Grafana Alloy로 로그·메트릭 통합 수집하기

안녕하세요. 인포그랩에서 DevOps 엔지니어로 일하는 Chad입니다. Grafana Labs가 2025년 2월 13일부로 Promtail을 장기 지원(LTS) 모드로 전환했습니다. Promtail은 Grafana Loki를 위한 로그 수집 에이전트로, 각 서버나 컨테이너에서 로그를 읽어 Loki로 전송합니다. LTS 모드로 전환되면서 Promtail의 신규 기능 개발은 종료됐으며, 보안 업데이트와 버그 수정만 지원되고 있습니다*.
대신 Grafana Labs는 Promtail 사용자에게 Grafana Alloy로 마이그레이션을 권장하고 있습니다. Alloy는 메트릭, 로그, 트레이스 등 주요 Observability 데이터를 통합 수집하는 범용 에이전트입니다. 이 도구는 OpenTelemetry Collector를 기반으로 한 Grafana Labs의 배포판으로, Promtail의 로그 수집 기능도 지원합니다.
저는 처음에 "Grafana Labs의 로그 수집 도구가 바뀐 건가?" 정도로 생각했습니다. 그러나 Alloy를 직접 사용해 보니 Promtail과 아키텍처 패러다임 자체가 다르고, 기능이 크게 확장돼 인상 깊었습니다.
이 글에서는 Promtail의 한계와 Alloy의 개선 방식을 살펴보려 합니다. 이어서 Alloy 첫인상과 Docker 환경에서 설치 방법, 로그·메트릭 수집 방법을 소개하고, Alloy 운영 시 유의 사항과 총평으로 글을 마무리하겠습니다. Promtail LTS 전환과 공식 지원 종료(EoL) 일정 때문에 마이그레이션을 고려 중인 분들에게 도움이 되는 내용입니다.
테스트 환경: 이 글에서는 Alloy가 Docker 컨테이너 로그를 수집하고 Prometheus 메트릭을 remote write로 전송하는 과정을 테스트했습니다.
- Alloy v1.9.2
- Prometheus v3.6.0
- Loki v3.5.6
- Grafana v12.2.0
- Docker 환경
*Promtail의 EoL 일정은 2026년 3월 2일로 예정
Promtail의 한계
Promtail은 Grafana Loki 생태계의 핵심 로그 수집 에이전트입니다. 각 서버나 컨테이너에 설치돼 로컬 로그 파일을 실시간으로 읽고, 라벨을 추가한 뒤 Loki로 전송합니다. Promtail은 Prometheus의 서비스 디스커버리 메커니즘을 차용해 Kubernetes 환경에서 서비스 디스커버리를 지원하고, relabel 규칙으로 메타데이터를 가공할 수 있습니다.
그러나 Promtail을 포함한 전통적인 Prometheus 관찰 스택에는 운영 측면에서 자주 지적되는 제약이 있습니다. 메트릭은 Prometheus가 각 타겟을 scrape 하는 pull 방식, 로그는 Promtail이 Loki로 전송하는 push 방식으로 동작하는 데서 비롯된 문제입니다. 이러한 이중 구조는 다음과 같은 문제를 일으킵니다.
전통적인 방식의 제약
- 복잡한 네트워크 구성: Prometheus 서버가 수십 ~ 수백 개의
/metrics엔드포인트에 접근 가능해야 하므로, 방화벽이나 NAT 환경에서 모니터링 구성이 복잡해집니다. 특히 내부망 또는 방화벽 뒤 타겟을 모니터링하려면 포트를 별도로 열어야 하는 부담이 있습니다. - 중앙 집중식 부하: 모든 scrape 작업이 Prometheus 서버에 집중돼, 타겟이 많을수록 부하가 커집니다.
- 수집 방식의 불일치: 메트릭은 pull, 로그는 push로 동작해 운영 프로세스가 이원화됩니다.
- 이원화된 에이전트 관리: 메트릭과 로그를 별도 에이전트로 관리해야 해 구성과 운영이 복잡합니다.
Grafana Labs는 이러한 운영 제약을 해소하기 위해 통합 에이전트 모델을 도입했습니다. 그 결과물이 바로 Alloy입니다.
Alloy의 문제 해결 방식
Alloy는 Promtail의 한계를 어떻게 해결할까요? 핵심은 수집 아키텍처의 근본적 전환에 있습니다.
로컬 에이전트 기반 push 전송 구조
Alloy는 로컬 에이전트에서 데이터를 수집한 후 중앙 저장소로 push 하는 아키텍처를 지원합니다. 메트릭의 경우, Alloy가 로컬에서 타겟을 scrape(pull)한 후, Prometheus Remote Write 프로토콜로 중앙 서버에 전송(push)합니다. 로그는 Alloy가 직접 수집해 Loki로 push 합니다.
잠깐, push 기반 수집은 이미 있지 않았나요?
맞습니다. OpenTelemetry Collector가 push 기반으로 메트릭, 로그, 트레이스를 전송합니다. 그렇다면 Alloy는 어떤 점에서 차별화됐을까요?
- OpenTelemetry Collector 기반으로 구축됐습니다.
- Grafana Agent의 기능과 운영 경험을 통합합니다.
- Prometheus 네이티브 파이프라인을 직접 지원합니다.
- 결과: OpenTelemetry 표준과 Prometheus 생태계를 동시에 공식 지원합니다.
개선된 점
이러한 아키텍처 전환은 앞서 언급한 전통적인 방식의 제약을 다음과 같이 완화합니다.
- 간소화된 네트워크 구성: Prometheus가 모든 타겟에 직접 접근할 필요가 없으며, Alloy → 중앙 서버 방향의 방화벽만 열면 됩니다.
