인사이트 콘텐츠 저작권 보호 기능 개발, 적용 후기
 Hailie
Hailie
웹사이트에 정성을 담은 글을 게시할 때 드는 마음은 “누군가 이 글을 읽고 도움을 받으면 좋겠다”이지, “누군가 이 글을 훔치지 않으면 좋겠다”가 아닙니다. 하지만 양질의 콘텐츠일수록 콘텐츠 도용이 많이 발생하고 있는 것이 현실입니다. 오늘날 기업에서는 텍스트, 이미지, 비디오, 오디오 등 다양한 콘텐츠를 만들고 있는데요. 그렇다보니 기업 공식 홈페이지나 기술 블로그도 콘텐츠 도용 위험에서 자유롭지 않습니다. 이 문제를 어떻게 해결할 수 있을까요?
최근 저는 인포그랩 공식 홈페이지인 ‘인사이트’의 기술 블로그와 GitLab 가이드 문서에 저작권 보호 기능을 추가하는 업무를 수행했는데요. 이번에 도입한 저작권 보호 기능은 텍스트 콘텐츠에 적용됐습니다. 저작권 보호와 사용자 편의를 모두 충족하는 기능을 도입하고자 여러 문제를 고민하고, 해결 방안을 모색했는데요. 개발 과정에서 고민한 문제와 해결 방향, 최종 결과물을 글로 정리해 보았습니다.
콘텐츠 저작권 보호에 힘써야 하는 이유는?
콘텐츠 창작자 또는 저작권자라면 자신의 콘텐츠를 보호하기 위해 당연히 노력해야 합니다. 이게 왜 당연할까요? 콘텐츠 원본을 복사해 다른 웹사이트에 무단 전재했을 때 생기는 문제를 중심으로 그 이유를 하나씩 살펴보겠습니다.
-
트래픽 감소
사이트 잠재 방문자가 ‘콘텐츠 원본이 있는 우리 웹사이트’가 아닌 ‘콘텐츠 사본이 있는 다른 웹사이트’로 이탈할 수 있습니다. 이는 우리 웹사이트의 트래픽 감소로 이어질 수 있습니다. 왜 그럴까요? 구글, 네이버 등 검색 엔진은 ‘원본 소스’를 식별할 수 없습니다. 따라서 사용자에게 검색어와 관련된 콘텐츠 원본과 내용이 유사한 여러 페이지를 검색 결과로 보여줍니다. 사용자가 검색 결과를 보고, 콘텐츠 사본이 있는 다른 웹사이트로 가면 ‘원본 소스’가 있는 우리 웹사이트의 클릭률(CTR)과 트래픽 양이 감소할 수 있습니다.
-
검색엔진에서 순위 하락
콘텐츠 원본이 있는 우리 웹사이트가 높은 검색 순위에 오르지 못할 수 있습니다. 오히려 콘텐츠 사본을 올린 다른 웹사이트가 검색 엔진 페이지 SERP(Search Engine Result Page)에서 우리 웹사이트보다 더 높은 순위에 오를 수 있습니다. 그 결과, ‘원본 소스’가 있는 우리 웹사이트의 검색 엔진 순위는 떨어질 수도 있습니다.
-
독자의 로열티 감소
콘텐츠 사본을 올린 다른 웹사이트 인기가 더 높아지면 ‘원본 소스’가 있는 우리 웹사이트의 신뢰도가 낮아질 가능성이 있습니다. ‘어느 웹사이트에 콘텐츠 원본이 있는지’ 따로 표시하지 않으면 우리 웹사이트가 마치 콘텐츠를 도용한 것처럼 오해받을 여지도 있습니다. 이는 독자층의 로열티 감소로 이어질 수 있습니다.
어떤 콘텐츠 저작권 보호 방법이 있을까?
콘텐츠 저작권을 보호하는 데 사용하는 방법은 여러 가지가 있습니다. 인포그랩은 우리 공식 홈페이지 ‘인사이트’의 콘텐츠 저작권 보호 방법으로 다음 기능을 적용했습니다.
-
footer에 저작권 고지하기
웹사이트에 ‘Copyright, 발행 연도, 회사명, All Rights Reserved’ 형태로 저작권을 표기하면 이미지마다 저작권을 표기하지 않아도 됩니다. 따라서 인사이트 Footer에 아래와 같이 저작권 고지 문구를 추가했습니다.
