




오늘은 7월 진행된 n8n 최신 버전의 주요 업데이트와 개선사항을 소개합니다. 버전 1.101부터 1.104까지의 핵심 기능, 버그 수정 및 성능 향상에 대한 정보를 확인하세요. 특히 웹훅 html 응답부터 AI 평가를 위한 내장지표, 다양한 AI 에이전트까지! 향상된 AI기능과 노드, 보안을 통해 워크플로우를 더 효율적으로 관리하고 구축할 수 있습니다.
버전 하이라이트
이번 릴리스에는 핵심 업데이트, 에디터 개선, 새로운 노드, 노드 개선 및 버그 수정이 포함되어 있습니다.
웹훅 HTML 응답
이번 릴리스부터 워크플로우가 웹훅에 HTML 응답을 보내면, n8n은 자동으로 콘텐츠를 아이프레임으로 감싸게 됩니다. 이는 인스턴스 사용자를 보호하기 위한 보안 메커니즘입니다.
이로 인해 다음과 같은 영향이 있습니다:
- HTML은 부모 문서에 직접 렌더링되는 대신 샌드박스 아이프레임 내에서 렌더링됩니다.
- 최상위 창이나 로컬 스토리지에 접근하려는 JavaScript 코드는 실패하게 됩니다.
- 인증 헤더는 샌드박스 아이프레임에서 사용할 수 없습니다(예: 기본 인증). HTML 내에 단기 액세스 토큰을 포함하는 등 대체 접근 방식을 사용해야 합니다.
- 상대 URL은 작동하지 않습니다. 절대 URL을 사용하세요.
AI 평가를 위한 내장 지표
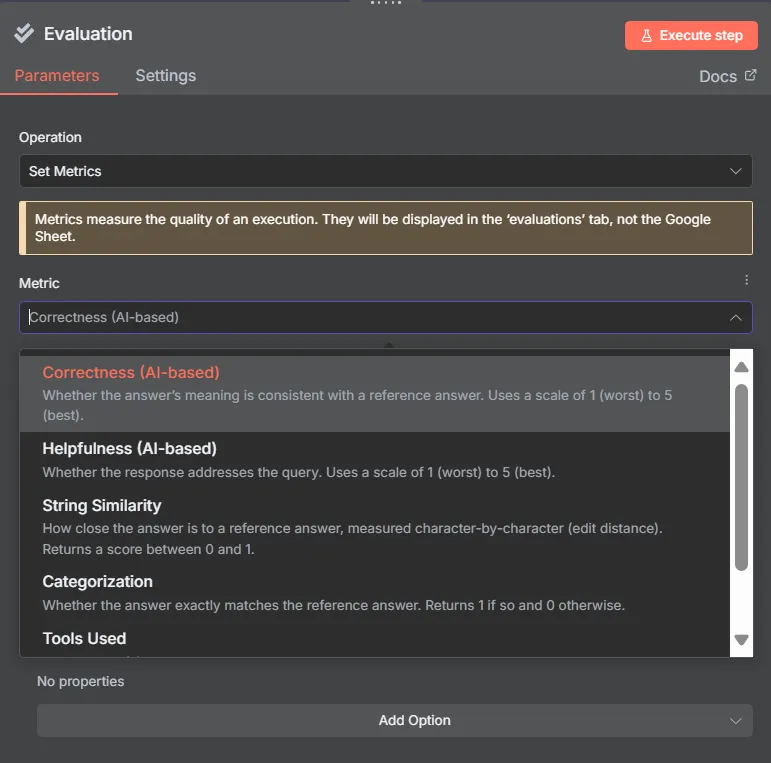
평가는 모든 AI 솔루션에서 모범 사례이며, 특히 신뢰성과 예측 가능성이 비즈니스에 중요한 경우에는 필수적입니다. 이번 릴리스에서는 내장 지표 세트를 도입하여 n8n에서 평가를 더 쉽게 설정할 수 있게 되었습니다. 이러한 지표를 통해 AI 응답을 검토하고 정확성, 유용성 등의 요소를 기준으로 점수를 매길 수 있습니다.
AI 워크플로우의 성능을 모니터링하려면 정기적인 평가를 실행하고 시간에 따른 점수 변화를 검토하면 됩니다. 또한 다양한 모델 간의 결과를 비교하여 최적의 모델을 선택하거나, 프롬프트 변경 전후에 평가를 실행하여 데이터 기반의 반복적인 개선을 할 수 있습니다.
n8n의 모든 평가와 마찬가지로, 테스트하려는 입력이 포함된 데이터셋이 필요합니다. 일부 평가에서는 비교를 위한 예상 출력(근거 진실)도 데이터셋에 포함해야 합니다. 평가 워크플로우는 테스트 중인 부분을 통해 각 입력을 실행하여 응답을 생성합니다. 내장 지표는 측정하려는 측면에 따라 각 응답에 점수를 매겨, 변경 전후의 결과를 비교하거나 Evaluations 탭에서 시간에 따른 추세를 추적할 수 있게 해줍니다.