- 분산 처리와 부하 경감: 각 노드의 Alloy가 로컬에서 데이터 수집, 필터링, 전처리를 수행해 중앙 서버 부하를 줄이고 네트워크 비용도 절감합니다.
- 통일된 전송 방식: 메트릭과 로그 모두 로컬 에이전트에서 중앙으로 push 하는 방식으로 운영 절차가 일관됩니다.
- 단일 에이전트 관리: 메트릭과 로그를 하나의 Alloy 에이전트로 통합 관리해 구성과 운영이 단순화됩니다.
Alloy는 트레이스(Tempo)와 프로파일링(Pyroscope)도 지원하지만, 이 글에서는 익숙한 메트릭과 로그 수집에 집중합니다.
Alloy 첫인상
Alloy를 실제로 사용해 보면 어떤 느낌일까요? 저는 메모리 사용량이 증가했지만, 확장된 기능과 개선된 환경이 이를 충분히 상쇄한다고 생각했습니다.
Promtail과 비교
Alloy를 사용해 보니 이미지 크기와 메모리 사용량은 크게 늘었습니다. 그러나 메트릭, 로그, 트레이스를 통합 수집할 수 있고, 내장 웹 UI도 이용할 수 있어 편리했습니다.
사용자 관점에서 Promtail과 Alloy를 비교한 내용은 다음과 같습니다.
| 항목 | Promtail | Alloy |
|---|---|---|
| 이미지 크기 | 약 217 MB | 약 447 MB |
| 수집 대상 | 로그 | 메트릭, 로그, 트레이스 |
| 설정 언어 | YAML | River (HCL에서 영감받은 구성 언어) |
| 메모리 사용량 (테스트 환경 기준) | ~40MB | ~120MB |
| UI | 없음 | 내장 웹 UI (기본 포트: :12345) |
| 상태 | 유지보수만 지원 | 활발히 개발 중 |