인사이트 하단 저작권 문구. 출처=인포그랩
-
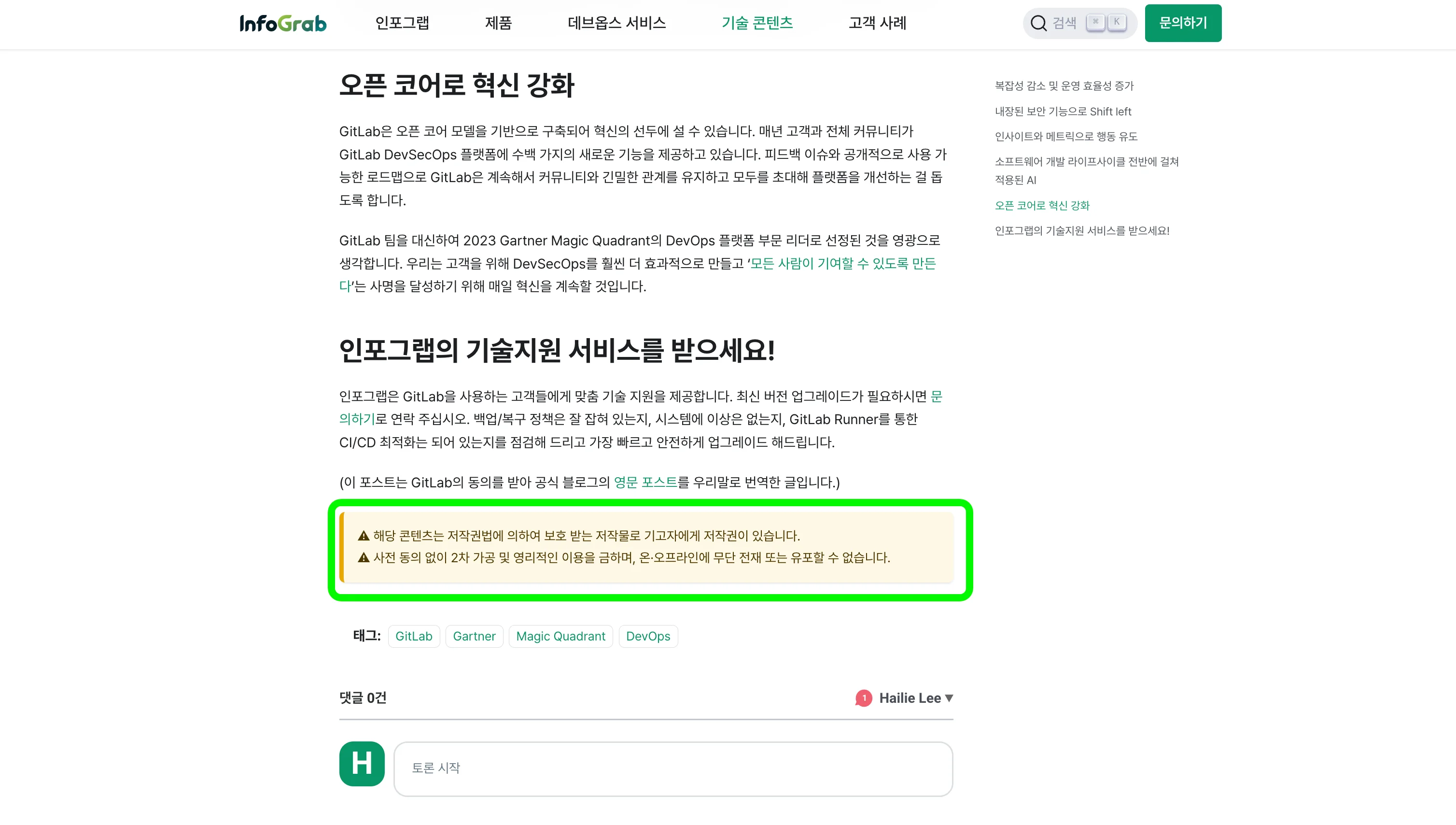
기술 블로그와 GitLab 가이드 문서에 ‘저작권 보호’ 콜아웃 추가하기
‘인사이트 콘텐츠가 인포그랩 재산’이라는 인식을 확실히 주는 문구를 기입했습니다. 사내 테크니컬 라이터의 도움으로 아래 문구를 ‘콜아웃’ 형태로 추가했습니다.
⚠️ 해당 콘텐츠는 저작권법에 의하여 보호 받는 저작물로 기고자에게 저작권이 있습니다.
⚠️ 사전 동의 없이 2차 가공 및 영리적인 이용을 금하며, 온·오프라인에 무단 전재 또는 유포할 수 없습니다.
인사이트 기술 블로그에 추가한 저작권 보호 콜아웃 예시. 출처=인포그랩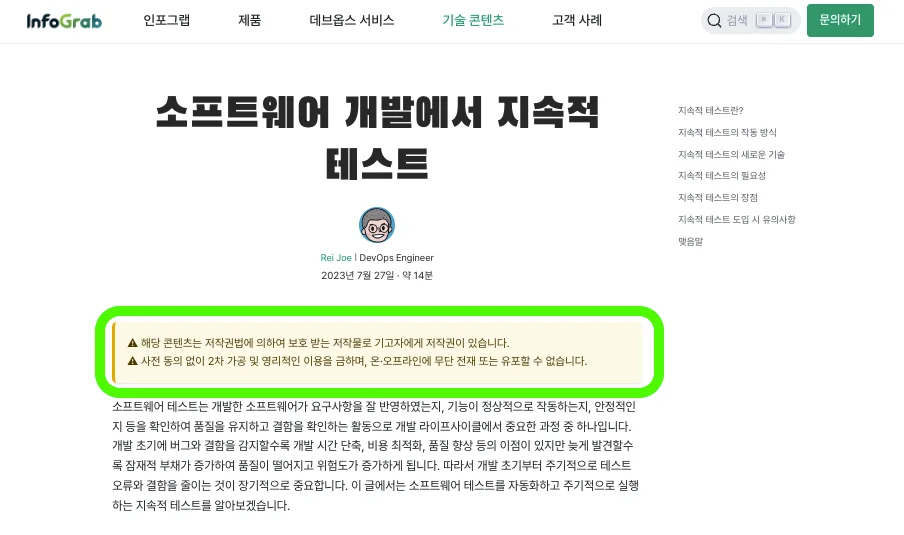