여전히 사용자 정의 지표를 정의할 수 있지만, 일반적인 사용 사례에서는 내장된 옵션을 사용하면 구현 시간을 크게 단축할 수 있습니다.
사용 방법:
- 여기에 설명된 대로 평가를 설정하고, Evaluation 노드를 트리거로 사용하고 Set Metrics 작업이 있는 또 다른 노드를 사용합니다.
- Set Metrics 노드에서 드롭다운 목록에서 지표를 선택합니다.
- 선택한 지표에 필요한 추가 매개변수를 정의합니다. 대부분의 경우 데이터셋 열을 적절한 필드에 매핑하는 작업이 포함됩니다.
사용 가능한 내장 지표:
- 정확성(AI 기반): AI 워크플로우가 생성한 응답을 예상 답변과 비교합니다. 다른 LLM이 심사관 역할을 하여 프롬프트에 제공한 지침에 따라 응답에 점수를 매깁니다.
- 유용성(AI 기반): LLM과 프롬프트에 정의된 점수 기준을 사용하여 사용자 쿼리와 관련하여 응답의 유용성을 평가합니다.
- 문자열 유사성: 문자열을 비교하여 응답이 예상 출력과 얼마나 일치하는지 측정합니다. 명령 생성이나 출력이 특정 구조를 따라야 할 때 유용합니다.
- 분류: 응답이 예상 라벨과 일치하는지 확인합니다. 예를 들어 항목을 올바른 카테고리에 할당하는 경우에 유용합니다.
- 사용된 도구: AI 에이전트가 데이터셋에 지정한 도구를 호출했는지 확인합니다. 이를 활성화하려면 에이전트에서 Return Intermediate Steps를 켜서 평가가 실제로 호출한 도구에 접근할 수 있도록 하세요.
참고 사항
- 등록된 Community Edition은 Evaluations 탭에서 하나의 평가 분석을 활성화하여 시간 경과에 따른 평가 실행을 쉽게 비교할 수 있습니다. Pro 및 Enterprise 플랜은 Evaluations 탭에서 무제한 평가를 허용합니다.
AI 에이전트 도구 노드
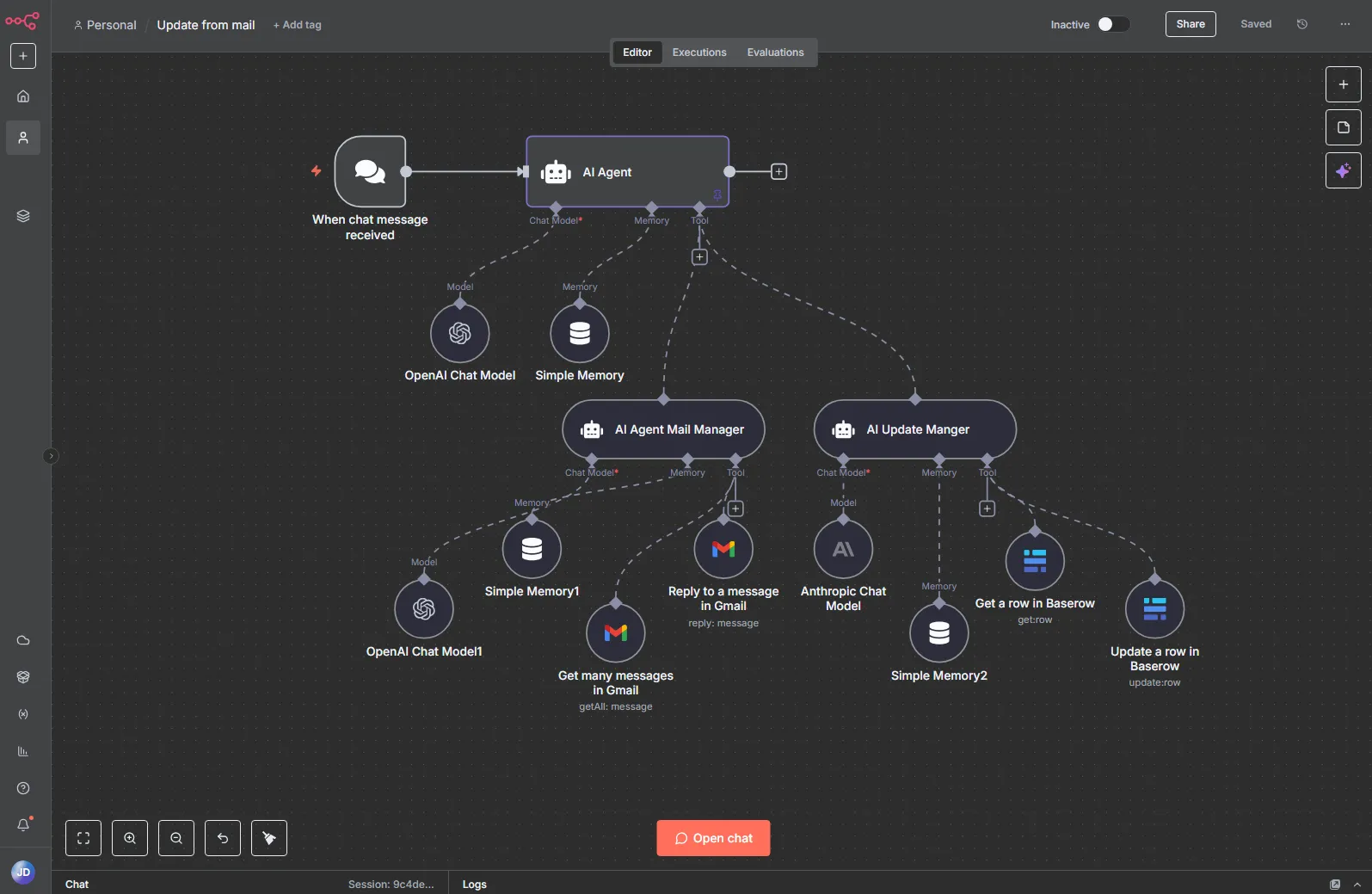
AI 에이전트 도구 노드는 단일 실행으로 작동하고 하나의 캔버스에서 완전히 관리되는 멀티 에이전트 오케스트레이션을 위한 간소화된 패턴을 제공합니다.