| 디버깅 방법 | docker logs+grep | 웹 UI (Components/Graph 시각화) |
| 설정 복잡도 | 간결함 (12줄) | 명시적이지만 김 (22줄) |
| 학습 곡선 | YAML은 익숙함 | River 문법 학습 필요 |
Alloy의 주요 장점
제가 보기에 Alloy에서 사용 경험을 크게 개선하는 핵심 장점은 다음 두 가지입니다.
내장 웹 UI 기반 디버깅 편의성
Promtail은 웹 UI가 없어 문제가 생기면 로그 파일로만 진단해야 했습니다.
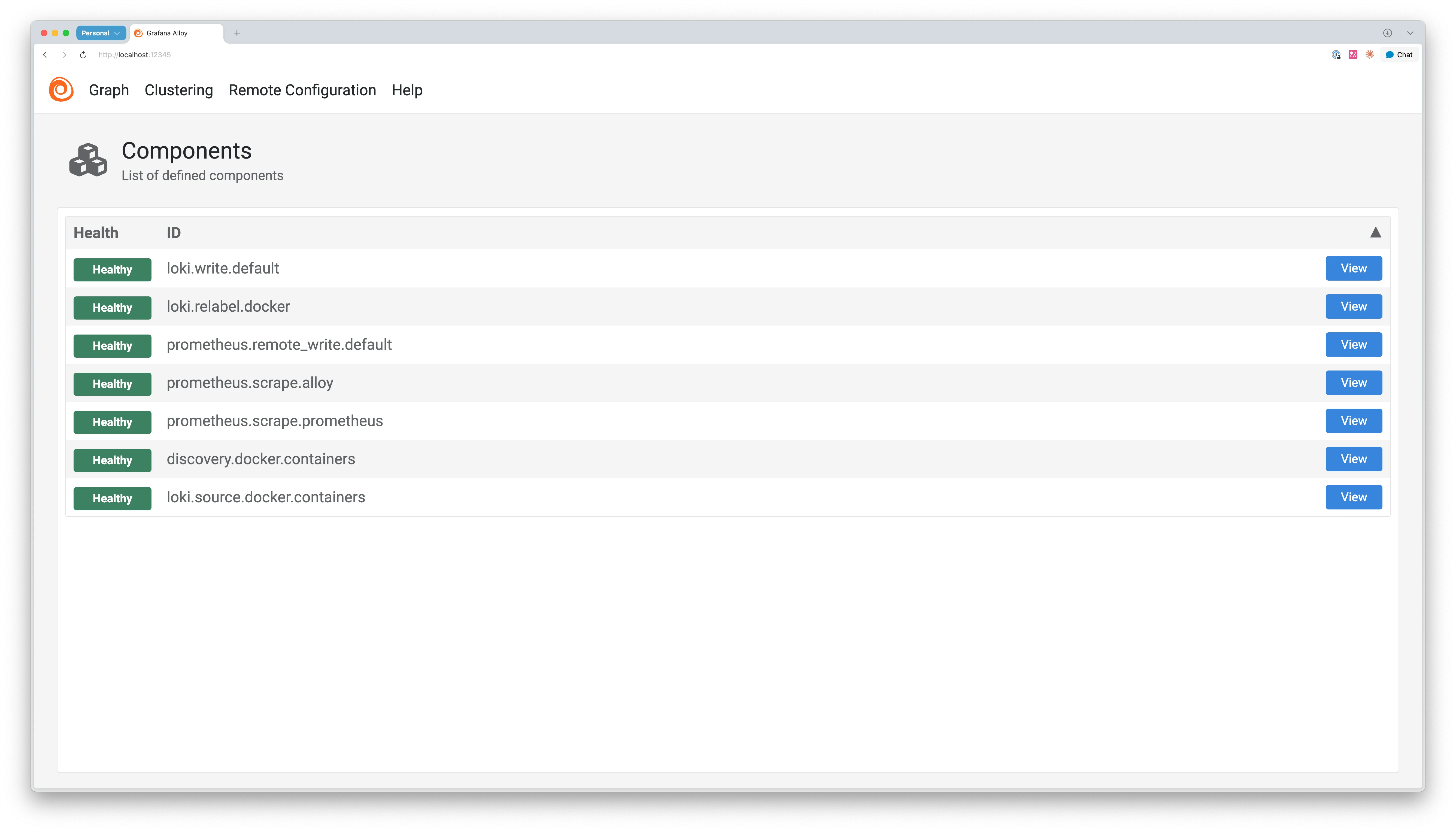
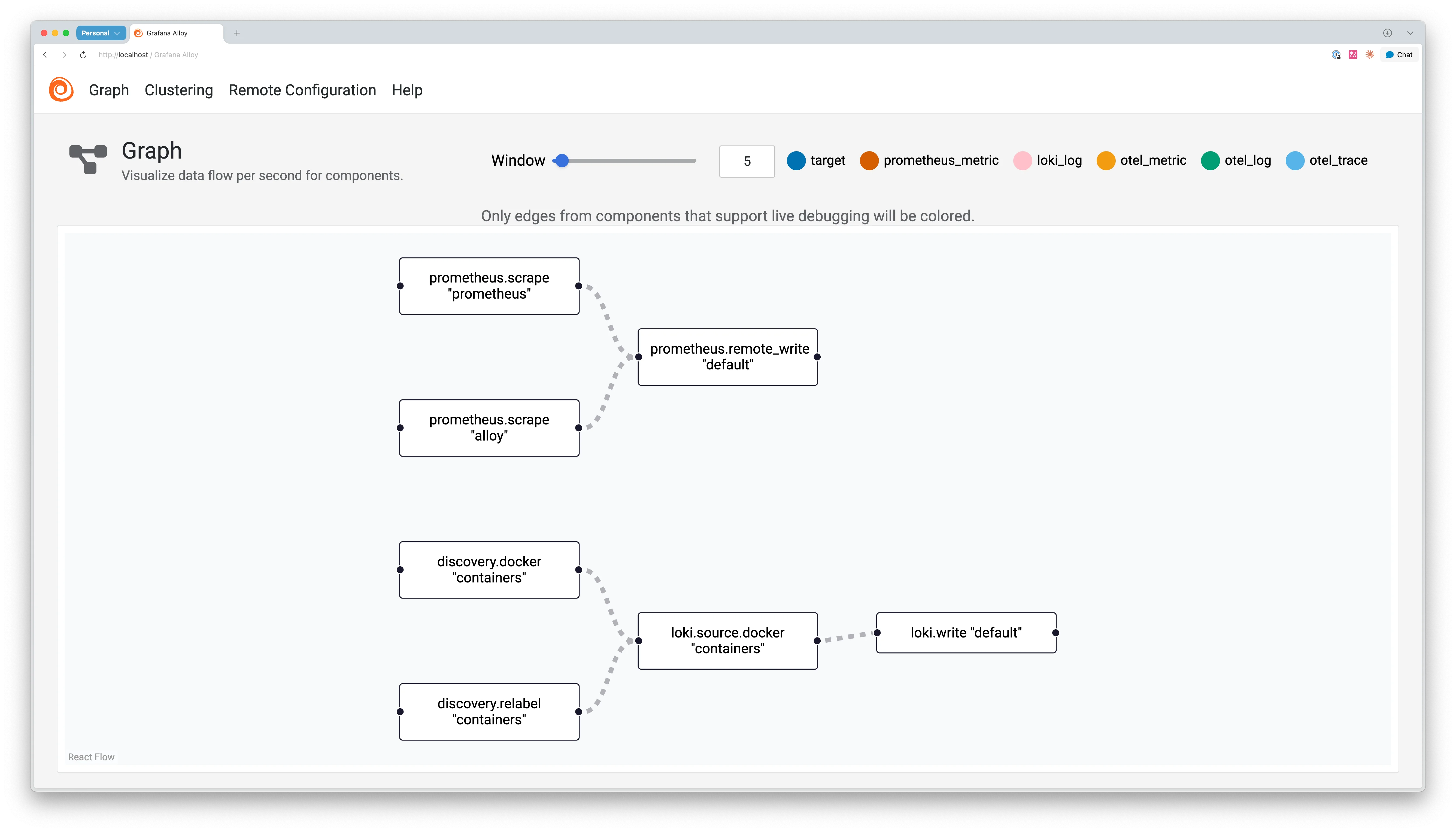
반면에 Alloy는 내장 웹 UI를 제공합니다(기본 포트 :12345). 웹 UI로 현재 실행 중인 컴포넌트 상태와 데이터 흐름을 시각적으로 확인할 수 있습니다.
웹 UI에서는 각 컴포넌트의 상태를 색상(초록/노랑/빨강)으로 표시합니다. 로그 수집이 중단됐을 때, 문제가 발생한 부분을 빠르게 파악해 디버깅 시간을 크게 단축할 수 있습니다.
Alloy 웹 UI의 주요 구성요소는 다음과 같습니다.
- Components: 각 컴포넌트 상태 표시
- Graph: 데이터 흐름 시각화
River의 명시적 데이터 흐름
Promtail과 달리 Alloy는 설정 언어로 River를 사용합니다.
River는 HashiCorp Configuration Language(HCL)에서 영감받은 구성 언어로, 데이터 흐름을 명시적으로 표현하도록 설계됐습니다. Terraform을 사용해 보신 분이라면 구조를 익숙하게 느낄 수 있습니다.