인사이트 GitLab 가이드 문서에 추가한 저작권 보호 콜아웃 예시. 출처=인포그랩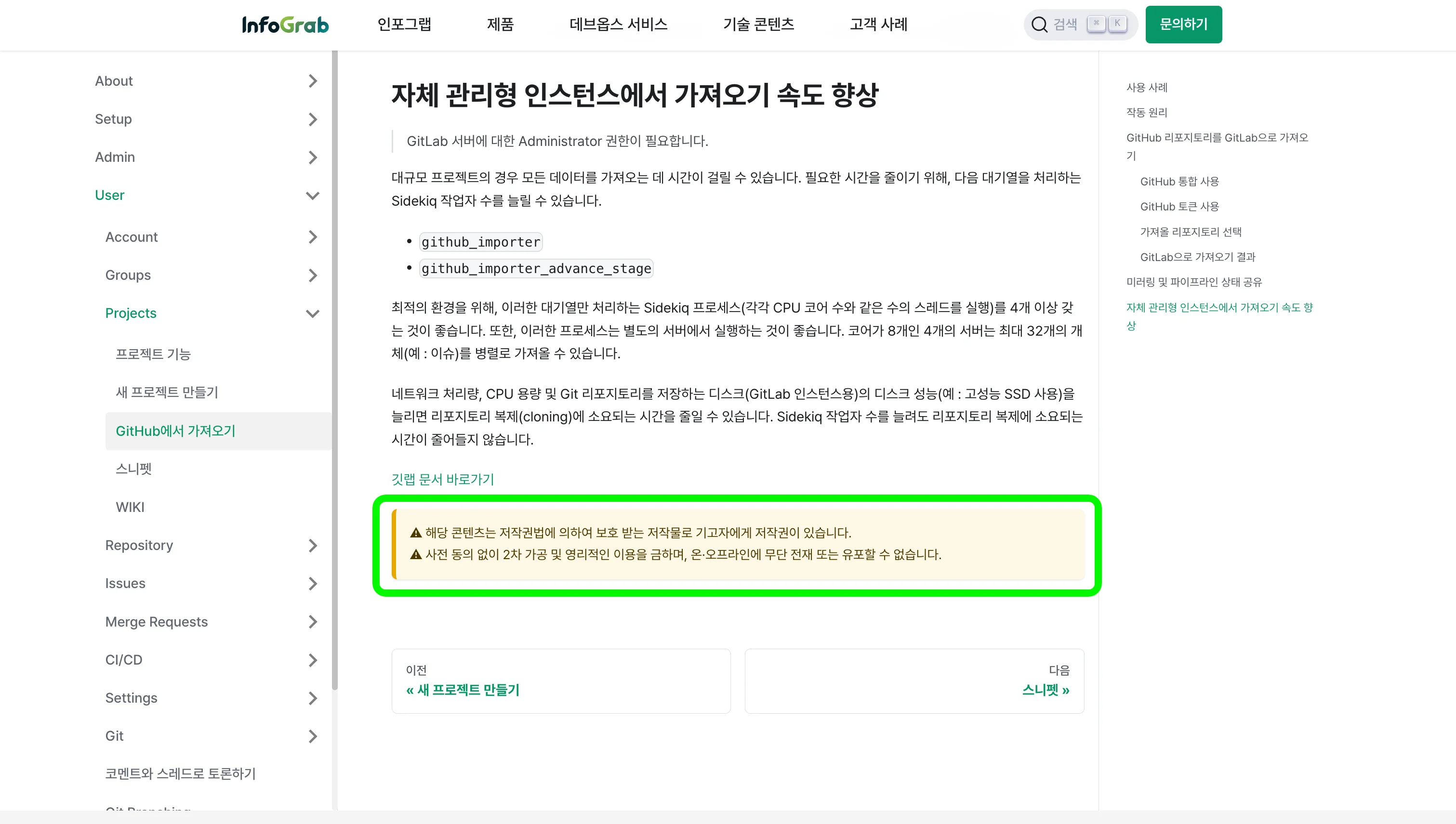
-
마우스 우클릭, 콘텐츠 복사 방지하기
콘텐츠를 악의적으로 도용하는 행위를 막는 방법 중 가장 적극적인 방법은 ‘콘텐츠 복사를 막는 방법’이라고 생각했습니다. 이에 다음 기능을 각각 적용했습니다.
- 마우스 오른쪽 버튼을 클릭하면 기능이 작동하는 걸 막고 "인포그랩의 소중한 자산입니다. 콘텐츠를 복사할 수 없습니다."라는 경고 alert를 띄웁니다.
- 마우스로 글을 드래그한 뒤, 키보드에서 CTR 또는 CMD + C(복사)를 누르면 기능이 작동하는 걸 막고 "인포그랩의 소중한 자산입니다. 콘텐츠를 복사할 수 없습니다."라는 문장이 복사되도록 합니다.