이제 여러 AI 에이전트 도구 노드를 기본 AI 에이전트 노드에 연결하여 다양한 전문 에이전트 간의 작업을 감독하고 위임할 수 있습니다.
이 설정은 리드 에이전트가 전문가에게 작업을 할당하는 실제 팀처럼 작동하는 복잡한 시스템 구축에 특히 유용합니다. 또한 길고 복잡한 지시사항을 여러 에이전트 간에 더 작고 집중된 작업으로 나눌 수 있어 프롬프트 관리가 용이해집니다. 서브 워크플로우를 통해 유사한 오케스트레이션이 이미 가능했지만, 단일 실행 내에서 상호작용을 원하거나 단일 캔버스에서 모든 것을 관리하고 디버깅하고자 할 때는 AI 에이전트 도구 노드가 더 효과적인 선택입니다.
사용 방법:
- 워크플로우에 AI 에이전트 노드를 추가하고 **+**를 클릭하여 도구 연결을 생성합니다.
- 노드 패널에서 AI 에이전트 도구 노드를 검색하고 선택합니다.
- 기본 에이전트가 참조할 수 있도록 노드 이름을 명확하게 지정한 다음 짧은 설명과 프롬프트를 추가합니다.
- 해당 역할을 수행하는 데 필요한 LLM, 메모리 및 도구를 연결합니다.
- 기본 AI 에이전트에게 AI 에이전트 도구를 언제 사용할지 지시하고 프롬프트에 관련 컨텍스트를 전달하도록 합니다.
참고 사항:
- 오케스트레이팅 에이전트는 기본적으로 전체 실행 컨텍스트를 전달하지 않습니다. 필요한 컨텍스트는 프롬프트에 포함되어야 합니다.
AI 에이전트 도구 노드는 서브 워크플로우에 의존하지 않고 계층화된 에이전트 간 워크플로우를 구축하는 것을 더 쉽게 만들어 멀티 에이전트 시스템을 구축하고 디버깅할 때 더 빠르게 작업할 수 있도록 도와줍니다.
인스턴스 전체에 2FA 적용
엔터프라이즈 인스턴스 소유자는 이제 인스턴스의 모든 사용자에게 이중 인증(2FA)을 적용할 수 있습니다. 활성화되면 2FA를 설정하지 않은 모든 사용자는 n8n을 계속 사용하기 전에 설정을 완료하도록 리디렉션됩니다. 이는 조직이 내부 보안 정책을 충족하고 작업 공간 전체에서 더 강력한 보호를 보장하는 데 도움이 됩니다.
이 기능은 엔터프라이즈 플랜에서만 사용할 수 있습니다.