River 구성은 YAML보다 길어 보일 수 있지만, forward_to 키워드로 데이터의 흐름을 명확히 드러내는 게 장점입니다. 또 discovery.relabel에서 타겟 라벨 규칙을 정의하고, loki.source.docker가 relabel_rules로 이를 적용하는 구조로, 전달 관계를 한눈에 파악할 수 있습니다. 이는 코드 블록 형태라 Git diff 비교가 명확하고, 협업할 때도 편리합니다.
-
Promtail 설정 예시 (YAML)
yamlscrape_configs: - job_name: containers docker_sd_configs: - host: unix:///var/run/docker.sock relabel_configs: - source_labels: ['__meta_docker_container_name'] target_label: 'container' -
Alloy 설정 예시 (River)
plaindiscovery.docker "containers" { host = "unix:///var/run/docker.sock" refresh_interval = "5s" } discovery.relabel "containers" { targets = [] rule { source_labels = ["__meta_docker_container_name"] regex = "/(.*)" target_label = "container" } } loki.source.docker "containers" { host = "unix:///var/run/docker.sock" targets = discovery.docker.containers.targets forward_to = [loki.write.default.receiver] relabel_rules = discovery.relabel.containers.rules refresh_interval = "5s" }
Alloy 설치와 데이터 수집 설정
이제 Docker Compose로 Alloy를 설치하고, 로그와 메트릭을 수집하는 방법을 단계별로 살펴보겠습니다.
설치, 초기 설정
Docker Compose를 사용하면 Alloy를 간단하게 시작할 수 있습니다.
docker-compose.yml 구성
먼저 docker-compose.yml 파일을 작성합니다.
services:
alloy:
image: grafana/alloy:v1.9.2
volumes:
- ./config/config.alloy:/etc/alloy/config.alloy:ro
- ./data:/var/lib/alloy/data
- /var/run/docker.sock:/var/run/docker.sock:ro # Docker 로그 수집
networks:
- devops-net # Prometheus, Loki와 같은 네트워크
ports:
- "12345:12345" # UI 포트
기본 설정 파일 작성
다음으로 config.alloy 파일을 생성합니다.
// 로그 레벨
logging {
level = "info"
format = "logfmt"
}
// Prometheus로 메트릭 전송
prometheus.remote_write "default" {
endpoint {
url = "http://prometheus:9090/api/v1/write"
}
}
// Loki로 로그 전송
loki.write "default" {
endpoint {
url = "http://loki:3100/loki/api/v1/push"
}
}
실행, 확인
-
설정 파일 작성을 완료했다면 Alloy를 실행합니다.
bashdocker compose up -d -
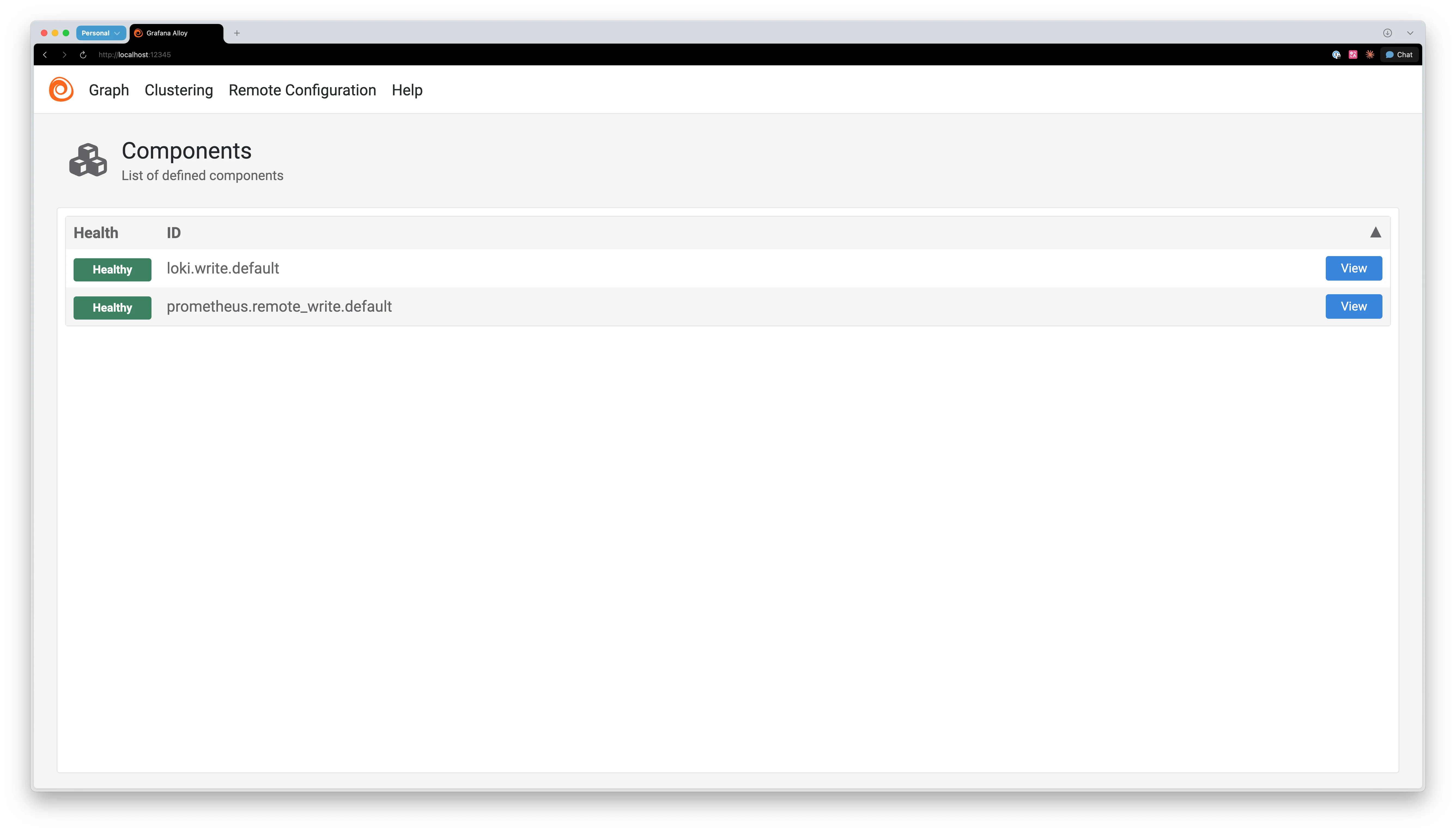
정상적으로 실행됐는지 웹 UI로 확인할 수 있습니다. 브라우저에서 다음 주소로 접속합니다.