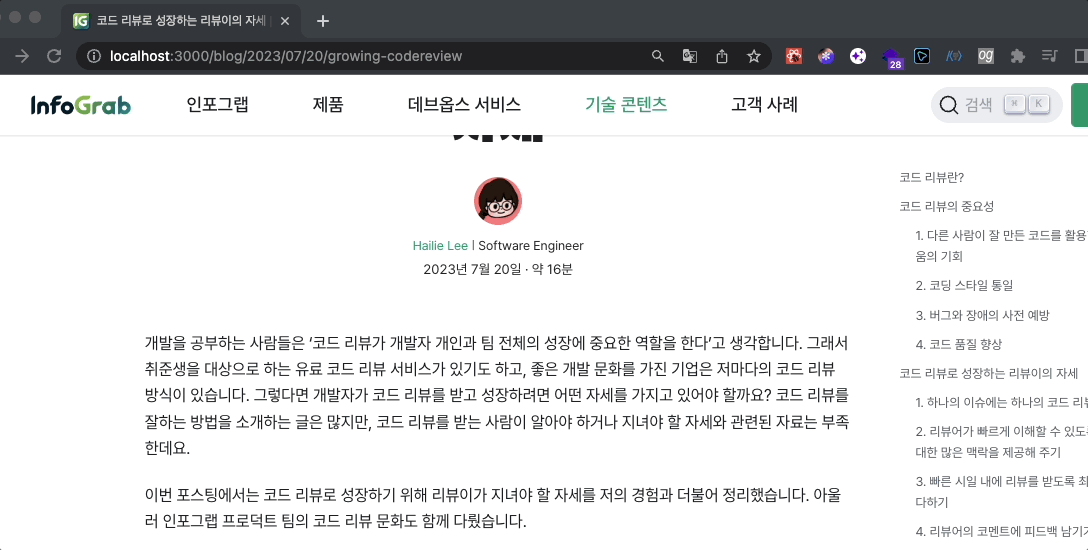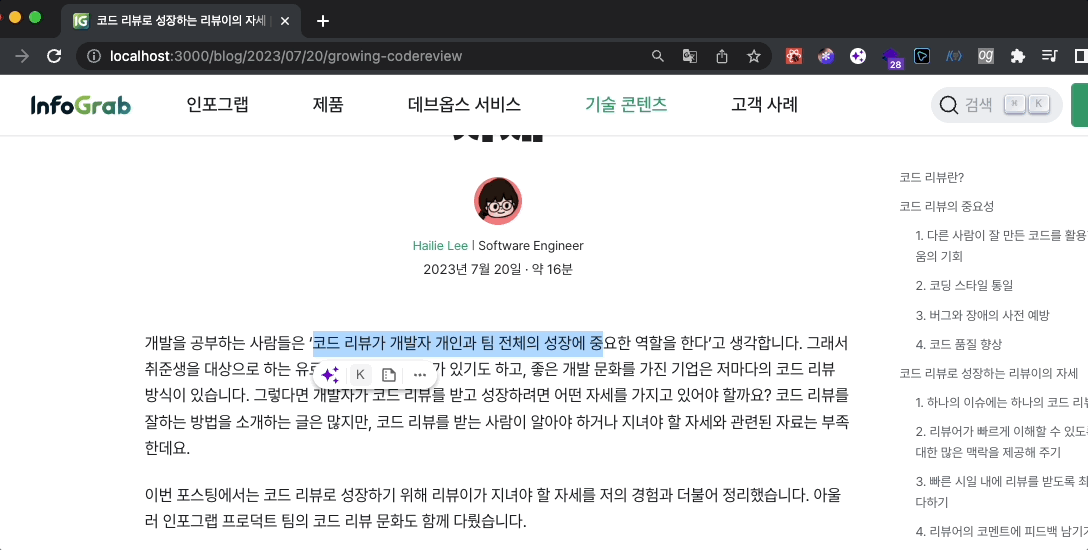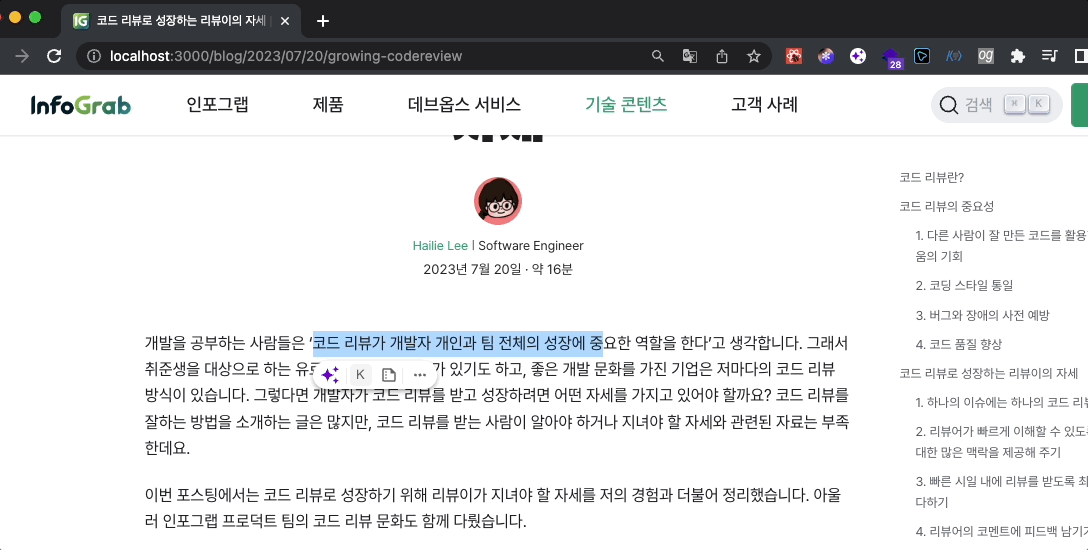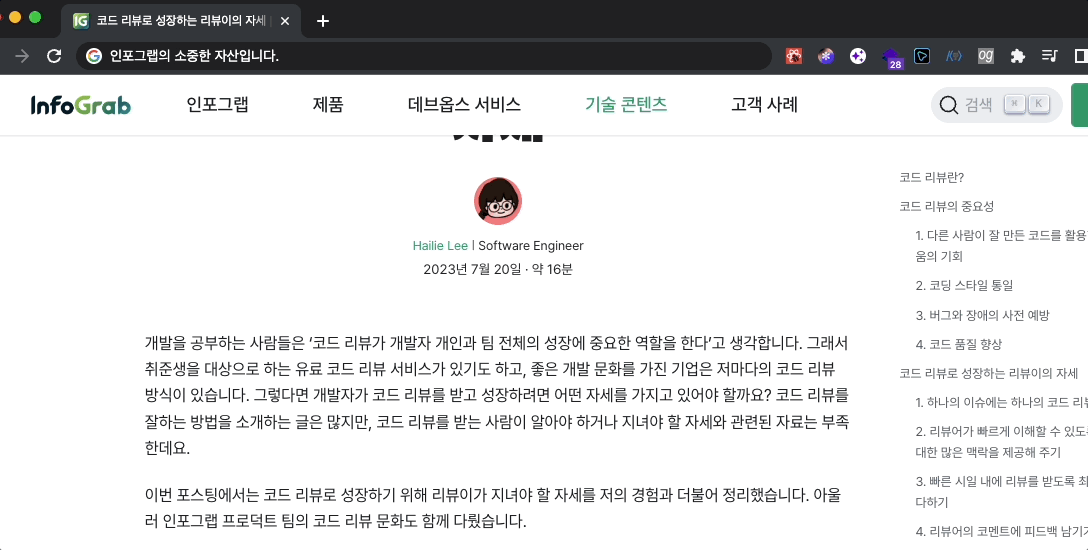
사용자 편의를 높이며 콘텐츠를 보호하려면 어떻게 해야 할까?