모델 선택기 노드
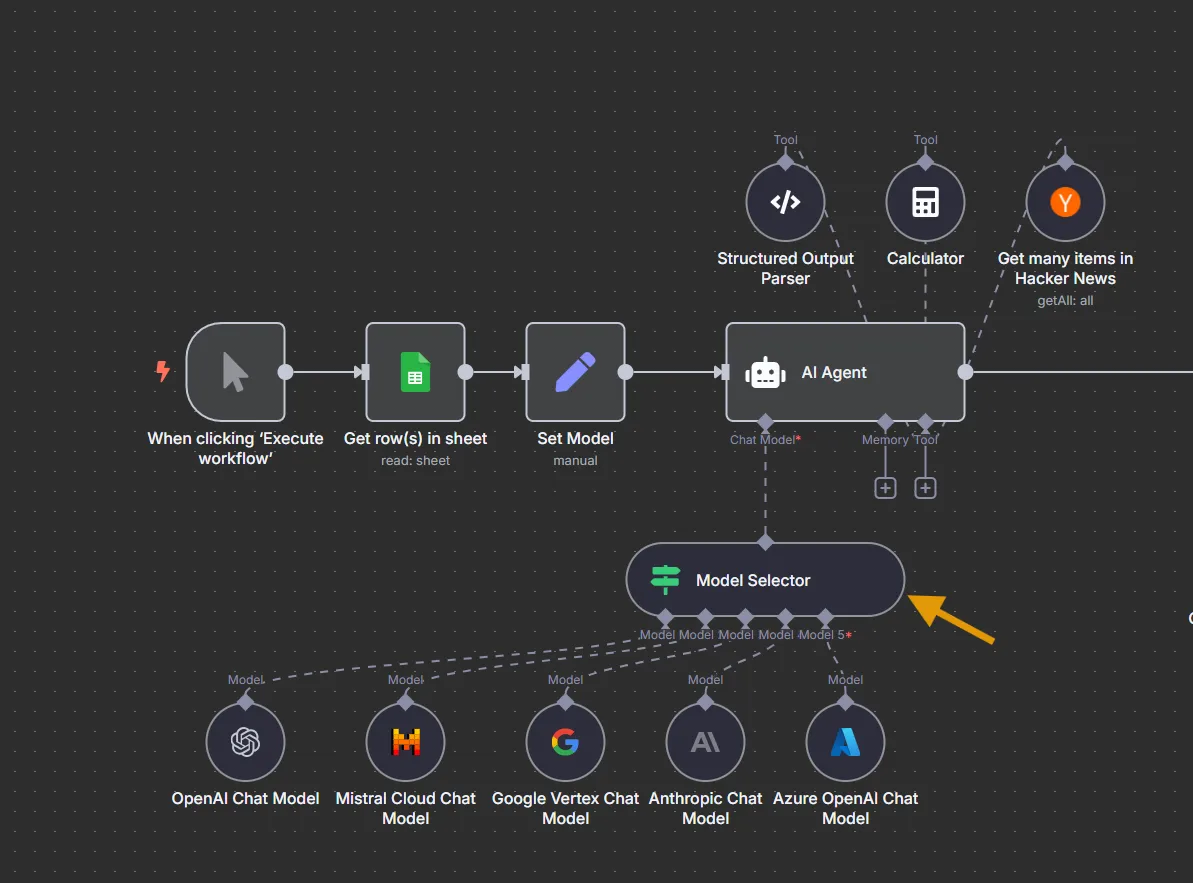
모델 선택기 노드를 사용하면 워크플로우에서 여러 LLM을 작업할 때 더 많은 제어 기능을 얻을 수 있습니다.
표현식이나 전역 변수와 같은 조건에 따라 어떤 연결된 모델이 주어진 입력을 처리해야 하는지 결정하는 데 사용합니다. 이를 통해 성능, 작업 유형, 비용 또는 가용성에 따라 모델을 전환하는 등의 모델 라우팅 전략을 더 쉽게 구현할 수 있습니다.
사용 방법:
여러 모델 노드를 모델 선택기 노드에 연결한 다음, 노드 설정에서 라우팅 조건을 구성합니다.
참고 사항:
- 규칙은 순서대로 평가됩니다. 다른 규칙도 일치할 수 있더라도 첫 번째로 일치하는 규칙이 사용할 모델을 결정합니다.
- 서브 노드로서 표현식은 여기서 다르게 작동합니다: 각 항목에 대해 차례로 해결하는 대신 항상 첫 번째 항목으로 해결됩니다.