plainhttp://localhost:12345 -
정상 작동 시 Alloy의 컴포넌트 목록이 표시됩니다.
로그 수집
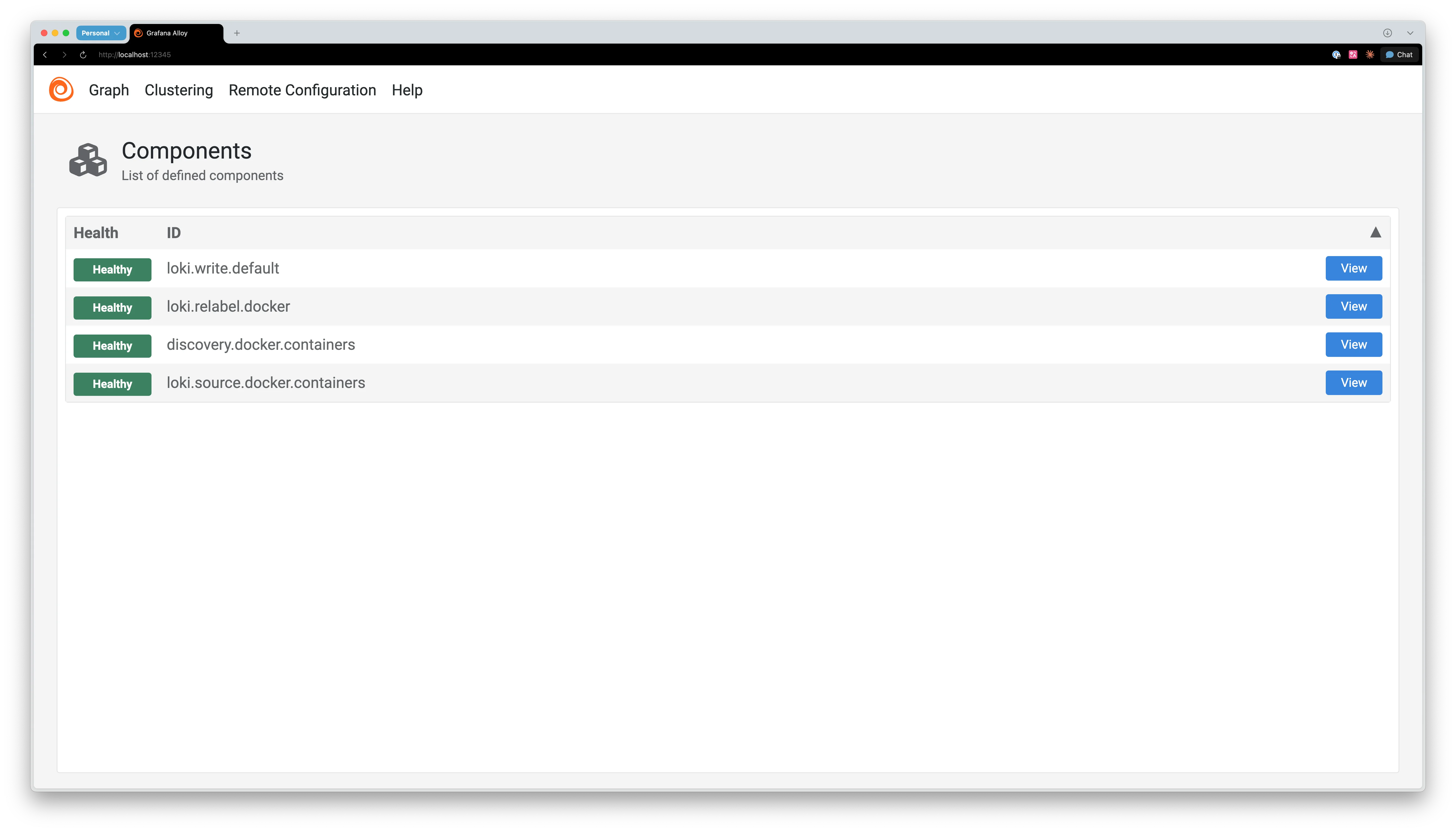
Alloy는 Promtail처럼 Docker 컨테이너 로그를 자동으로 수집할 수 있습니다. 이제 로그 수집을 위한 설정을 추가해 보겠습니다.
로그 수집 설정 추가
앞서 작성한 config.alloy 파일에 다음 설정을 추가합니다.
