 요약 시스템을 구축하면서 n8n의 강점을 다시 한번 실감할 수 있었습니다. AI와 MCP를 활용한 웹 크롤링부터 Code 노드를 활용한 데이터 처리, Notion DB 저장과 Slack 알림 전송까지. 이 모든 것을 하나의 워크플로 안에서 통합해 구현할 수 있다는 점이 매력적이었습니다.
과거에는 이런 시스템을 구현하려면 별도의 크롤링 서버를 구축하고, 복잡한 코드를 직접 작성하고 관리해야 했습니다. 그러나 이제는 n8n이 제공하는 기본 노드(Core 노드)와 MCP로 외부 도구들을 퍼즐처럼 연결할 수 있죠. 이로써 복잡한 자동화 로직을 비교적 쉽게 구현할 수 있습니다.
여러분도 이 글에서 소개한 워크플로를 참고해 반복 작업을 자동화하고, 더 가치있는 일에 시간을 투자할 수 있기를 바랍니다.
참고 자료
- n8n 공식 기술 문서, https://docs.n8n.io/
- n8n Execute Sub-workflow 공식 문서, https://docs.n8n.io/integrations/builtin/core-nodes/n8n-nodes-base.executeworkflow/
- Notion API - Block Limits, https://developers.notion.com/reference/request-limits#limits-for-property-values
- Notion API - Block, https://developers.notion.com/reference/block
- Firecrawl 공식 홈페이지, https://firecrawl.dev/
- Firecrawl Stealth Mode 공식 문서, https://docs.firecrawl.dev/features/stealth-mode
- Firecrawl Proxy 공식 문서, https://docs.firecrawl.dev/features/proxies
n8n으로 비즈니스 워크플로를 완벽히 자동화하고 싶으신가요? 지금 인포그랩에 문의하세요!
사전 동의 없이 2차 가공 및 영리적인 이용을 금하며, 온·오프라인에 무단 전재 또는 유포할 수 없습니다.
Andy
Software Engineer
DevOps 도입이 필요하신가요?
인포그랩 전문가가 맞춤 을 도와드립니다.
관련 글

n8n과 GitLab으로 개발팀 스탠드업 자동화하기
n8n, GitLab API, OpenAI, Slack을 연동하면 개발팀 스탠드업 자동화 시스템을 구축할 수 있습니다. GitLab에서 전날 작업 내용을 수집하고, 데일리 스탠드업 보고서를 생성해 Slack에 공유하는 과정을 모두 자동화할 수 있죠. 이 글은 스탠드업 자동화 워크플로와 관련 기술 스택, 설계 원칙, 결과를 다뤘습니다.
2025년 5월 14일

인포그랩의 n8n 기반 Notion PDF 자동화 후기
백엔드 엔지니어 Andy는 n8n을 사용해 Notion 문서를 PDF로 자동 변환하는 워크플로를 구축했습니다. 그 결과, 반복적인 문서 작업을 자동화해 업무 생산성을 높이고, 문서 품질도 향상했습니다. 이 글은 n8n 자동화 워크플로 구축 과정과 Pandoc 실행용 커뮤니티 노드 개발 과정, 표 레이아웃 조정, PDF 표지와 메타 데이터 삽입 등 전처리 자동화 과정을 다뤘습니다.
2025년 4월 16일

n8n 실전 리뷰
n8n은 개발자가 반복 작업을 간소화하고, 생산성을 높일 수 있는 워크플로 자동화 도구입니다. 이는 간편하고 직관적인 디버깅, 기술 문서로 기능하며 재활용 가능한 워크플로, 코드 없는 통합 구현 등 장점이 있습니다. 이 글은 인포그랩 개발팀 리더가 지난 3개월 동안 경험한 n8n의 핵심 장점을 다뤘습니다.
2025년 3월 12일