모델 선택기 노드는 모델 간 라우팅 로직이 성능, 비용, 가용성 또는 데이터셋별 요구 사항에 따라 조정되어야 하는 평가 또는 프로덕션 시나리오에서 특히 유용합니다.
OIDC(OpenID Connect) 인증 지원
이제 OIDC(OpenID Connect)를 싱글 사인온(SSO)의 인증 방식으로 사용할 수 있습�니다.
이를 통해 기업 팀은 널리 채택되고 쉽게 관리할 수 있는 표준을 사용하여 n8n을 기존 ID 제공업체와 통합할 수 있는 더 많은 유연성을 갖게 됩니다. OIDC는 이제 SAML과 함께 제공되어 기업이 내부 요구 사항에 가장 적합한 것을 선택할 수 있도록 합니다.
프로젝트 관리자가 이제 환경 내에서 Git에 커밋할 수 있습니다
프로젝트 관리자는 이제 환경 기능을 통해 워크플로우 및 자격 증명 변경 사항을 Git에 직접 커밋할 수 있습니다. 이 업데이트는 프로젝트 수준 관리자에게 변경 사항을 커밋하는 직접적인 제어 권한을 부여함으로써 워크플로우 배포 프로세스를 간소화합니다. 또한 워크플로우를 가장 잘 아는 사람들이 인스턴스 수준 관리자의 개입 없이도 직접 업데이트를 검토하고 커밋할 수 있도록 보장합니다.
기능 업데이트
노드 개선
1.104.0 (2025-07-21)
- Anthropic 노드: 새로운 노드 (#17121) (5502361)
- Facebook Graph API 노드: api v23 지원 추가 (#17240) (c0f1867)
- MCP 클라이언트 도구 노드: HTTP 스트리밍 가능 전송 지원 추가 (#15454) (a5d14a2)
- n8n 폼 노드: 폼 완료 메시지의 기본 스타일링 허용 (#17338) (2d4abf1)
- 커뮤니티 노드 업데이트가 있을 경우 NDV 알림 (#17146) (0237d8b)
- 커뮤니티 노드 세부 정보 푸터 업데이트 (#17158) (81cd490)
1.103.0 (2025-07-14)
- AI 에이전트 도구 노드: 에이전트 도구 추가 (#17108) (f67581b)
- Cohere 채팅 모델 노드: Cohere 채팅 모델 노드 추가 (#16888) (c37397c)
- 이메일 트리거(IMAP) 노드: 가져올 새 메일 제한 (#16926) (d1ac292)
- Google Gemini 노드: 새로운 노드 (#16863) (0f59eea)
- n8n 평가 노드: "지표 설정" 작업에 사전 정의된 지표 추가 (#17127) (a34b30a)
1.102.0 (2025-07-07)
- Airtop 노드: 윈도우 목록 API 및 기타 개선 사항 구현 (#16748) (621745e)
- LangChain 노드: LangChain 업그레이드 및 LLM 노드에 대한 프록시 처리 개선 (#16778) (cfe3699)
- Mistral AI 노드: 새로운 노드 (#16631) (c11e4bd)
- MySQL 노드: executeQuery 및 select 작업에 대한 힌트 (#16753) (f2eb386)
- Langchain을 위한 Weaviate Vector Store 노드 (#16856) (4813c01)
1.101.0 (2025-06-30)
코어 개선
1.104.0 (2025-07-21)
1.103.0 (2025-07-14)
1.102.0 (2025-07-07)
1.101.0 (2025-06-30)
- 시간 절약 데이터만 반환하는 새로운 시간별 인사이트 경로 추가 (#16727) (3ba8a84)
- 사용자 테이블에 lastActiveAt 날짜시간 열 추가 (#16488) (92afe03)
- 사용자가 프로젝트에 초대되었을 때 이메일 알림 전송 (#16687) (7e376e0)
에디터 개선
1.104.0 (2025-07-21)
- 실행 중인 평가를 중지하기 위한 "테스트 중지" 버튼 추가 (#17328) (df80673)
- RLC에서 자격 증명 확인을 비활성화하는 옵션 추가 (#17381) (d466d9d)
- 프론트엔드에서 특별 환경 변수를 기능 플래그로 사용 (#17355) (d36abb5)
1.103.0 (2025-07-14)
- 템플릿을 발견하는 새로운 방법 추가 (#17183) (0259c58)
- AI 어시스턴트 버튼을 캔버스 액션 버튼으로 이동 (#16879) (2294c3d)
- 포커스 패널에 올바른 에디터 표시 (#17062) (3aeb622)
1.102.0 (2025-07-07)
- 사용자가 노드 설정 패널에서 검증된 노드를 업데이트할 수 있도록 허용 (#16447) (6edd47d)