// Docker 컨테이너 자동 발견
discovery.docker "containers" {
host = "unix:///var/run/docker.sock"
refresh_interval = "5s"
}
// 라벨 재작성 규칙 정의
discovery.relabel "containers" {
targets = []
rule {
source_labels = ["__meta_docker_container_name"]
regex = "/(.*)"
target_label = "container"
}
rule {
source_labels = ["__meta_docker_container_label_com_docker_compose_service"]
target_label = "service"
}
}
// 로그 수집
loki.source.docker "containers" {
host = "unix:///var/run/docker.sock"
targets = discovery.docker.containers.targets
forward_to = [loki.write.default.receiver]
relabel_rules = discovery.relabel.containers.rules
refresh_interval = "5s"
}
// Loki 전송 (이미 위에 정의됨)
loki.write "default" {
endpoint {
url = "http://loki:3100/loki/api/v1/push"
}
}
동작 방식
위 설정은 다음과 같은 순서로 동작합니다.
discovery.docker: 실행 중인 컨테이너를 5초마다 탐지합니다.discovery.relabel: 탐지된 타겟에 적용할 라벨 규칙을 정의합니다.loki.source.docker: 각 컨테이너 로그를 읽고 라벨 규칙을 적용합니다.loki.write: 수집된 로그를 Loki로 전송합니다.
discovery.relabel에서 정의한 라벨 규칙은 loki.source.docker의 relabel_rules 파라미터로 적용됩니다. 새 컨테이너를 실행하면 로그 수집이 자동으로 시작됩니다.
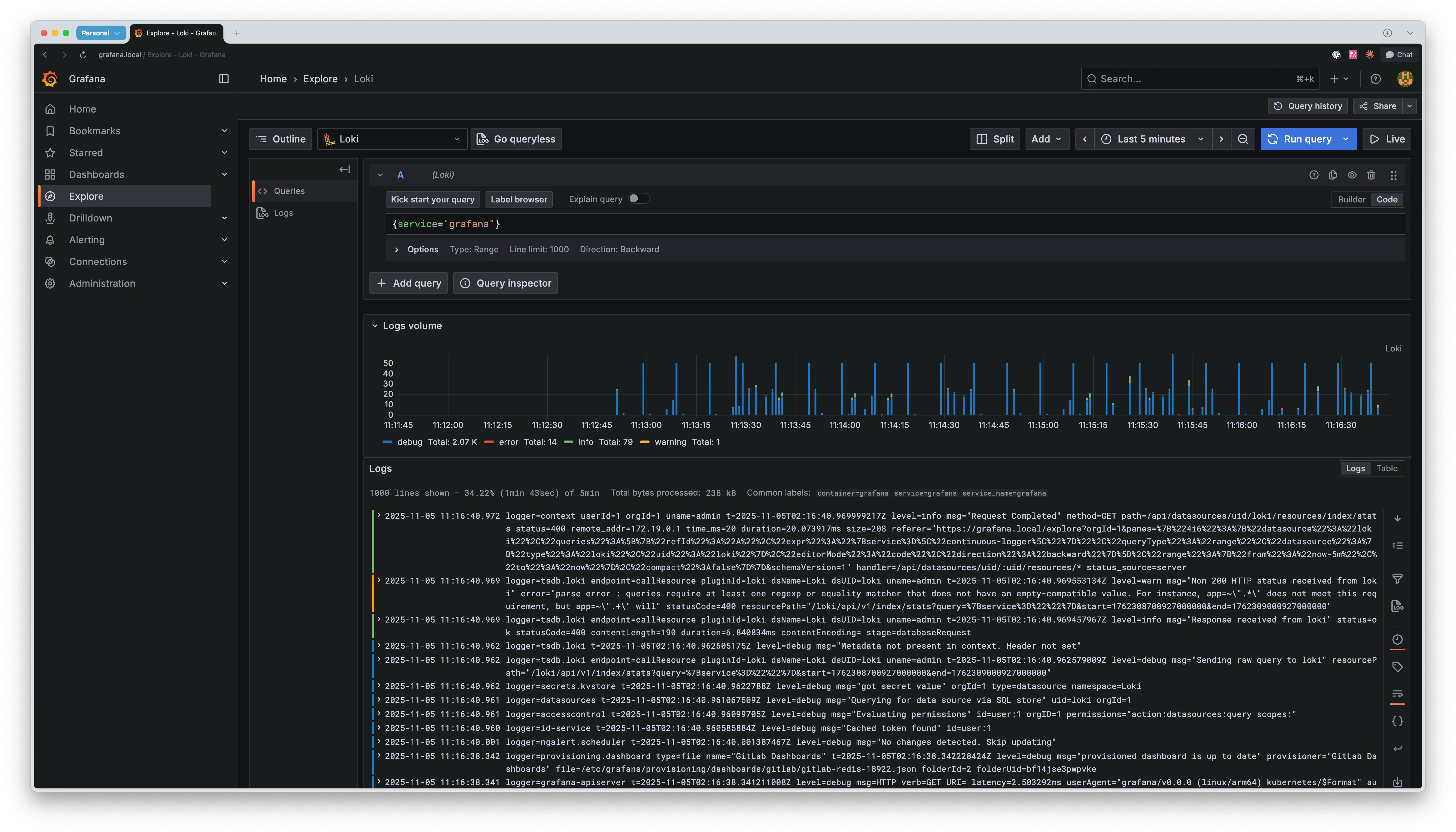
Grafana에서 확인
설정이 정상 작동하는지 Grafana Explore에서 확인할 수 있습니다. 다음 쿼리를 실행합니다.
{service="prometheus"}
로그가 표시되면 설정이 성공적으로 완료된 것입니다.
메트릭 수집
Alloy의 장점은 로그뿐만 아니라 메트릭도 함께 수집할 수 있다는 점입니다. 이제 메트릭 수집 설정을 추가해 보겠습니다.