내부에서는 ‘콘텐츠 도용을 완벽하게 차단하기는 쉽지 않지만 콘텐츠 저작권 보호 기능을 강화해 보자’라는 의견이 있었습니다. 이에 콘텐츠를 보호하고자 저작권 고지, 콘텐츠 하단에 저작권 보호 콜아웃 설정, 마우스 우클릭 및 콘텐츠 복사 방지 기능을 추가했습니다. 하지만, 인포그랩의 궁극적인 목표는 우리 콘텐츠가 많은 사람에게 전달되는 것입니다. 단순히 방어적으로 콘텐츠 도용을 막으려 노력하는 것만은 아니었습니다.
그래서 ‘우리 콘텐츠를 보호’하는 게 목적이지만, 사용자가 불편을 느끼지 않도록 위 기능을 개선했습니다. 개선 사항은 아래와 같습니다.
- 사용자는 긴 글을 읽을 때 마우스로 드래그하면서 읽습니다. 이에 드래그를 막으면 인사이트에서 콘텐츠를 읽기가 불편할 수 있습니다. 그래서 드래그 자체를 막는 대신 마우스 오른쪽 버튼을 클릭하면 ‘콘텐츠 복사 경고 문구’를 띄우기로 했습니다.
- 저작권 보호 콜아웃을 콘텐츠 상단에 두면 사용자가 콘텐츠를 읽기 전에 자칫 거부감을 느낄 수 있다고 생각했습니다. 또한 우리 콘텐츠 내용을 저작권 보호 콜아웃보다 먼저 노출하는 게 긍정적인 사용자 경험에 도움이 될 수 있다고 판단했습니다. 그래서 콜아웃을 콘텐츠 하단에 넣기로 했습니다.