- 테이블 뷰에 접기 버튼 추가 (#16993) (d3330b6)
- 로그 뷰 개선 (#16489) (4124b96)
- NDV UI 전면 개편 실험 (#14209) (6ef3841)
- 더 나은 정렬을 위해 그리드 크기를 16px로 업데이트 (#16869) (7ebde66)
- 아이콘을 Lucide 아이콘으로 업데이트 (#16231) (ed2cb3c)
1.101.0 (2025-06-30)
- '새로운 기능' 섹션 및 모달 추가 (#16664) (0b7bca2)
- '새로운 기능' 알림 콜아웃 추가 (#16718) (1934e6f)
- 소스 컨트롤 푸시 모달에 프로젝트 및 소유권별 필터링 구현 (#16551) (254c9d7)
- 캔버스 액션 버튼 스타일 개선 (#16724) (4d211a0)
기타 기능 개선
1.104.0 (2025-07-21)
1.103.0 (2025-07-14)
- OpenAI Embeddings 노드에 HTTP 프록시 지원 추가 (#17173) (232b8f6)
- 스트리밍 응답을 지원하도록 채팅 SDK 업데이트 (#17006) (3edadb5)
1.101.0 (2025-06-30)
- 에이전트 및 기본 체인 llm에 대한 폴백 메커니즘 추가 (#16617) (6408d5a)
- 동일한 폼 경로를 가진 여러 활성 워크플로우 허용 안 함 (#16722) (98b821b)
- 기본 Gemini 모델을 gemini-2.5-flash로 업데이트 (#16651) (3f6eef1)
버그 수정
코어 개선 및 수정
1.104.0 (2025-07-21)
- 이전 버전 호환성을 위해 소스 컨트롤에서 정의되지 않은 워크플로우 소유자 허용 (#17419) (78cb5b6)
- 비 라틴 문자에 대한 객체 저장소 지원 수정 (#17383) (550339e)
- 더 안전한 CSP를 위해 프론트엔드에서 인라인 JS 제거 (#17195) (fc3129e)
1.103.0 (2025-07-14)
- 워크플로우별 인사이트 분석을 워크플로우 이름으로 정렬 가능하도록 개선 (#17184) (d002cc3)
- 빈 OIDC 디스커버리 엔드포인트에 대한 경고 수정 (#17103) (608dcde)
- 비활성화된 Set Metrics 노드 처리 개선 (#17085) (57b914d)
- OAuth 액세스 토큰 업데이트 시 부분 자격 증명만 업데이트 (#17135) (c8b3ac6)
1.102.1 (2025-07-09)
1.102.0 (2025-07-07)
- 태스크 러너에서 두 모드 모두에 동일한 VM 래퍼 적용 (#16872) (af52a0d)
- Pyodide에서 JS 객체 생성자 및 js 모듈에 대한 접근 차단 (#16957) (bde9008)
- 지연 로딩 시 자격 증명 유형 중복 제거 (#16834) (625ae3f)
- N8N_SKIP_AUTH_ON_OAUTH_CALLBACK 평가 수정 (#16944) (945098d)
- 트리거 없는 부모 케이스에서의 부분 실행 수정 (#16833) (585295c)
- 워커 뷰 수정 (#17052) (f817fb4)
- 소스 제어를 무조건 초기화하도록 변경 (#16929) (faea69c)
- 자격 증명 유형 부모 변경 방지 (#16841) (cb1103e)
- 웹훅 요청에서 불필요한 쿠키 제거 (#16736) (830e068)
1.101.1 (2025-07-03)
1.101.0 (2025-06-30)
- 도구에 재시도 메커니즘 추가 (#16667) (9e61d0b)
- Docker용 모듈 경로 해상도에서 디렉토리 수정 (#16725) (892b0d2)
- Windows 시스템 빌드 오류 문제 수정 (#16653) (297d300)
- 사��용자 목록에서 페이지네이션 작동 오류 수정 (#16697) (a6ded1f)
- 폴더를 하위 폴더로 실수로 이동하는 것 방지 (#16808) (22a240e)
- 수동 실행에서 수동 트리거의 기본값 제거 (#16829) (641e970)
- 파일을 찾을 수 없을 때 기본 태그-매핑 및 폴더 값 반환 (#16747) (e163141)
에디터 개선 및 수정
1.104.0 (2025-07-21)
- 크리에이터 CTA에서 닫기 버튼 가시성 개선 (#17405) (8a27563)
- 워크플로우 태그 검색 시 대소문자 구분 없이 검색 가능하도록 개선 (#17347) (4073ce7)
- 채팅 텍스트 영역에서 IME 작성 시 자동 제출 방지 (#17179) (5db8bbd)