메트릭 수집 설정 추가
config.alloy 파일에 다음 설정을 추가합니다.
// Alloy 자체 메트릭
prometheus.scrape "alloy" {
targets = [{ __address__ = "localhost:12345" }]
forward_to = [prometheus.remote_write.default.receiver]
}
// Prometheus 서버 메트릭
prometheus.scrape "prometheus" {
targets = [{ __address__ = "prometheus:9090" }]
forward_to = [prometheus.remote_write.default.receiver]
}
// Prometheus 전송 (이미 정의됨)
prometheus.remote_write "default" {
endpoint {
url = "http://prometheus:9090/api/v1/write"
}
}
설정 구조 이해
위 설정의 기본 구조를 살펴보겠습니다.
prometheus.scrape "alloy" {
targets = [{ __address__ = "localhost:12345" }]
forward_to = [prometheus.remote_write.default.receiver]
}
각 요소의 의미는 다음과 같습니다.
prometheus.scrape: 메트릭 수집 컴포넌트"alloy": 컴포넌트 식별자 (이름)targets: 메트릭을 수집할 대상forward_to: 수집한 데이터를 전달할 다음 컴포넌트
forward_to가 River의 핵심입니다. 이는 데이터가 어디로 전달되는지 명시적으로 보여줍니다.
Grafana에서 확인
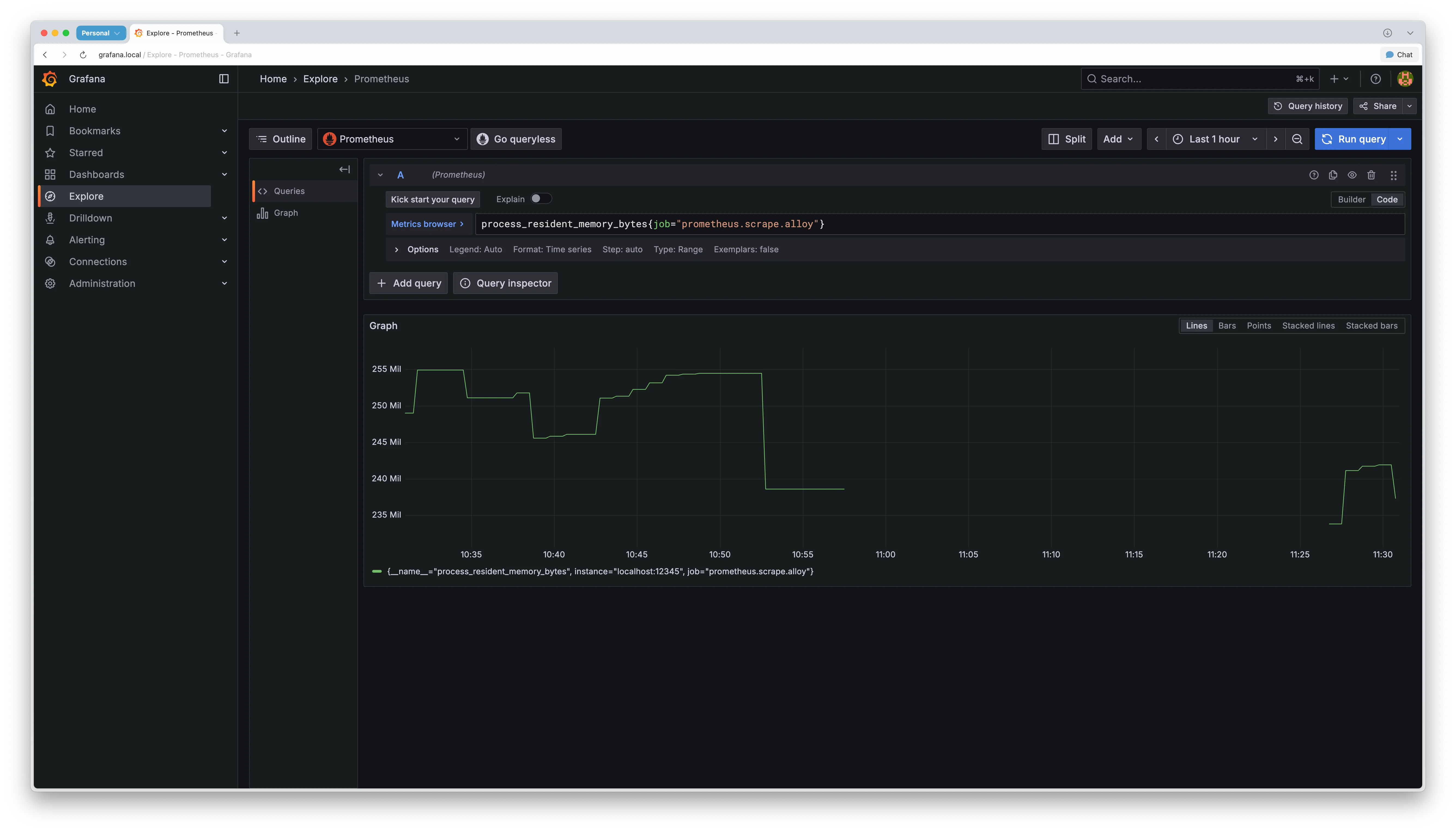
메트릭 수집이 정상 작동하는지 Grafana Explore에서 확인할 수 있습니다. 다음 쿼리를 실행합니다.
# Alloy 메모리
process_resident_memory_bytes{job="prometheus.scrape.alloy"}
# Alloy 컴포넌트 수
alloy_component_controller_running_components
메트릭이 표시되면 설정이 성공적으로 완료된 것입니다.
Alloy 운영 시 유의 사항
Alloy를 운영할 때 성능과 안정성을 위해 다음 사항을 유의해야 합니다.