- 글을 드래그하고 마우스 오른쪽 버튼을 클릭할 때 뜨는 경고 alert가 딱딱한 인상을 줄 수 있다고 생각했습니다. 그래서 경고 alert에 조금 더 미려한 인터랙션을 도입하기로 했습니다. 여기에는 브라우저에서 제공하는 alert가 아닌 모달창을 적용했습니다. 경고 의미를 담은 ‘손’ 이모티콘과 안내 문구를 함께 노출했습니다. 이로써 안내 문구를 돋보이게 하고, 메시지 의도도 분명하게 전달하고자 했습니다.
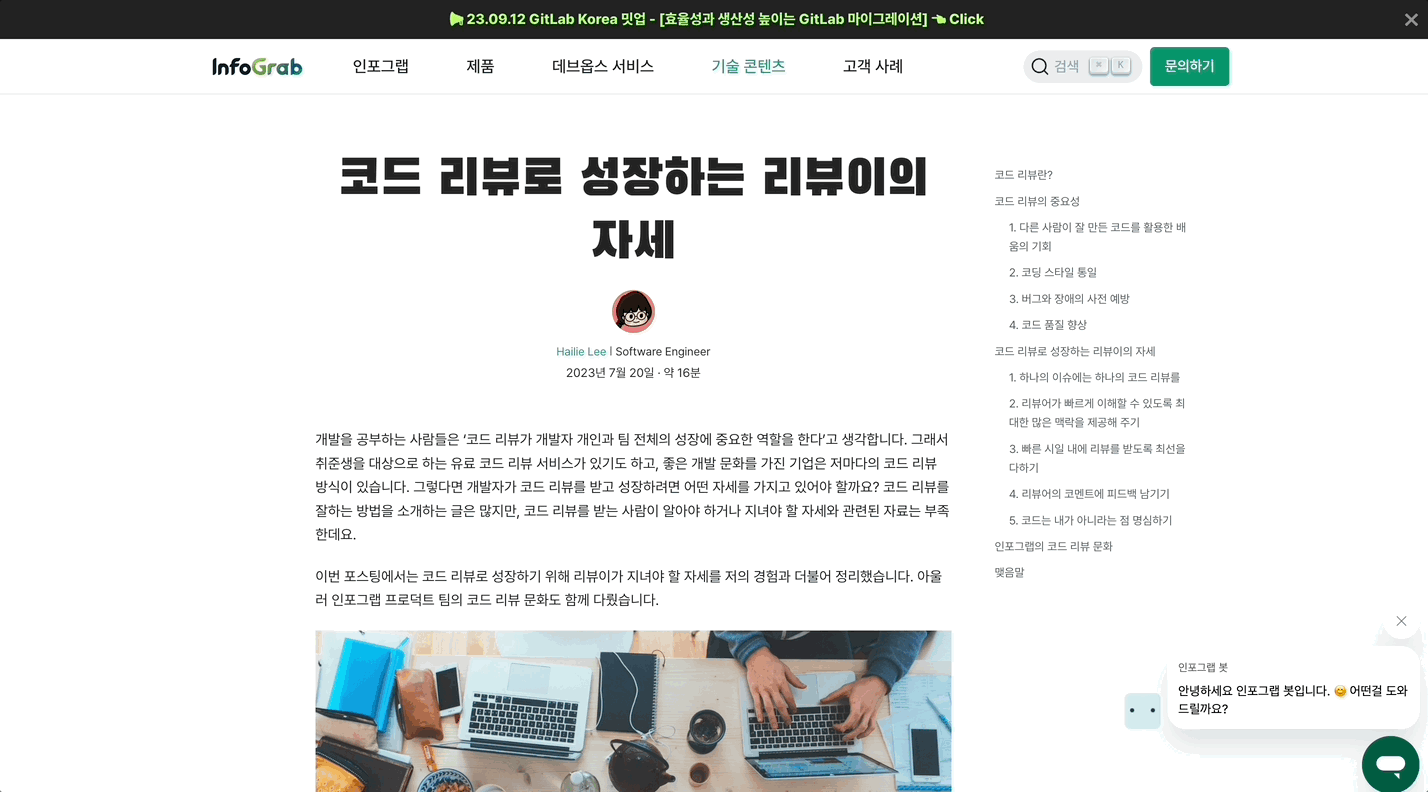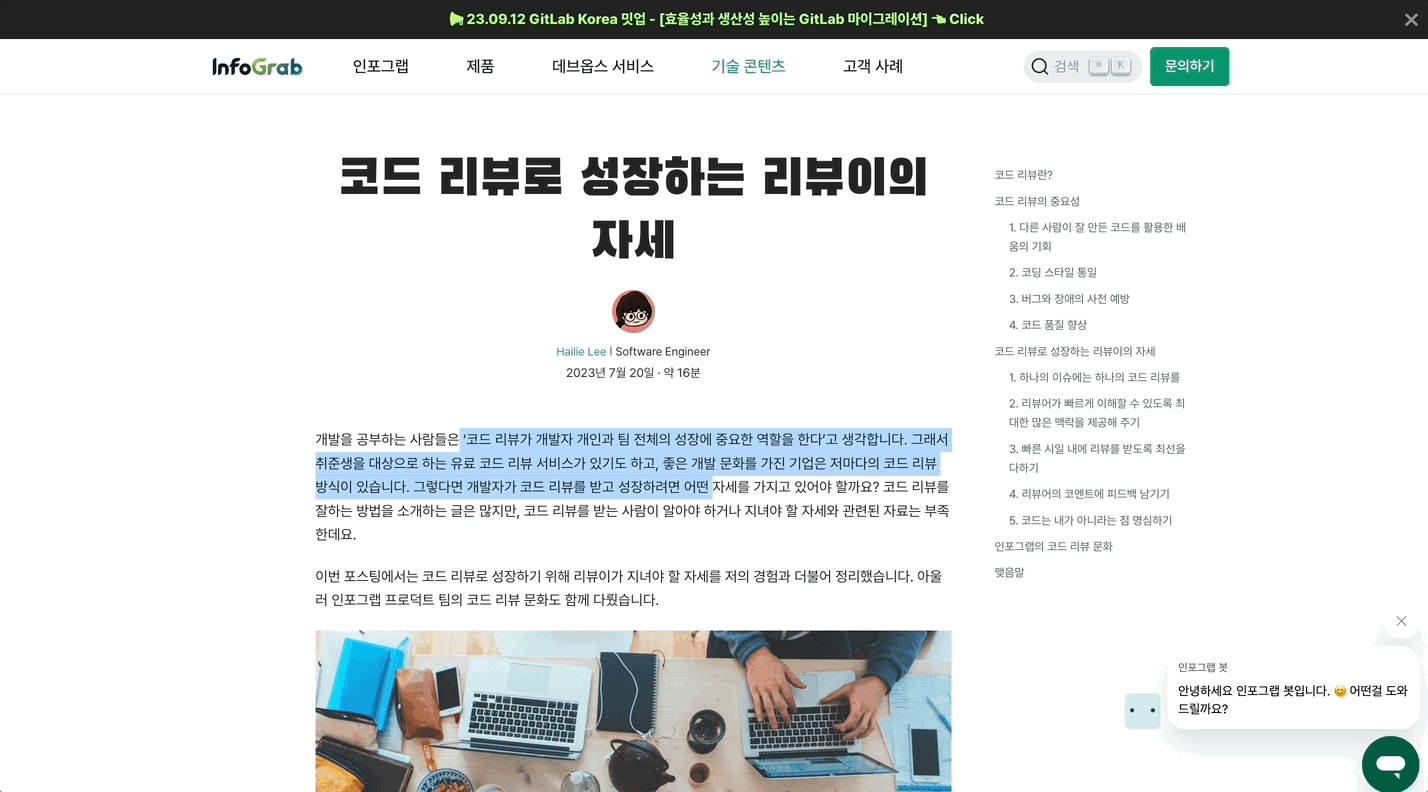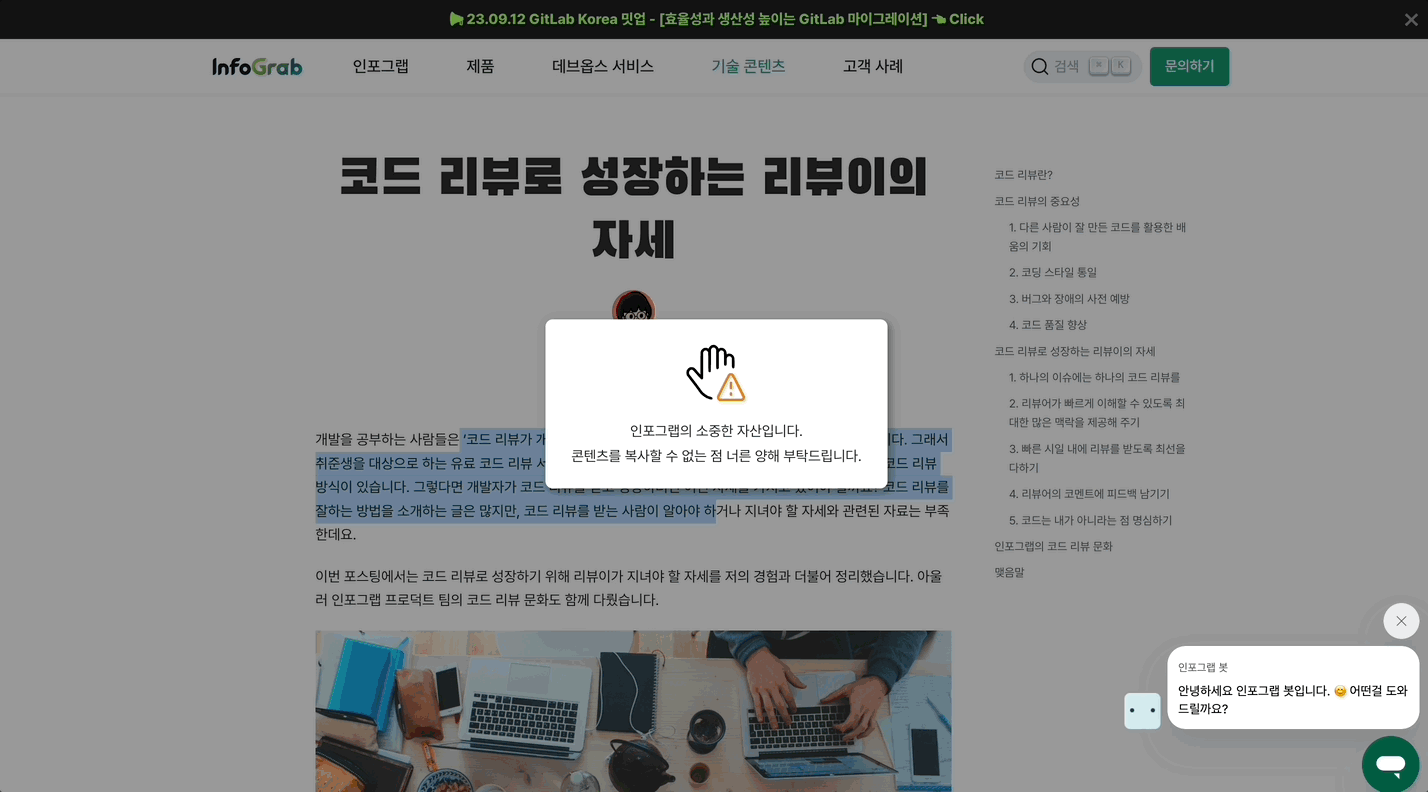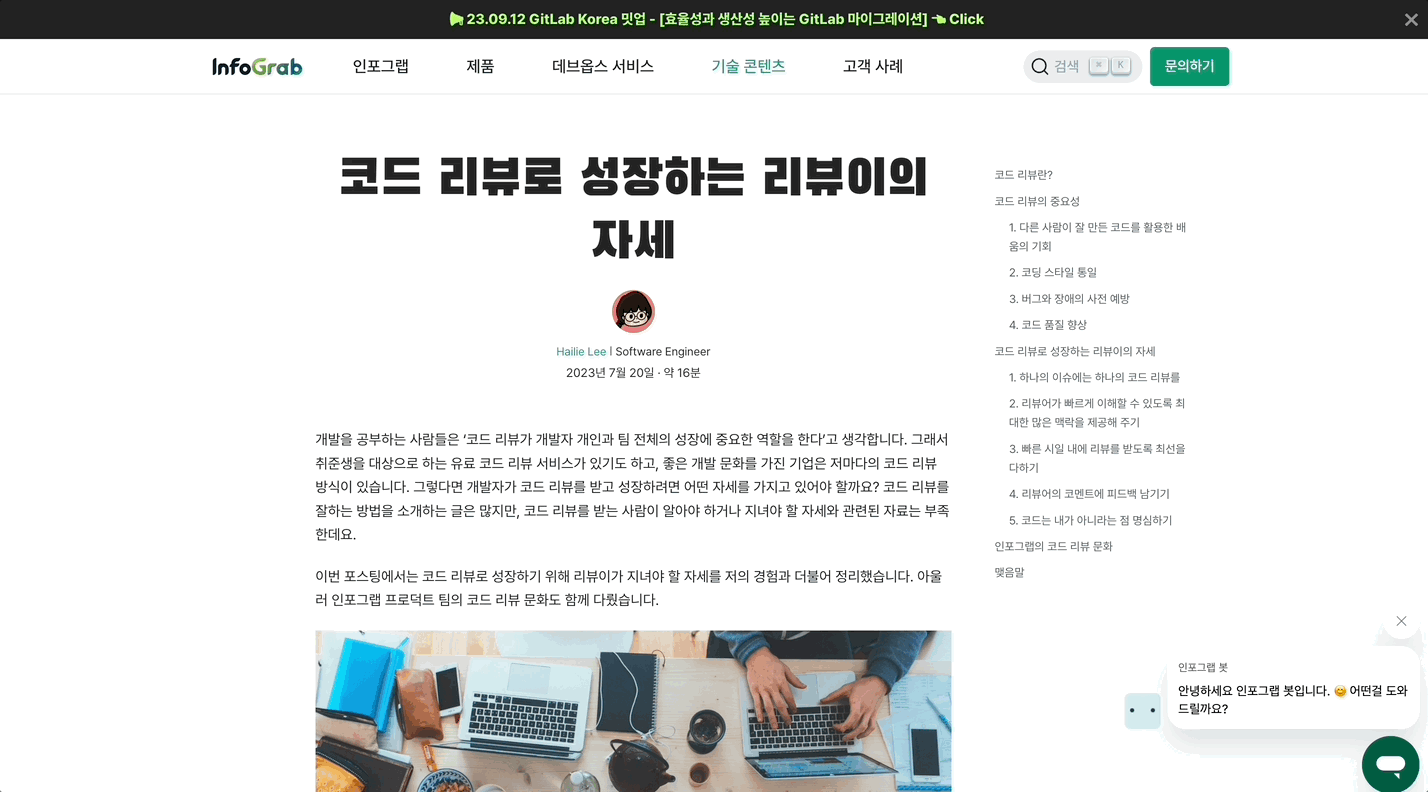
-
콘텐츠를 복사할 때 나오는 안내 문구에 단호한 느낌이 강했습니다. 어떤 때는 부드럽고 분명하게 메시지를 전달하는 게 우리가 의도하는 사용자 행동을 유도하는 데 도움이 될 수 있습니다. 따라서 감성적으로 회유하는 느낌이 묻어나도록 안내 문구를 수정했습니다.