- AI 오버라이드 닫기 버튼 위치 재조정 (#17455) (5cf74be)
- 사용자 목록 페이지에 추가 데이터 표시 (#17339) (f3f4461)
- 시간 절약 기능만 활성화된 경우 라이센스 없는 인사이트 대시보드 처리 기능 프론트엔드 업데이트 (#17199) (42c6190)
1.103.0 (2025-07-14)
- 드래그 가능한 필드에서 긴 단어 맞춤 처리 (#17063) (b733573)
- 노드 검색에서 RAG 콜아웃 키보드 탐색 수정 (#17099) (3610748)
- "렌더링" 표시 유형에서 검색 기능 작동하도록 수정 (#16910) (f252a39)
- 프론트엔드 수동 실행 시 성능 이슈 완화 (#17119) (3be5823)
- 서브 워크플로우 노드에서 실패한 실행의 실패 노드 열기 기능 개선 (#17076) (8fff830)
- 평가 기능에서 기능 플래그 제거 (#17107) (59704b4)
- 페이지 크기 변경 후 범위를 벗어난 경우 현재 페이지 재설정 (#17124) (b9e7b71)
1.102.1 (2025-07-09)
1.102.0 (2025-07-07)
- AI Agent가 동일한 뷰에서 여러 실행의 로그 표시 문제 수정 (#16825) (9133340)
- 에디터 작업으로 복사하기 전 오류 상태 초기화 (#16922) (716cb9a)
- Prettier와의 모든 잠재적 eslint 규칙 충돌 비활성화 (#16832) (9517d11)
- 특정 조건에서 리소스 로케이터 드롭다운의 무한 로딩 수정 (#16773) (8e62c80)
- 매핑 필드 아이콘 크기 수정 (#16886) (346bc84)
- 테이블 페이지네이션 상태 처리 수정 및 테스트 추가 (#16986) (34aae96)
- PiP 창에서 JSON 복사 버튼 작동하도록 수정 (#16887) (8fda3fb)
- 노드 설명과 겹쳐도 커넥터를 클릭할 수 있도록 수정 (#16765) (38c2e61)
- 로그인 후에만 새 버전 및 새로운 기능 확인하도록 수정 (#16844) (bbda2da)
- 수동 라이센스 활성화 시 모듈 설정 다시 가져오기 (#16943) (5b9897c)
- 현재 워크플로우인 경우에만 워크플로우 활성화 시 더티 상태 초기화 (#16997) (bb9679c)
- 드래그 중 ESC로 NDV가 닫힐 때 유효한 드래그 상태 복원 (#16758) (7cc5a05)
- Ask AI에서 올바른 오류 메시지 표시 (#16913) (3a733b9)
- json 뷰에서 이스케이프 문자 표시 (#16930) (bd8b7b4)
- 다중 사용자 인스턴스에서만 '나와 공유됨' 표시 (#16770) (29bf4a4)
- 새 워크플로우에서 '워크플로우 저장' 단축키 지원 (#16756) (ffe8fbb)
- 이름이 변경된 노드에 대해 로그 선택 동기화가 작동하지 않는 문제 수정 (#16878) (ee463f0)
- 볼트 아이콘을 채워진 형태로 업데이트 (#16954) (bf926ce)
1.101.1 (2025-07-03)
1.101.0 (2025-06-30)
- 여러 트리거가 있는 활성 워크플로우에서 단일 웹훅이 아닌 트리거 실행 허용 (#16794) (725ce23)
- 이름 변경 중 클릭 시 노드 이름 초기화 방지 (#16755) (a99ccff)
- 프론트엔드에서 인사이트 로딩 수정 (#16677) (28aabd4)
- 새로운 저장되지 않은 워크플로우 공유 수정 (#16740) (5fe68f3)
- 마우스 1번 버튼을 누른 상태에서만 폴더 드래그 가능하도록 수정 (#16809) (c8a7156)
- 커뮤니티 등록 요청 중복 제출 방지 (#16621) (79eef1e)
- 출력 뷰의 자동 크기 조정 제거 (#16672) (e89487f)
- 가로 스크롤을 방지하기 위해 변수 값에 대한 줄 바꿈 재설정 (#16772) (ac46122)
노드 개선 및 수정
1.104.0 (2025-07-21)
- Think Tool 노드: 노드 이름 기반의 동적 도구 이름 사용 (#17364) (ac552e6)
- OpenAI 노드: 라우터에서 오류 처리를 위한 선택적 체이닝 추가 (#17412) (ba9eaca)
- AWS Bedrock Chat Model 노드: 임의 모델 이름에 대한 문제 표시 안 함 (#17079) (5bb5a65)
- Embeddings OpenAI 노드: 사용자 정의 baseURL 설정 시 모델 목록 필터 비활성화 (#17296) (c159e2b)