라벨 카디널리티 관리
Loki의 성능을 유지하려면 라벨 카디널리티를 낮게 유지해야 합니다. 이는 Promtail에서도 중요했던 부분입니다. 컨테이너 ID처럼 값이 자주 바뀌는 항목을 라벨로 사용하면 안 됩니다. 컨테이너를 재시작할 때마다 ID가 변경되면 Loki에 새로운 스트림이 생성돼 성능이 저하됩니다.
// ❌ 잘못된 예시
rule {
source_labels = ["__meta_docker_container_id"]
target_label = "container_id" // 컨테이너마다 ID가 다름
}
// ✅ 올바른 예시
rule {
source_labels = ["__meta_docker_container_label_com_docker_compose_service"]
target_label = "service" // 서비스 이름은 일관적
}
메모리 사용량 모니터링
Alloy는 로그만 전송하는 Promtail 보다 메모리를 더 많이 사용할 수 있습니다. 정기적으로 메모리 사용량을 파악하는 게 좋습니다.
다음 쿼리로 Alloy의 메모리 사용량을 확인할 수 있습니다.
process_resident_memory_bytes{job="alloy"}
Prometheus Remote Write Receiver 설정
Alloy가 메트릭을 Prometheus로 전송하려면 Prometheus에서 Remote Write Receiver가 활성화돼 있어야 합니다.
Prometheus를 실행할 때 다음 플래그를 추가합니다.
prometheus --web.enable-remote-write-receiver
맺음말
Promtail의 EoL 예고는 Alloy를 살펴볼 좋은 계기였습니다. 처음에는 "로그 수집 도구 하나 바뀌는구나!" 정도로 생각했지만, 실제로 사용해 보니 통합 관찰성 에이전트로의 전환이더군요.
- Promtail: 로그 수집, 가벼움, 단순함, EoL
- Alloy: 메트릭+로그+트레이스 수집, 무거움, UI 제공, 활발한 개발
메모리에 여유가 있고 메트릭도 수집하고 싶다면 Alloy로 전환하시길 추천합니다. 반면에 리소스가 제한적이고 로그만 수집해도 된다면 Promtail을 계속 사용하셔도 됩니다. Promtail의 버그는 계속 수정되고 있고, 여러분 환경에서 잘 실행되고 있다면 당장 급하게 바꾸실 필요는 없습니다.
그러나 장기적으로는 Alloy로 전환을 준비해야 합니다. Grafana Labs가 이미 Alloy에 집중하고 있고, 신규 기능도 Alloy에만 추가되고 있습니다. 커뮤니티도 점차 Alloy로 이동하는 추세입니다.
저는 메트릭도 함께 수집하고 싶었고, 웹 UI가 매력적이어서 Alloy로 전환했습니다. 메모리 사용량이 증가했지만, 확장된 기능과 향상된 사용 경험이 그 이상의 가치를 제공한다고 생각합니다.
여러분도 시간이 되실 때 Alloy를 테스트해 보시길 추천합니다. 미리 준비하면 더 여유롭게 전환하고 빠르게 적응하는 데 도움이 될 것입니다.
참고 자료
- Grafana Alloy 공식 문서, https://grafana.com/docs/alloy/latest/
- “Configuration blocks”, Grafana Labs, https://grafana.com/docs/alloy/latest/reference/config-blocks/
- “LogQL: Log query language”, Grafana Labs, https://grafana.com/docs/loki/latest/query/
- “Promtail agent”, Grafana Labs, https://grafana.com/docs/loki/latest/send-data/promtail/
지금 이 기술이 더 궁금하세요? 인포그랩의 DevOps 전문가가 알려드립니다.
사전 동의 없이 2차 가공 및 영리적인 이용을 금하며, 온·오프라인에 무단 전재 또는 유포할 수 없습니다.
관련 태그

Chad
DevOps Engineer
InfoGrab의 DevOps Engineer로서, 인프라 운영부터 AI 에이전트 자동화까지 폭넓게 다룹니다. Kubernetes·Teleport·GitLab CI/CD 기반 인프라 설계와 운영을 담당하며, Claude Code 스킬·MCP 서버 등 AI Native 방식의 업무 자동화를 적극 실험하고 있습니다. 반복 작업을 에이전트에게 위임하는 구조를 만드는 데 관심이 많고, 클러스터에서 직접 인프라를 구성하고 검증하는 것을 즐깁니다. 만든 것을 도구화하여 팀에 공유하는 스타일로 일합니다.
이 저자의 글 모두 보기 →DevOps 도입이 필요하신가요?
인포그랩 전문가가 맞춤 을 도와드립니다.
관련 글

Vector + VRL로 완성하는 클라우드 네이티브 Observability 실전 가이드
Vector는 ELK 스택의 성능 한계를 극복하는 Observability 데이터 파이프라인 도구입니다. 이는 VRL로 타입 안전성과 빠른 데이터 변환을 지원하며, 멀티 백엔드 라우팅으로 효율적인 로그 관리를 돕습니다. 아울러 Vector는 방대한 로그와 메트릭 데이터를 관리하는 데 효과적입니다. 이 글은 Vector의 개념과 특징, 사용 방법, Kubernetes 배포 방법을 실습 예제와 함께 다뤘습니다.
2025년 7월 16일

DevOps 측면에서 Observability와 Monitoring 의미
이 글에서는 DevOps 측면에서 Observability와 Monitoring에 대해 알아보고, Observability가 필요한 이유에 대해 알아봅니다.
2023년 5월 26일

Signoz 소개
Observability 솔루션 Signoz 소개
2023년 5월 15일