"인포그랩의 소중한 자산입니다. 콘텐츠를 복사할 수 없습니다."라는 기존 안내 문구를 "인포그랩의 소중한 자산입니다. 콘텐츠를 복사할 수 없는 점 너른 양해 부탁드립니다.”로 수정해 독자를 배려하는 마음을 표현하고자 노력했습니다.
맺음말
콘텐츠를 보호하기 위해 시도할 방법은 무수히 많지만 콘텐츠를 온전히 보호할 수는 없습니다. 크롬의 확장 프로그램이나 개발자 도구로 복사, javascript disabled 설정 등 마음만 먹으면 복사할 방법이 많기 때문입니다.
하지만, 콘텐츠 저작권 보호 기능은 ‘콘텐츠가 우리 자산’이라는 인식, ‘우리는 콘텐츠를 적극적으로 보호한다’는 의지를 명확히 전달합니다. 따라서 무단 복사와 무단 전재를 막는 수단으로써 이 기능은 중요합니다. 콘텐츠 저작권을 더 현명하게 보호하는 방법을 아는 분은 아래 댓글에 공유해 주시면 감사하겠습니다.
인포그랩은 GitLab 및 DevOps에 대한 맞춤 기술 지원을 제공합니다. GitLab(Omnibus/Cloud Native Hybrid) 구축 관련한 지원이 필요하시면 문의하기로 연락 주십시오.
참고 자료
사전 동의 없이 2차 가공 및 영리적인 이용을 금하며, 온·오프라인에 무단 전재 또는 유포할 수 없습니다.
Hailie
Software Engineer