1.103.0 (2025-07-14)
- AI Agent 노드: 버전 2.1에서 폴백 입력이 추가되는 것 방지 (#17094) (1a4e4c5)
- 서브 워크플로우 실행 노드: 하위 워크플로우의 페어링된 항목 처리 개선 (#17065) (f5fb33a)
- GitHub 노드: 사용자 로딩이 완료되지 않는 문제 수정 (#17122) (336d670)
- Gmail 노드: 사용자가 threadId를 제공할 때만 References와 In-Reply-To 설정 (#16838) (7657cce)
- Linear 노드: 이슈 업데이트 시 우선순위가 잘못 설정되는 문제 수정 (#16764) (ced854d)
- n8n Form 노드: 모바일 화면과 폼 종료 후 리디렉션에서 커스텀 스타일 사용자 정의 가능하도록 개선 (#17060) (878026a)
- Perplexity 노드: 1 미만의 페널티 값 허용 (#17074) (62ea048)
- 감정 분석 노드: 첫 번째 감정 출력 관련 문제 수정 (#17233) (2f7ed14)
- 토큰 분할기 노드: 토크나이저 JSON을 메모리에 캐싱 (#17201) (2402926)
1.102.2 (2025-07-11)
1.101.2 (2025-07-11)
1.102.1 (2025-07-09)
1.102.0 (2025-07-07)
- AI Agent 노드: 대체 메커니즘을 통한 도구 사용 문제 수정 (#16898) (58fd1ec)
- AI_CREDITS_EXPERIMENT 정리 (#16840) (d1d5412)
- EASY_AI_WORKFLOW_EXPERIMENT 정리 (#16839) (3e04566)
- 코드 노드: os.system만 차단하고 import os 차단 해제 (#16885) (e54613f)
- 평가 노드 - 누락된 테스트 기능 및 메서드에 credentialTest 추가 (#16734) (044022f)
- Google Sheets 노드: 모든 헤더 포함 (#16928) (71771a7)
- HTTP 요청 노드: HttpBearerAuth를 사용한 페이지네이션 요청 수정 (#17005) (3b14830)
1.101.1 (2025-07-03)
1.101.0 (2025-06-30)
- 코드 노드: 오류 형식 수정 (#16719) (8f9ce72)
- 실행 데이터 노드: null 값을 빈 문자열로 설정, 실패 시 계속 지원 (#16696) (e6515a2)
- 프로젝트별 소스 컨트롤 자격 증명 필터링 (#16732) (0debbc3)
- 구글 시트 노드: row_number 필드의 잘못된 타입으로 인한 일관성 없는 구글 시트 도구 업데이트 동작 (#16632) (91206ef)
- sendAndWait 액션에 대한 적절한 작업을 설정하는 헬퍼 (#16701) (b70cc94)
- Jira 소프트웨어 노드: 자격 증명 테스트가 올바르게 작동하지 않는 문제 수정 (#16657) (bc53c21)
- Microsoft SharePoint 노드: 액세스 토큰이 새로 고쳐지지 않는 문제 수정 (#16555) (1141553)
- Snowflake 노드: 키-페어 자격 증명 수정 (#16635) (8e6de34)
- 토큰 분할기 노드: 반복적인 콘텐츠에서 tiktoken 차단 방지 (#16769) (c5ec056)
기타 버그 수정
1.104.0 (2025-07-21)
- 제한된 파일 접근 순서 관련 문제 수정 (#17329) (e1805fb)
- 스테이징 환경 확인 시 순서 관련 문제 수정 (#17385) (b8e2187)
- API: 커뮤니티 노드 설치 시 레지스트리에 버전 존재 여부 확인 (#17168) (5180869)
1.101.2 (2025-07-11)
- 마스터 파일과 정렬 (f481c23)
1.102.0 (2025-07-07)
- lintfix 명령 수정 (#17003) (5db122b)
- 웹훅에서 빈 경로 방지 (#16864) (bd69907)
- Posthog로의 원격 측정 이벤트 중단 (#16788) (d76f05b)
- Playwright 바이너리용 설치 단계 추가 (#16945) (05360ce)
1.101.0 (2025-06-30)
성능 개선
코어 최적화
1.103.0 (2025-07-14)
1.102.0 (2025-07-07)
이 내용은 n8n Release Note의 영문 포스트를 우리말로 번역한 내용입니다.
n8n 구축부터 성공적인 워크플로까지 n8n 공식 파트너사 인포그랩과 함께하세요! 지금 문의하기