DevOps 도입이 필요하신가요?
인포그랩 전문가가 맞춤 을 도와드립니다.
관련 글

ChatGPT 잠재력을 활용해 DevOps 워크플로 개선하기
ChatGPT를 사용하여 DevOps 워크플로를 개선하는 방법에 대해 설명합니다. ChatGPT를 사용하여 코드 생성, 문서화, 코드 검토 및 이해, 오류 감지 및 해결, PoC, 리팩토링을 수행할 수 있습니다. 그러나, 범용 AI는 제한된 도메인 지식을 가지고 있으므로 전문화된 작업에는 도메인별 AI 모델이 더 적합할 수 있습니다. 또한, 보안 및 개인 정보 보호 문제가 발생할 수 있으므로 인간의 감독과 전문 지식이 필요합니다.
2023년 6월 29일

GitLab 코드 제안(Code Suggestions)으로 개발자의 생산성을 향상하는 방법
GitLab의 코드 제안 기능은 개발자의 생산성을 향상시키는 기술로, 패키지 import, 함수 자동 완성, Boilerplate 입력, 데이터 프레임 구축, 단위 테스트 생성 등의 작업을 빠르게 처리할 수 있습니다. 현재 베타 버전으로 모든 사용자가 GitLab.com에서 무료로 사용할 수 있으며, 지원 언어는 13개로 확장되었습니다.
2023년 6월 22일